La Gross Conf 2024 - Piloter l'incertitude en MLOps
Article écrit par Jérôme Lambert et validé par Sofia Calcagno.
Sofia, ML Engineer chez OCTO Technology, nous propose d’explorer le pilotage de l’incertitude dans un projet de MLOps. Cette exploration va se faire à travers le cas fictif d’un journal, “Le Panda Enchaîné”, et les stratégies qu’il est possible de mettre en place pour à la fois réduire l’incertitude et augmenter le retour sur investissement (ROI). Commençons par poser le cadre à travers une discussion entre Sofia et un client :
- Le client : “Sofia, j'ai envie de mettre du machine learning dans mon produit, comment je fais ?"
- Sofia : "Est-ce que tu as déjà mis une règle de gestion simple en production ?"
- Le client : "Sofia, je ne veux pas mettre une règle de gestion simple, je veux faire du machine learning !"
- Sofia : "Ne t'inquiète pas j'ai compris. Commençons par discuter incertitude et ROI".
L'incertitude dans le ML : un paysage à deux dimensions
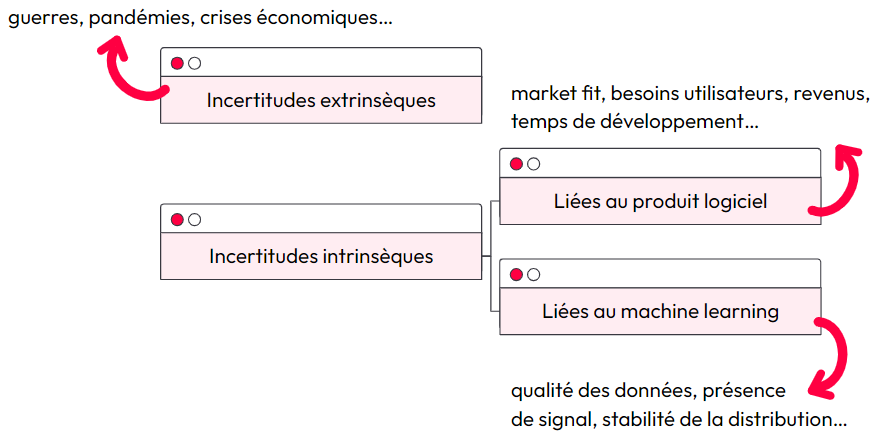
Sofia présente la notion d'incertitude en ML selon la dichotomie suivante :
- L'incertitude extrinsèque, qui échappe à notre contrôle comme les changements de comportement des consommateurs,
- L'incertitude intrinsèque, directement liée à notre produit et pouvant être subdivisée en incertitudes liées au logiciel et au ML. Ces dernières concernent des aspects comme la stabilité des données et leur évolution.
Le cas fictif du Panda Enchaîné : une illustration pratique
Le journal Le Panda Enchaîné souhaite augmenter les revenus grâce à la publicité vue par les lecteurs. Ainsi, plus les lecteurs lisent des articles, plus ils voient de la publicité. L’objectif secret de Sofia est de faire rater la sortie de métro aux lecteurs car trop captivés par l’article qu’ils sont en train de lire. Sofia nous présente trois plans visant à atteindre l’objectif fixé : :
- Le statu quo : Aucune recommandation n'est proposée, anticipant des coûts stables mais un risque d'érosion des revenus face à la concurrence.
- L'heuristique : Une règle simple est mise en œuvre, initialement efficace mais pouvant conduire à un "arbre de la mort" par complexification excessive.
- Le modèle ML : Privilégier un modèle de ML, malgré un coût initial élevé et une phase de développement sans revenu, dans l'espoir d'un accroissement des revenus à la mise en production.
Le statu quo
Rester dans l'inaction, à travers le statu quo, s’avère être une stratégie coûteuse car impliquant de renoncer à des opportunités. Dans le cadre du Panda Enchaîné, le coût d’opportunité de cette non-action peut se traduire par une perte des lecteurs car aucune recommandation de lecture ne leur sera proposée.
Nous allons voir dans les deux paragraphes suivants, les options qui s’offrent à nous pour investir dans les recommandations.
L’heuristique
L’heuristique consiste à coder une règle simple qui va ressembler à un arbre de décision. Pour Le Panda Enchaîné, la première règle pourrait être la suivante : "si l'article est dans le top 5, je le recommande".
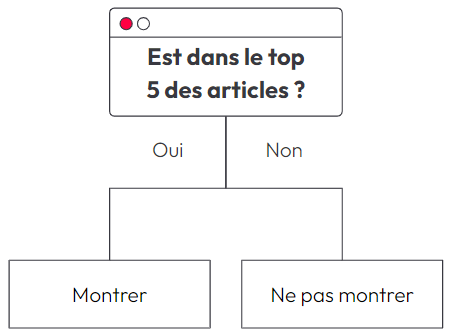
Facile, non ? Pas tant que ça...
Si le système fonctionne bien, on va vouloir l'étendre. C'est alors que les complications vont apparaître : l'arbre de décision devient vite gigantesque, avec de nombreuses conditions "IF ceci THEN cela". Un vrai "arbre de la mort” !
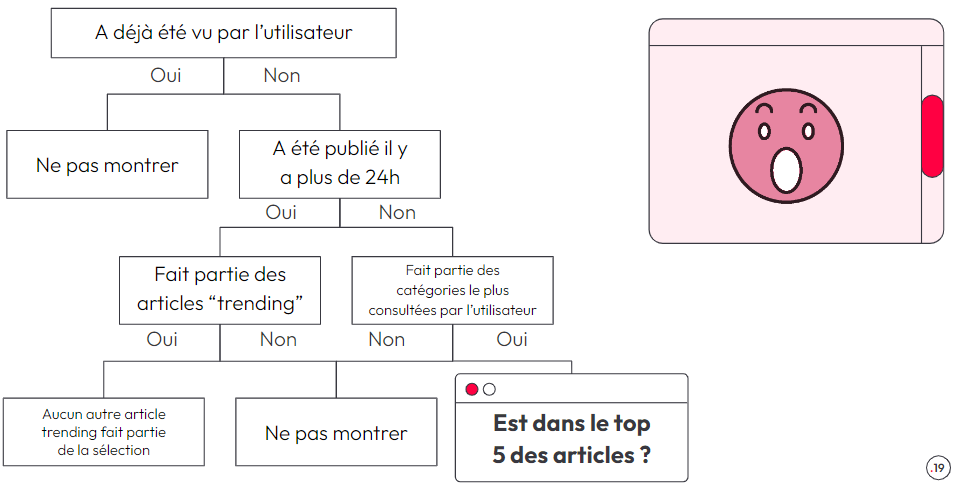
Du point de vue des coûts, ils vont être faibles au début mais vont exploser par la suite : faire évoluer l’arbre de la mort devient très difficile et coûteux : on est donc paralysé.
En clair, cette solution est bancale. Pas assez flexible, trop difficile à maintenir, et pas vraiment évolutive.
Le modèle ML
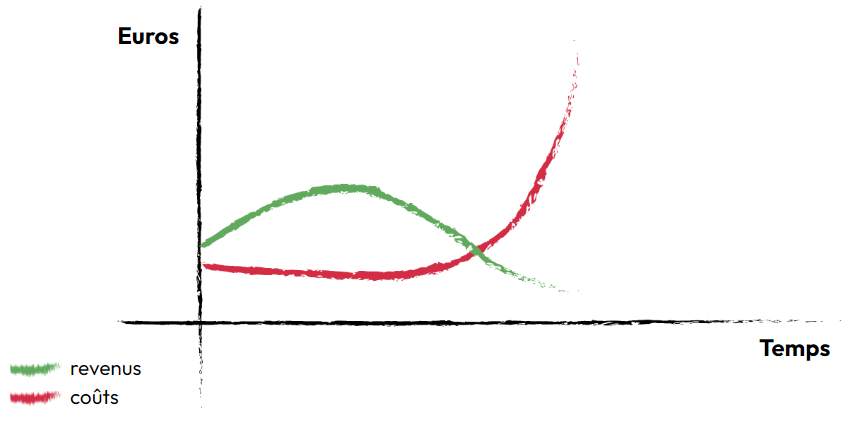
Avant de se lancer dans l’explication et la mise en place d’un modèle ML, Sofia nous rappelle la 3e règle du ML : “privilégiez le machine learning à une méthode heuristique complexe”. Cette règle met en avant que lorsque vous utilisez des heuristiques complexes, celles-ci deviennent très difficiles à gérer. Vous avez alors intérêt à explorer l’utilisation du ML. Un article de 2015, intitulé "Hidden technical debt in machine learning systems", soulève un point crucial sur l’utilisation du ML : le code ML ne représente qu'une infime partie d'un système complet. L'infrastructure, le déploiement et la maintenance constituent des éléments clés, souvent négligés, qui peuvent générer une "dette technique" invisible. En termes de coûts et de bénéfices, voici un scénario plausible avec les 4 étapes illustrées dans le schéma ci-dessous :
- Coûts CAPEX : Investissement initial dans le développement du modèle par des data scientists.
- Pas de revenus immédiats : La phase de développement ne génère aucun revenu.
- Déploiement en production : Espoir d'une augmentation des revenus.
- Découverte des réalités de la production : Risque de surcharge du système, de dégradation de la pertinence des recommandations et de nécessité de ré-entraînement du modèle.
Résultat : On se retrouve dans une impasse, avec un modèle qui ne répond pas aux attentes et un investissement initial qui semble gaspillé. 
Comment mieux faire diminuer l’incertitude ?
Sofia propose une approche méthodologique en trois étapes permettant de faire les bons choix. 1. Définir les questions clés et prioriser les incertitudes
- Les utilisateurs veulent-ils des recommandations ?
- Est-il possible de faire un modèle de ML pour faire des recommandations ?
- Comment intégrer mon algorithme dans mon infrastructure ?
Sofia nous rappelle que le modèle de machine learning le plus frugal est celui que l'on ne fait pas. 2. Mesurer l'impact en production L'impact des recommandations doit être mesuré par des indicateurs métier, tels que l'augmentation des revenus ou, si ceux-ci sont difficiles à évaluer directement, par des proxys comme le nombre d'articles lus. Cette mesure permet de naviguer efficacement dès le début du projet. Mesurer l’impact business en production va permettre de s’assurer que le modèle de ML répond aux attentes des utilisateurs. Exemple du cas de figure redouté :
- La performance de l’algorithme, selon les métriques de ML, est excellente
- Les utilisateurs se détournent malgré du journal car ont le sentiment d’être espionnés par l’algorithme
3. Combiner heuristique et machine learning Finalement, la meilleure solution serait de combiner l’heuristique avec le machine learning. Commencez par mettre en place une heuristique simple et mesurez son efficacité en production. Le monitoring est ici une pièce maîtresse de votre système en production. Si les résultats de cette heuristique sont concluants, alors vous pourrez procéder au lancement d'un modèle de machine learning pour optimiser davantage les performances. Pour évaluer l'efficacité relative de l'heuristique par rapport au modèle de machine learning, vous pourrez utiliser différentes techniques qui vous permettront une comparaison directe entre les deux approches :
- Shadow production : technique consistant à mettre en production (mais pas en service) un modèle ML afin de le tester son comportement dans l’environnement cible sans qu’il soit exposé aux utilisateurs
- A/B testing : cette technique permet de comparer en production, et en service, deux versions différentes de notre journal Le Panda Enchaîné. Une partie des lecteurs seraient exposés à une heuristique et une autre partie au modèle ML. Ainsi, nous pourrions évaluer la performance et la pertinence de chacune des approches.
Conclusion et takeaways
Sofia nous encourage à adopter une approche itérative et pragmatique pour réduire les risques et maximiser les chances de succès d'un projet de machine learning. Elle souligne également l’importance de savoir arrêter un projet s’il ne fonctionne pas, et ainsi stopper les pertes.
Takeaways :
- S’attaquer à l'incertitude va nous permettre de prendre de meilleure décision
- Toutes les incertitudes ne se valent pas : commencez par lever les incertitudes les plus structurantes
- Les indicateurs métier se mesurent en production
- Pouvoir aller en production à la demande permet de lever les incertitudes tout au long du delivery
Pour aller plus loin, nous vous conseillons la lecture de son livre "Culture ML Ops".