Premier jour de la PuppetConf 2015
La PuppetConf se tient cette année à Portland et il y a suffisamment de place pour jouer jusqu'à 8 session en parallèle !
Autant dire que le choix n'est pas simple, on ne choisit pas ce qu'on veut voir, on renonce à 7 sessions sur 8. Heureusement, tout arrivera rapidement sur Youtube & Slideshare pour rattraper le retard.
Edit : les vidéos sont disponibles.
Keynote sur DevOps & Puppet
Luke Kanies, CEO & créateur de Puppet, commence la keynote en expliquant à sa manière, le lean, DevOps, l'ops artisanal.

Il situe Puppet comme un élément de coordination de la "software supply chain" : son rôle, faire que tout fonctionne bien dans le meilleur des mondes. Des fois le meilleur des mondes ressemble à des 12 factor apps déployées sur AWS et sans aucun legacy. Mais le vrai monde ressemble souvent à un agrégat de technos de tous ages et de tous horizons : des appliances hors de prix avec des API, des serveurs sous RHEL4 sur un hardware spécifique et des VM modernes voire même du Docker.
Son propos se résume en 3 points :
Tout ce qui n'est pas "native cloud" ne va pas disparaître par magie, soit on gère au mieux, soit on abandonne. L'humain est persévérant donc on essaye d'y faire atterrir des concepts d'Infra As Code, d'infra jetable etc.
La créativité doit se situer dans la phase de design, pas sur la chaîne de production. On fait des super architectures, du super code, du super code Puppet testé, et lorsqu'on part en production, on laisse faire les robots Puppet.
Avec le mouvement DevOps, on rappelle plus directement aux Ops pourquoi ils sont là : pour l'utilisateur final. Tout le monde se moque de savoir si le fichier de configuration d'Apache est géré par Puppet, via un beau sed ou à la main : ce qui compte c'est que ça fonctionne, aille vite, que ça soit fiable et stable etc... On réintroduit une dose de pragmatisme.
On rejoint l'idée du lean de chez Toyota : on corrige le process qui a mené à l’échec, pas la voiture déjà construite.

Keynote sur l'orchestration de topologie applicative
La semaine dernière, PuppetLabs a annoncé "Puppet Application Orchestration". C'est la vraie grosse annonce de la conférence, Puppet veut jouer sur les plate-bandes de capistrano, ansible et tous les progiciels qui veulent nous aider à déployer une topologie applicative en production.
Une topologie applicative repose sur des services, fondations parfaitement gérées par Puppet de nos jours mais l'orchestration entre les différents éléments n'est pas gérée.
Et Puppet a l'avantage d'avoir plus de 3000 modules sur la forge et une communauté qui s'est cassée les dents sur à peu près toutes les stacks applicatives.
On a le droit à une démo live, une vraie, une qui plante ! Mais tout est corrigé en 10 sec : pas de doute, Ryan Coleman sait de quoi il parle.
On commence à voir à travers les slides ce qui change et nous permet de gérer tout ça de manière élégante.
L'idée n'est pas non plus de gérer du code Puppet sur un nœud et se débrouiller pour que tout fonctionne ensemble. Puppet fait un pas en arrière pour avoir une vision de la topologie applicative directement dans le code.
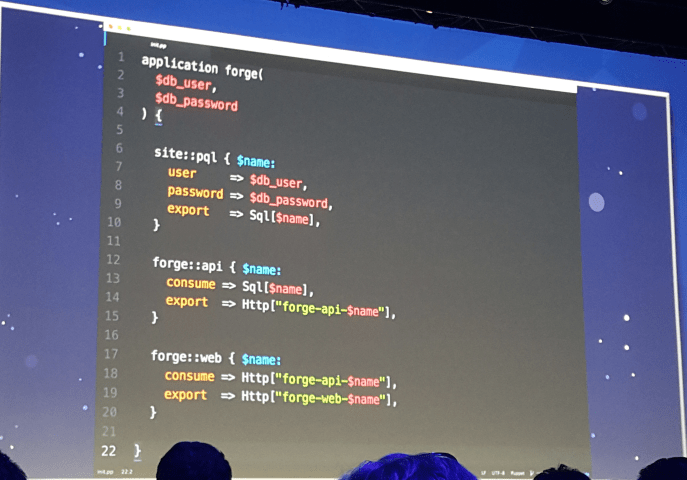
Au lieu d'écrire une classe ou une définition, on a un nouveau type : une application.
Les ressources décrites dedans sont des rôles (au sens pattern role/profile) et peuvent prendre des inputs (rien de nouveau) et des outputs. C'est là, le principal changement, au lieu de sortir des informations à travers les exported resources, on a une notation élégante pour le faire.
Au passage, Ryan en profite pour qualifier de bug d'architecture la nécessité d’exécuter plusieurs fois les agents dans le but avoir une convergence avec les exported resources. Le correctif est là.
Ici, les ressources sont des rôles mais on peut très bien imaginer que ça soit des ressources gérant une appliance F5 de load balancing, un pod ou un service dans Kubernetes.
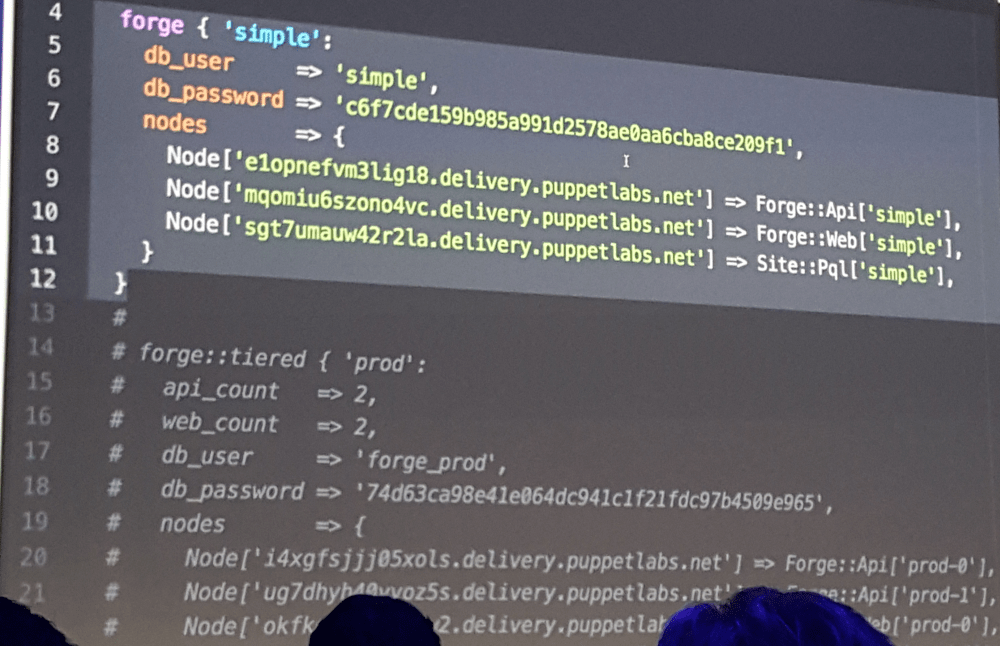
L’élasticité est builtin : augmenter le nombre de serveur d'application en production est désormais l'histoire d'une variable à incrémenter : dans hiera, dans un backend tiers pluggé sur le monitoring ...
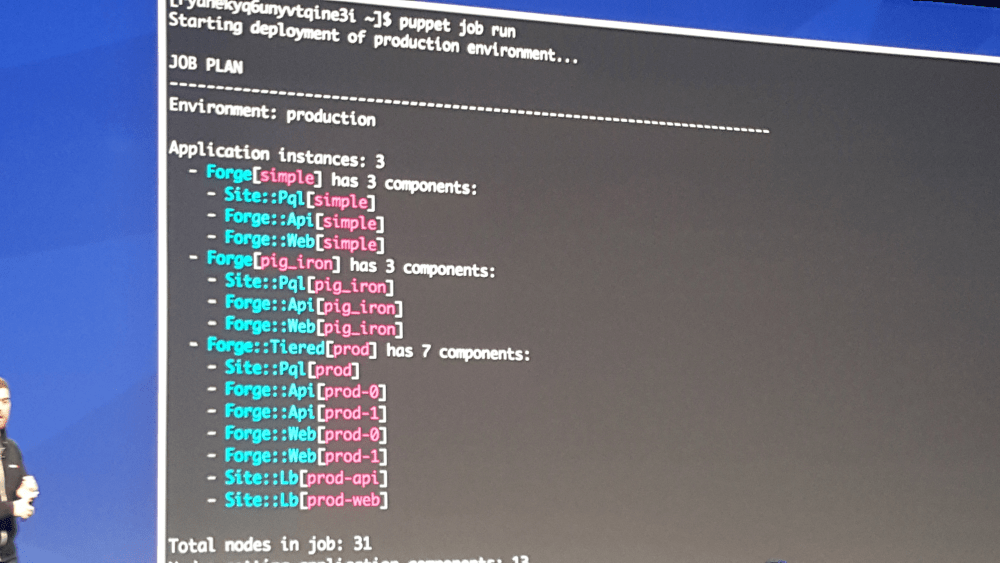
Autre élément intéressant : la commande "puppet job" qui va lancer un run Puppet "coordonné" pour une topologie spécifique. L'idée n'est pas d'attendre 30min que le prochain run Puppet ne se lance ou de lancer un run général sur MCollective : on va lancer un run, dans l'ordre des dépendances sur les noeuds de notre topologie.
Pour résumer :
Sensu + Puppet = le même workflow de dev pour le code Puppet et le monitoring
La présentation est faite par Sean Porter, créateur de sensu.
Il commence avec une définition de l'Infra As Code et en se demandant pourquoi le monitoring ne serait pas traité pareil ?

Un petit résumé de sensu :

Puis vient la partie sur le workflow de dev en lui même : il parle du fait que les reviews de code, ça ne scale pas, que les tests automatisés ne couvrent ni la qualité du code, ni la pertinence des tests aussi bien qu'une review.
Mais l'important ici est de réduire la taille de la boucle de feedback : le temps entre le moment où l'on formule une hypothèse et le moment où notre test la valide ou l'invalide. C'est cette boucle de feedback la plus courte possible qui nous permet d'avancer plus vite. Et dans le monde du monitoring, il est assez compliqué de l'industrialiser sans lancer des alertes de prod en cas d'erreur ...
Le coté très modulaire de sensu permet d'isoler le check : peu importe, ce qui en est fait derrière, ce qui compte c'est qu'en isolation complète, on reste capable de dire si le check fait bien ce qu'il est censé faire.
Venant du monde de Chef, il nous présente un workflow avec test kitchen, Vagrant et Serverspec qui permet à la fois de faire nos tests d'intégration comme on le ferait avec Beaker, mais aussi de tester que dans des conditions normales, nos checks de monitoring sont au vert.
Mais ce qui est marquant ici, c'est le fait de passer par une ressource Puppet classique pour déclarer son check, on rend ainsi la chose aisément testable en test unitaire avec RSpec Puppet !
Primitives of High Availability
Ce talk par Paul Hinze d'Hashicorp (ceux qui font Vagrant, Consul, Packer entre autres) vise à nous expliquer l'importance des abstractions pour travailler sur la haute disponibilité.
Il commence par nous expliquer ce qui se passe sous le capot quand on va sur github.com : le navigateur, html/css, dns, http, tcp, ip, bgp, arp et tant d'autres. Chacun simplifie le travail de l'autre en posant des abstractions sur un système complexe.
Si on veut faire des clusters, il faut faire pareil : créer des abstractions.

L'histoire de la haute dispo en informatique prends ses racines dans la sécurité opérationnelle issue de l'industrie.
L'équation est assez simple : indisponibilité = fréquence d'une panne x durée de la panne
Lors d'une panne sur un train qui entraîne un déraillement : peu importe si le traffic est rétabli en 2 jours ou en 10 minutes, les dégâts sont là et potentiellement catastrophiques. Le focus est donc sur "éviter la panne".
Cela entraîne la création de beaux arbres d'analyse :
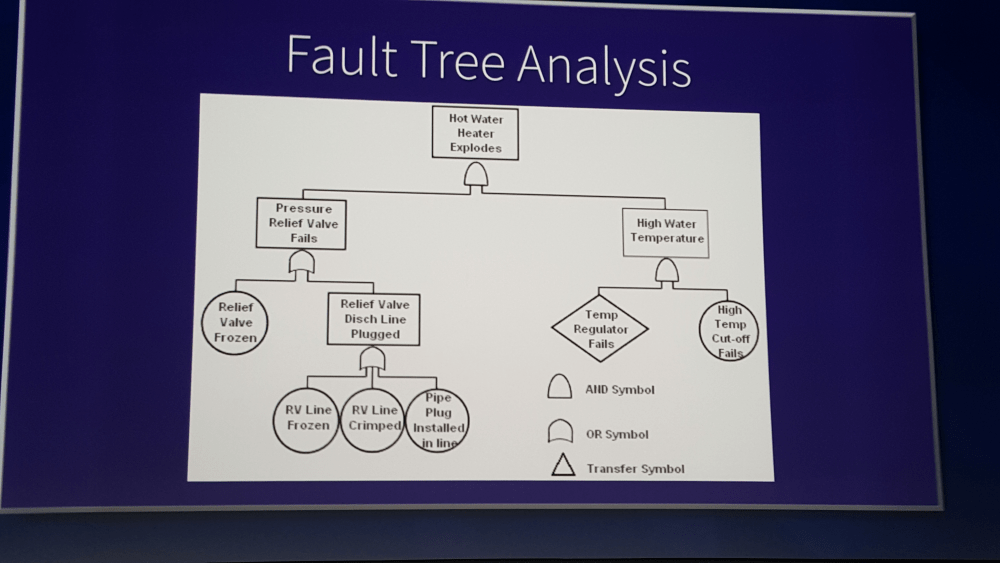
Si on situe l'action coté temps de remise en service, on découvre une autre notion issue de l'industrie, la notion de "spare part closet" : une machine tombe souvent en panne à cause d'une pièce spécifique? On met une armoire à coté avec les pièces détachées prêtes à l'emploi.
Le hardware répond aux pannes les plus courantes en doublant les pièces fragiles : la carte réseau, les disques avec du RAID, l'alimentation. On peut appliquer la même chose au niveau des services en faisant des clusters.
Paul rentre alors dans le détail sur les procédés techniques à notre disposition : ARP pour gérer une vip, synchronisation de la table d'état des connections TCP pour un failover transparent, des actions idempotentes etc.
En résumé, la haute disponibilité = combattre le chaos. Et on ne part pas au combat les mains dans les poches. Il faut connaitre ses limites afin de pouvoir les repousser.

Security, how hard could it be?
Ben d'Etsy nous explique ce qui fait de la sécurité un sujet complexe vu du prisme de l'infrastructure.
Pas vraiment de fil conducteur, plutôt une collection d'exemple pour démontrer à un public peu initié ce qui rends le sujet si complexe :
- un (security) bug bounty en tant que levier de scalabilité des audits de sécurité
- une (des) petite faille qui de fil en aiguille peut servir à une attaque dévastatrice

- la sécurité c'est dur, mais ce n'est pas la seule chose, il faut conserver un certain recul pour faire avancer la sécurité sans passer pour la personne qui interdit tout, tout le temps
- des personnes ont construits de superbes architectures, "Armadillo Security Architecture", avec des tonnes de firewall, 5 pattes réseau par serveur et 250 appliances, puis vient le cloud et l'infrastructure jetable ... alors là c'est la fin du monde

- auditd c'est bien mais les logs produits sont compliqués à manipuler

- docker et sécurité c'est compatible, il faut juste garder à l'esprit que ce n'est pas un hyperviseur et que donc lancer un container en --privileged revient à le faire tourner en root sur l'hôte
- et surtout que curl | sudo sh c'est le mal
Les slides sont déjà dispos :
https://speakerdeck.com/barnbarn/infrastructure-security-how-hard-could-it-be-right
From CLI to Puppet resources in network automation
Ce talk permet de mieux comprendre d'où on part au niveau des équipements réseaux.
Pour Puppetiser ça, le plus simple est de décomposer le système en éléments simples

Pour résumer :
- avant, un outil en ligne de commande pour pousser une configuration
- maintenant, API REST qui se généralisent et/ou ressources natives dans Puppet avec un agent sur l'équipement
- demain, abstraction de l'équipement utilisé à travers le SDN et/ou le module netdev
J'ai eu l'occasion de posé 2 questions :
Comment teste-t-on de façon industrielle que le résultat est conforme aux attentes ?
Puppet fait des actions sur l'API de la vm de test de l’éditeur (arista en l'occurence) et la vérification se fait en faisant un dump/grep de la conf produite : pas de tcpdump avec des grep compliqués
Quel est le positionnement de ce type de module par rapport au SDN ? Cela ressemble à l'automatisation du réseau traditionnel
Le SDN a été vampirisé par le marketing et donc la définition est floue, OpenFlow par exemple revient à exposer la partie électronique (le data plane) de l'équipement via des APIs, tous les clients n'en veulent pas (sic), alors ils ont inventés DirectFlow
DirectFlow = SDN sans controleur et avec des équipements autonomes mais chez un seul vendeur et avec des fonctions réduites.
Pourquoi parle t-on d'un serveur de secrets avec Puppet alors qu'on a Hiera-eyaml? Parce que personne n'en est vraiment satisfait.
L'idée de conjur, c'est de proposer une API REST propre qui va s'occuper du RBAC, de l'auditabilité et de la sécurité au repos et en transit.
Le RBAC est généralement appliqué aux humains. Ici, on l'applique également à des serveurs et à des services (= applications). On va pouvoir définir des règles sur les types de compte qui ont accès à tel ou tel secret. Et on va pouvoir versionner ces règles dans Git.
Le but est de proposer un modèle qui fonctionne sur des archis jetables : on dépose à la création d'une VM un secret permettant de l'identifier lorsqu'elle vient interroger le serveur et lui appliquer les règles adaptées à son rôle.
Comment utiliser ça pour faire du Puppet securisé ? On versionne dans notre code Puppet des références à des secrets et on regarde tout fonctionner en extrayant du Puppet Master l'omniscience de tout les secrets sur un système prévu et outillé pour.
La petite astuce : Puppet gère un fichier avec quelque chose du genre "secret = @conjur('super_secret')", et conjur passe derrière pour faire un beau sed avec le vrai secret sans qu'à aucun moment il ne soit passé dans les mains de Puppet et de son reporting.
Conclusion de la journée
Topologie applicative + monitoring + haute disponibilité + securité + reseau + gestion des secrets = on est loin du Puppet se contentant de gérer un package et un fichier de conf sshd.
Luke (CEO Puppetlabs) a l'ambition de faire de Puppet, la "lingua franca" du datacenter, si cela n'est pas encore le cas, forcé de constater que les sessions montrent qu'on s'en approche. Même si Puppet arrive peut être un peu tard par rapport à Ansible sur les topologies applicatives, il conserve un coup d'avance sur l'intégration au SI traditionnel.