Nouveautés de la base NoSQL Apache Cassandra 1.2
Introduction
A OCTO, nous suivons depuis quelques années déjà l’évolution de la base NoSQL Apache Cassandra. La sortie de la version 1.2 en janvier 2013 nous donne l’occasion de faire le tour d’horizon des évolutions récentes du produit. En résumé, on observe récemment une amélioration de l’expérience d’utilisation de Cassandra grâce à une simplification de la modélisation des données, du requêtage et de l’administration pour les opérationnels. Le tout en gardant les fondamentaux de la solution à savoir les performances, la disponibilité et la scalabilité.
Principales nouveautés de la version 1.2
Virtual nodes
Chaque nœud du cluster est désormais responsable de plusieurs « range » d’identifiants dans l’anneau qui décrit la répartition des données dans le cluster. Tout se passe comme si un nœud physique hébergeait plusieurs nœuds Cassandra virtuel. Cette fonctionnalité est très importante car elle simplifie grandement la vie des opérationnels de Cassandra. Faire grandir un cluster devient plus facile, le balancing se fait de manière plus équilibrée.
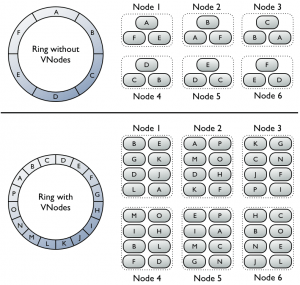
(crédit Datastax.com)
Sur cette illustration, sans la fonctionnalité des nœuds virtuels (schéma du haut), chacun des 6 nœuds est responsable d’un segment (« range ») des données, ou plus précisément 3 en supposant un facteur de réplication de 3. Avec les vnodes (schéma du bas), chacun des 6 nœuds est responsable de 2 ou 3 segments (configurable, par nœud), qui après réplication font que tous les nœuds ont les données de 8 segments de l’anneau.
En bonus, la configuration du nombre de ranges par nœud fait qu’il possible de définir des nœuds avec plus ou moins de données ce qui est utile en cas de caractéristiques système différentes.
Ajouter un nœud dans le cluster est également beaucoup plus rapide, car désormais davantage de nœuds du cluster peuvent envoyer les données nécessaires à l’initialisation du nouveau nœud.
Par défaut, pour des soucis de compatibilité, la fonctionnalité est désactivée (chaque nœud n’assume qu’une seul range).
Amélioration de CQL
Le Cassandra Query Langage passe en version 3 et opère un rapprochement supplémentaire vers le SQL. Les requêtes Create, Select, Update, etc. semblent désormais plus familières. CREATE TABLE user_profiles ( key text PRIMARY KEY, first_name text, last_name text, year_of_birth int ) WITH COMPACT STORAGE SELECT * FROM seen_ships WHERE day='199-A/4' AND time_seen > '7943-02-03' AND time_seen < '7943-02-28' LIMIT 12;
Cette évolution du langage de requêtage est très importante puisque elle réduit la barrière à l’entrée pour les nouveaux utilisateurs de cette base NoSQL. Cependant Cassandra n’implémente qu’un sous ensemble de SQL, et CQL reste orienté ‘real time’ : pas de jointure possible, pas de group by, support de « LIMIT » et « ORDER BY » limité, pas de sous requête. Les traitements les plus lourds continuent de se faire à travers l’intégration avec Hadoop MapReduce, Hive et Pig.
Support des « collections »
La valeur des colonnes peut désormais être un set, une map ou une liste. Cet ajout de nouveaux types enrichit et simplifie la modélisation des données. Les requêtes CQL suivantes sont désormais valides : cqlsh> INSERT INTO users (user_id, first_name, last_name, emails) VALUES('frodo', 'Frodo', 'Baggins', {'[f@baggins.com](mailto:f@baggins.com)', '[baggins@gmail.com](mailto:baggins@gmail.com)'}); cqlsh> UPDATE users SET emails = emails + {'[fb@friendsofmordor.org](mailto:fb@friendsofmordor.org)'} WHERE user_id = 'frodo';
Tracing des requetes
Cette fonctionnalité est similaire au mot clé SQL « Explain ». Le tracing d’une requête CQL permet d’afficher le plan d’exécution de la requête : quels nœuds sont impliqués, quelles opérations sont effectuées, combien de temps elles ont pris etc. Cette fonctionnalité est très puissante pour essayer de comprendre un éventuel problème de performance avec une requête.
Atomic batch
On peut depuis la version 1.2 définir des batchs (groupe d’opérations) atomique dont on a la garantie qu’ils vont être déroulés entièrement même si le coordinateur (nœud qui reçoit la requête du client, ici le batch) meurt en court de route. Pour cela une nouvelle structure de données est introduite, le batch log, répartie sur tous les nœuds du cluster. Le coordinateur ne retourne l’acquittement au client que si tout le batch a été écrit dans le batch log. Dès lors, même si le coordinateur plante avant que tout le batch n’ai été joué, le batch log (qui est réparti sur tous les nœuds) s’occupe de la reprise sur erreur. Les atomic batch sont atomiques mais pas isolés, si l'écriture est partielle (le coordinateur plante au milieu), les clients voient l'écriture partielle tant que le batch log n'a pas été rejoué entièrement. La garantie est qu’à terme, (eventually_)_ tout le batch sera joué.
Off head bloom filters
D’après J.Ellis (lead du projet Apache Cassandra), une JVM classique commence à peiner à partir de 8Gb de heap. Les filtres de Bloom sont une structure de données très utilisée par CASSANDRA et qui occupent 1 à 2 Go en heap par milliard de lignes de données. Avec la version 1.2, les filtres de Bloom sont stockés « off heap » pour soulager la JVM. De même pour les méta données de compression (20 Gb par Tera). Ainsi la capacité de Cassandra à gérer de très gros volumes par nœud est accrue (jusqu’à 3 To par nœud, sans problème).
Comportement en cas de défaillance disque
Avec CASSANDRA des disques durs en RAID ne sont pas nécessaires puisque la réplication des données est assurée par le logiciel. Depuis la version 1.2, il est désormais possible de choisir le mode de dégradation souhaité quand un nœud CASSANDRA détecte qu’un de ses disques durs est défaillant. Le nœud peut, au choix, complétement se retirer du cluster (suicide) et être marqué comme indisponible (configuration par défaut) ou alors le nœud peut continuer d’opérer avec des erreurs potentielles au moment où il faudra lire/écrire sur le disque dur défaillant.
Changements de schéma concurrents
Il est désormais possible d’exécuter des requêtes du type « alter columnfamily [...]» et « create columnfamily […] » depuis n’importe quel nœud du cluster, de manière concurrente. Avant Cassandra 1.2, un verrou global était posé et il fallait attendre une fraction de seconde entre les « alter/create » pour que la propagation de schéma converge sur tous les nœuds et éviter un conflit.
Principales nouveautés de la version 1.1
Isolation par lignes
Depuis la version 1.1 une requête du type « UPDATE Users SET login='trololo' AND password='mypass' WHERE key=’655440000' » est traitée de manière isolée. Si un client lit la ligne en même temps qu’elle est mise à jour, il voit soit la version complétement non mise à jour, soit la version complétement mise à jour (les 2 champs password et login). Précédemment, il était possible qu’un enregistrement soit retourné avec seulement une des 2 colonnes mise à jour.
Amélioration sur le « Row Cache » (cache des données)
Avant la version 1.1, la configuration du volume de données (exprimé en nombre de lignes a.k.a enregistrements) à conserver en cache se faisait column family (CF) par column family. Le tuning était complexe puisque la relation entre le nombre de lignes et la taille en RAM n’est pas immédiate et que de plus la configuration se faisait CF par CF. Désormais, il faut spécifier combien d’espace RAM (en Mo) il faut allouer pour le « row cache » au total et Cassandra s’occupe de répartir au mieux entre les différentes CF, en fonction des patterns d’accès.
Support de stockage configurable
Il est désormais possible de spécifier sur quels disques durs doivent être stockées telle ou telle famille de colonnes. Cela permet, par exemple, de stocker les parties de données qui ont des fortes contraintes de latence sur des disques SSD tandis que les données très volumineuses sont persistées sur des disques durs mécaniques.
Utilitaire simple d’import/export des données
Cassandra comprend désormais les commandes « COPY FROM » et « COPY TO » depuis le shell Cassandra (cqlsh). Ces commandes permettent l’import et l’export de données au format CSV ce qui peut être utile pour transférer simplement quelques dizaines de Go.
Evolutions à suivre
La version 2 de Cassandra, dont le développement vient de commencer et qui devrait sortir dans 6 à 8 mois apportera d’importantes nouveautés. La roadmap est bien remplie avec le support des triggers, une refonte des compteurs distribués, du sharding pour les « lignes larges » (enregistrements avec plus de 2 milliards de colonnes), des fonctions d’aggrégats (moyenne, somme, max, etc.) pour CQL ou encore une amélioration sur le processus de défragmentation (« compaction ») des données.