Mise en place d'une architecture événementielle reposant sur Esper
Notre objectif est de mettre en place une architecture, reposant sur le moteur CEP Esper, permettant de traiter le plus d'événements possible. L'intérêt de notre plateforme est d’agréger des informations multiples (infra, applicatifs, etc.) afin de faire remonter des alertes lorsque certaines corrélations d’événements interviennent. Les enjeux de l'architecture sont dès lors multiples :
- acquisition des données
- architecture événementielle et réactive
- utilisation et analyse de contextes historiques
- définition de règles qui permettent de déclencher des alertes grâce à un moteur CEP
Nous présenterons dans cet article différentes architectures mises en place autour du moteur CEP Esper dont l'objectif est de traiter un maximum d'événements. Nous commencerons par faire une rapide introduction à Esper, puis nous vous présenterons les architectures qui ont été implémentées et enfin nous ferons un bilan de nos expérimentations.
Esper
Le moteur CEP utilisé est Esper, édité par EsperTech. C’est une plateforme Java dédiée au CEP et au traitement de flux d’événements. C’est une collection de frameworks et d’outils servant à construire et intégrer des applications orientées événements. Esper représente à l'heure actuelle l'une des solutions CEP Open Source les plus mature.
L’implémentation des règles de traitement des événements se fait via un langage de requêtage, proche du SQL, appelé EPL (Event Processing Language), qui permet de requêter le flux d'événements. En effet, plutôt que de requêter sur des données historiques comme dans une base de données classique, avec Esper nous requêtons le flux d'événements sur une fenêtre de temps donnée. Pour plus de détails sur le fonctionnement d'Esper, vous pouvez consultez les articles suivants :
- Un premier article de Thomas Vial dresse un tour d'horizon de l'écosystème de la solution Esper
- Un deuxième article de Nicolas Salmon présente le framework en implémentant un cas d'utilisation
- Et enfin pour en apprendre plus sur la notion de moteur CEP, nous vous invitons à consulter l'article de Karim Ben Othman et celui de Mathieu Despriee
Le cas d'utilisation
Le cas d'utilisation utilisé tout au long de l'article appartient au domaine de la finance. Il s'agit de calculer la volatilité d'une ou plusieurs actions au fil de l'eau. La volatilité est la mesure de l'ampleur des variations d'une action. Lorsque la volatilité est importante, émettre des ordres boursier devient très risqué. Pour ce cas d'utilisation Esper est très adapté, car il s'agit de traiter un grand nombre d'événements au fil de l'eau avec une latence très faible. Ce dernier va donc nous permettre de monter des alertes lorsqu'un certain seuil de volatilité est atteint.
L'architecture mise en place
Description
L’architecture est composée de 4 éléments. "Transport entrée" et l'application Esper représentent l'architecture testée. Les injecteurs, "transport sortie" et le collecteur ne sont là que pour tester la performance de l'architecture.
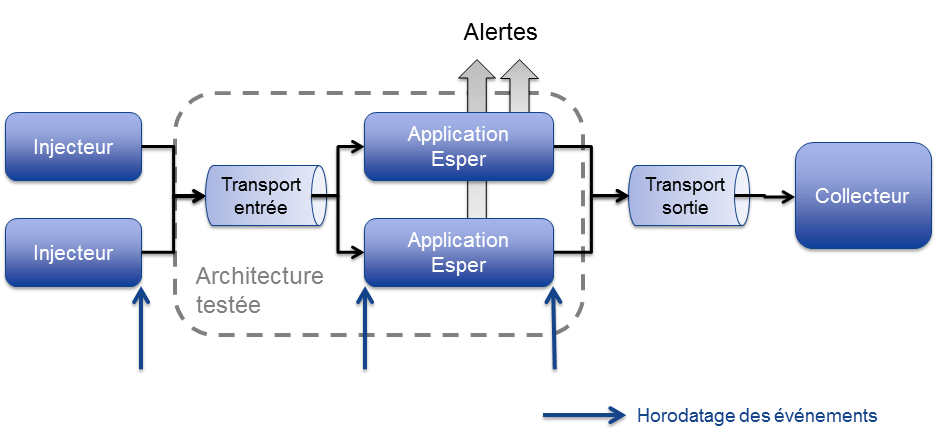
L’injecteur
L’injecteur simule la génération des événements et les envoie au moteur CEP. Voici le type d'événement généré par l'injecteur : nom_de_l'action;valeur_de_l'action;temps_de_création par exemple : octo;10.4;83993040
Application Esper
Ce module traite les événements par le biais du moteur CEP, puis les envoie au collecteur. Sur le schéma on peut voir deux blocs Application Esper, nous allons le voir dans le suite de l'article, mais le fait d'en avoir deux va nous permettre de répartir le charge. Nous avons toujours utilisé la même règle EPL pour nos tests à savoir le calcul de la volatilité : select stddev from ActionEvent(id='octo').win:time(10sec).stat:uni(spot) Ce module ajoute également deux horodatages à l'événement en entrée pour pouvoir mesurer le temps de traitement du moteur Esper. L'événement devient : nom_de_la_valeur;valeur;temps_de_création;temps_arrivé_moteur_esper;temps_sortie_moteur_esper par exemple : octo;10.4;83993040;83993050;83993060
Le collecteur
Le collecteur récupère les événements traités et les trace dans un fichier CSV. Ce fichier est ensuite traité à froid par un programme créé pour analyser les métriques de performance (débit et latence) du moteur CEP et plus globalement de la plateforme.
L’horodatage
Pour pouvoir mesurer les performances de l’architecture et surtout du moteur, il faut avoir accès au temps de parcours de l'événement dans chaque élément de la plateforme. Un horodatage est donc greffé à l’événement à l’entrée et la sortie de chaque brique.
Tests réalisées
L'objectif est donc d'injecter le plus d'événements possible à l'application Esper pour mesurer les performances d'Esper. La démarche a donc été d'abord de tester le moteur en générant les événements depuis l'application Esper, les chiffres que l'on obtient avec ce test représentent le débit maximum atteignable. Il ne sera en effet pas possible d'injecter plus d'événements qu'une boucle while au sein de l'application elle même. Ensuite, nous avons changé le type de transport permettant d'acheminer les messages depuis l'injecteur vers l'application Esper. Il est important de noter que la solution qui sera retenue sera celle qui maximisera le débit d'événements injectés au moteur Esper.
Chaque élément de la plateforme est installé dans une machine virtuelle Amazon indépendante de type Large, c'est à dire avec 8Go de Ram, un processeur de deux coeurs, et une bande passante de 45Mo/s entre deux machine EC2.
Mode standalone
Le mode standalone représente le débit maximum d'événements traités par l'application Esper. En effet, seule l'application Esper est lancée. Cette dernière instancie le strict minimum pour faire fonctionner le moteur CEP. Elle crée les événements elle-même et les injecte au moteur. Pour pouvoir utiliser au maximum les capactités de la machine, deux threads injecteurs ont été créés.
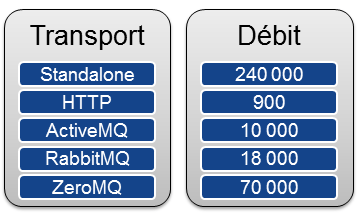
Nous avons atteint un débit de 240 000 événements par seconde.
Mode HTTP
En utilisant HTTP pour injecter les événements, nous avons constaté un débit moyen de 900 événements par seconde, ce qui est très loin de la capacité de 240 000 événements par seconde du moteur. Ce débit reste faible en comparaison des autres transports testés. C’est pourquoi cette solution a rapidement été laissée de côté.
Nous aurions pu augmenter le débit en utilisant le keep-alive de HTTP. En effet, dans le cas précédent, il faut à chaque fois rétablir la connexion entre le serveur et le client. Comme les autres transports que nous allons voir dans la suite de l'article sont beaucoup plus performants que HTTP (sans keep-alive), nous avons décidé de ne pas consacrer plus de temps sur HTTP.
Mode ActiveMQ & RabbitMQ
Nous avons effectué des tests en remplaçant HTTP par ActiveMQ (son protocole OpenWire), puis dans un second temps par RabbitMQ (son protocole AMQP).
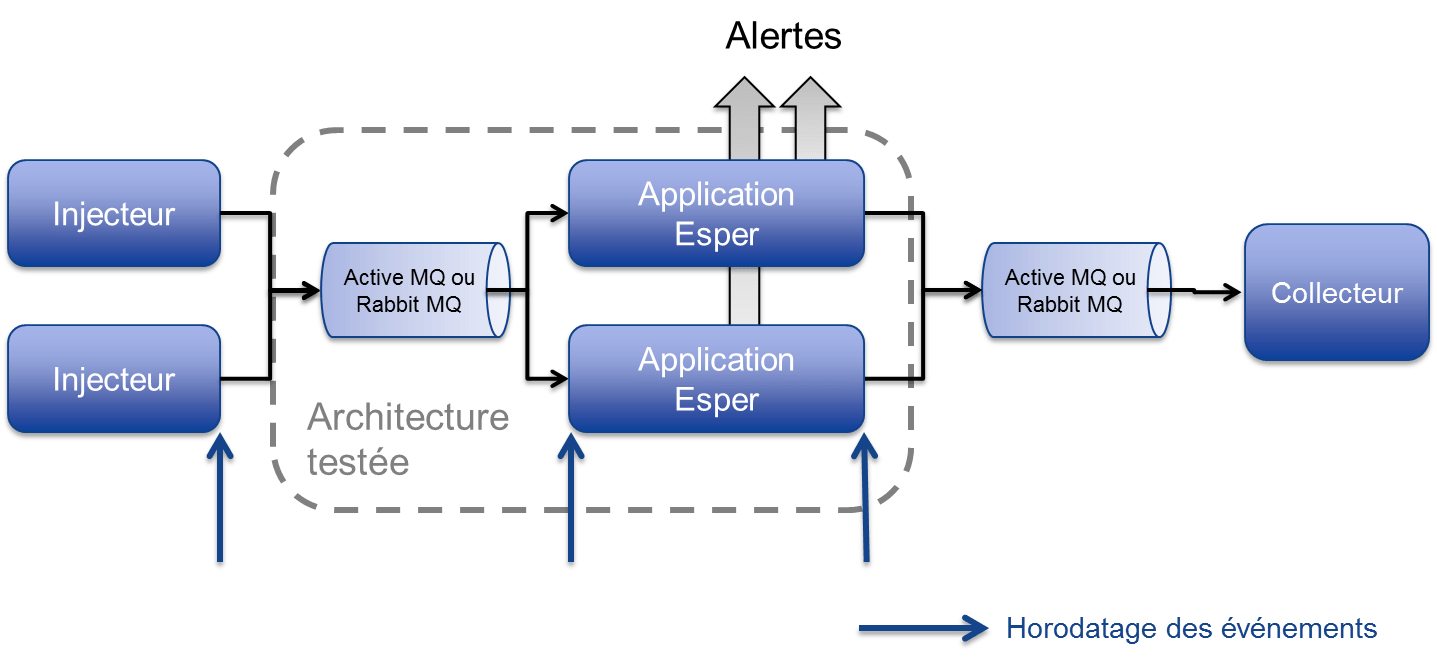
Remarques :
- Chaque élément de la plateforme est installé dans une machine virtuelle Amazon propre.
- Nous avons commencé par faire le test avec ActiveMQ et nous avons obtenu 10 000 événements injectés par seconde.
- Ensuite nous avons testé RabbitMQ qui nous a permis d'atteindre 18 000 événements par seconde.
- ActiveMQ et RabbitMQ ont été utilisés avec des configurations plutôt basiques. Voir section suivante
Tuning ActiveMQ
Avant de parler des optimisations qui ont été effectué il est important de comprendre la notion de prefetch. ActiveMQ utilise une limite de prefetch sur le nombre de messages qui peuvent être accumulés par le consommateur. En effet, le prefetch permet de récupérer les messages par batchs plutôt que unitairement. La première optimisation a donc été d'augmenter la taille de prefetch pour augmenter le débit d'événement. Ensuite, nous avons remplacé le paramètre AUTO_ACKNOWLEDGE par DUPS_OK_ACKNOWLEDGE. AUTO_ACKNOWLEDGE atteste de la réception à chaque nouveau message, alors que DUPS_OK_ACKNOWLEDGE attend de recevoir 50% du prefetch pour attester le tout. Toutes ces optimisations nous ont permis de gagner 2 000 événements par secondes.
Tuning RabbitMQ
Tout d’abord le fait d’utiliser la version 2.8.1 plutôt que la 2.7.1 de RabbitMQ nous a permis d'augmenter les performances de la plateforme. Ensuite, le fait d’attester les messages automatiquement grâce à l’option AutoAck permet un gain en performance non négligeable de plusieurs milliers d’événements.
Remarque concernant le routage avec RabbitMQ
Les capacités de routage des messages avec AMQP nous paraissaient intéressantes afin de partitioner le flux d’événements. Cependant c’est le consommateur des files de message qui doit configurer le filtrage des messages en choisissant le type de message qu'il souhaite recevoir, par exemple tous les messages de type Octo et de type Michelin. Ceci nous paraît peu intéressant dans notre architecture. En effet, cela nécessite que chaque consommateur connaisse a priori l’ensemble des clés de routage car deux messages possédant la même clé de routage ne doivent pas finir sur deux instances d'Esper différentes. De plus, cela implique qu'à chaque ajout d'une nouvelle instance, il faudrait reconfigurer toutes les autres instances déjà en place pour répartir la charge.
Mode ZeroMQ
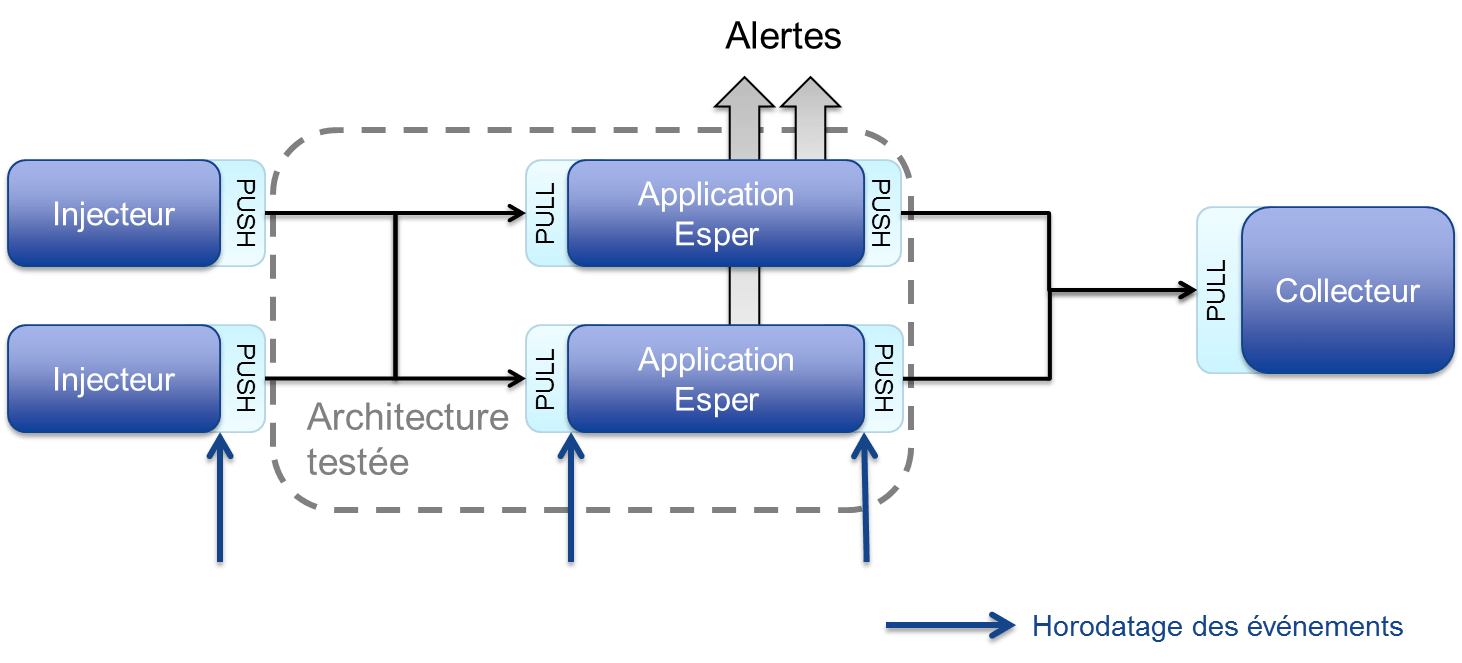
Avantages de ZeroMQ
Premièrement, ZeroMQ est très simple à utiliser. Par rapport à la programmation socket classique, quelques lignes suffisent pour mettre en place la configuration d’une connexion, le tout restant facile à relire et à comprendre. Deuxièmement ZeroMQ est très performant. Ceci peut paraitre surprenant, mais ZeroMQ peut être plus rapide qu'avec l'utilisation de sockets TCP classiques, il crée ses propres threads pour gérer ses connexions, et intègre d'autres optimisations. Troisièmement, il nous a permis de nous passer d'un broker, nous permettant d'atteindre de meilleurs performances d'avoir un SPOF en moins.
Remarques
Nous avons constaté un débit de 70 000 événements par seconde en ayant trois consommateurs de messages sur l'application Esper (c'est à dire trois threads). ZeroMQ est donc trois fois plus rapide qu’ActiveMQ ou RabbitMQ.
Plusieurs Esper
Principe
Une manière d'augmenter le débit est d'ajouter des instances du moteur Esper, il faut alors partitionner le flux d'entrée en prenant quelques précautions. En effet, Esper est stateful, c'est à dire que chaque instance d'Esper à un état associé qui lui est propre. Nous devons donc distribuer les événements liés sur une même instance du moteur Esper et pouvons répartir les événements indépendants sur des instances différentes du moteur Esper. En effet, si on prend l'exemple du calcul de la volatilité d'une action, alors le fait de partitionner le flux d'entrée par action à un sens. Chaque instance d'Esper traitera tous les événéments d'une action pour calculer la volatilité de celle-ci. Par contre si l'objectif est de calculer la volatilité globale (toutes actions confondues) alors le fait de partitionner le flux d'entrée par action perd tout son sens.
Bilan
Nous avons donc vu dans cet article que ZeroMQ est la solution offrant d'une part le plus de souplesse et d'autre part le meilleur débit. Esper offre aussi de très bonnes performances tant en terme de latence que de débit. Toutefois nous n'avons pas testé le moteur avec des requêtes EPL complexes. Pour les cas d’usages nécessitant de traiter un débit plus important, la scalabilité horizontale d’Esper dépend de la possibilité fonctionnelle de partitioner le flux d’événements. Dans le cas contraire, il faudrait un moyen de partager l'état des instances des moteurs, par exemple avec une grille de données.