L’évolution des architectures décisionnelles avec Big Data
Big data, l’envers du décor
Nous vivons une époque formidable. En revenant un peu sur l’histoire de l’informatique, on apprend que les capacités que cela soit de RAM, disque ou CPU sont de grands sponsors de la loi de Moore au sens commun du terme (« quelque chose » qui double tous les dix-huit mois). Ces efforts seraient vains si les prix ne suivaient pas le phénomène inverse (divisés par 200 000 en 30 ans pour le disque par exemple).
Exposé comme cela, on se dit que nos envies ne peuvent connaitre de limite et qu’il suffit de changer la RAM, le disque ou le CPU pour prendre en charge l’explosion du volume de données à traiter qui globalement suit bien la loi de Moore aussi.
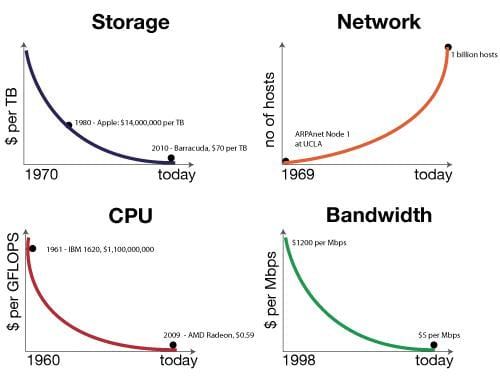
Alors où est le problème, qu’est qui fait que nos architectures décisionnelles aujourd’hui, non contentes de coûter de plus en plus chères, sont aussi en incapacité à se projeter sur des Tera ou des Peta de données. C’est bien simple, un vilain petit canard ne suit pas cette fameuse loi de Moore et il tire vers le bas tous ses petits camarades. Ce vilain petit canard c’est le « disk throughput », soit la capacité de débit des disques. En effet, quand la capacité de stockage des disques a augmenté de 100 000, le débit lui n’a augmenté que de 100… Donc, en schématisant on peut stocker 100 000 fois plus d’information, par contre, ce stockage prendra 1000 fois plus de temps. Allo Houston, on a un problème…
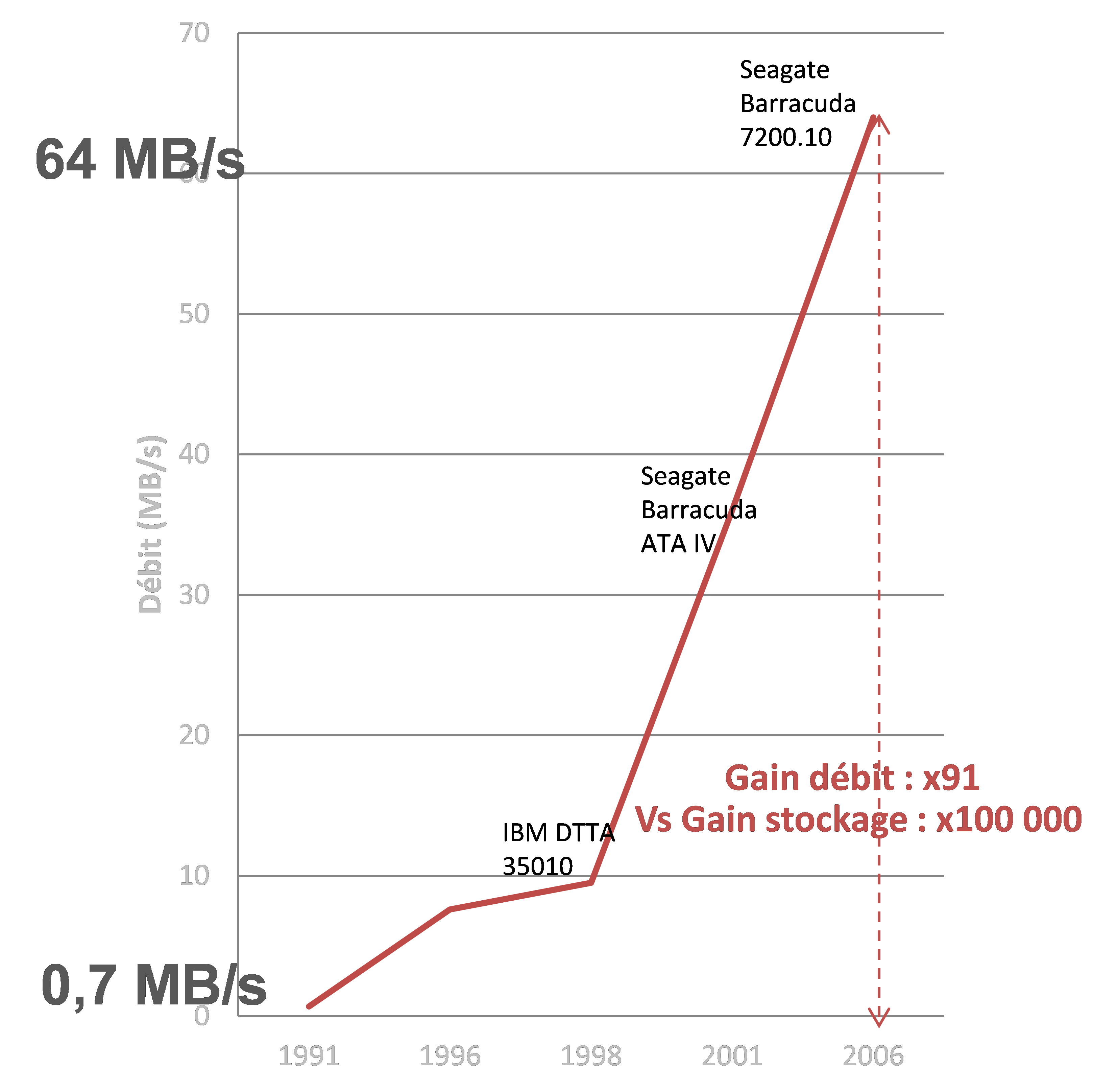
Ce problème est aujourd’hui insoluble techniquement. C’est donc en réfléchissant au-delà du carcan des architectures traditionnelles que des acteurs (les grands du web notamment) ont trouvé des solutions. Si le débit des disques est le bottleneck de l’architecture, alors 2 possibilités de solutions sont offertes :
- Limiter au maximum l’utilisation des disques
- Paralléliser un maximum ce débit pour le rendre acceptable
Pour limiter l’utilisation du débit des disques, une première catégorie d’acteur mettait en place une stratégie dite « in memory » (qlikview, Hana…), pendant qu’une deuxième catégorie d’acteur qui s’attaquait à la parallélisation se lançait dans les architectures distribuées (avec Hadoop en fer de lance). Et c’est véritablement ces solutions qui amènent aujourd’hui les technologies nécessaires à l’avènement de ce qu’on appelle le Big Data.
Si on réalise une cartographie des solutions pour construire une architecture décisionnelle, on se retrouve avec le schéma suivant :
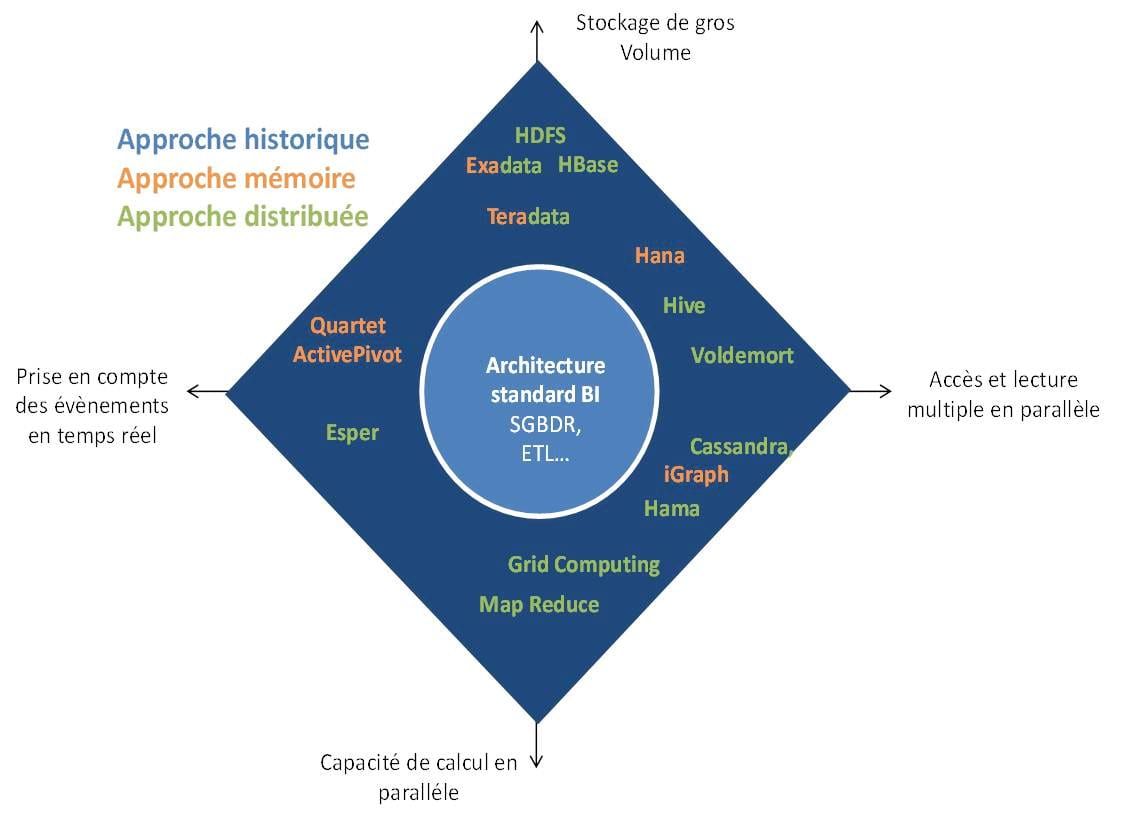
3 classes d’architecture décisionnelle
Architecture décisionnelle « traditionnelle »
Catégorie de solutions : Oracle, SQL Server, MySQL, Informatica, Datastage, …
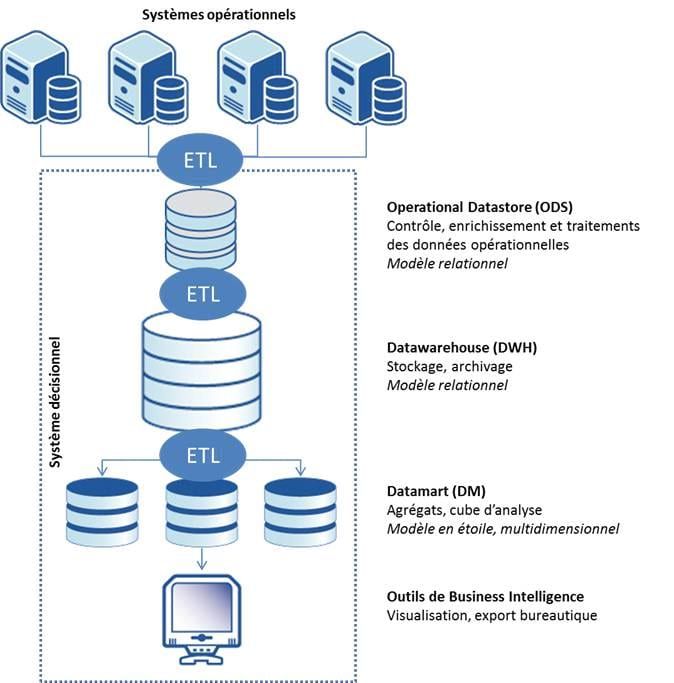
L’architecture décisionnelle « traditionnelle » fonctionne comme un pipeline d’alimentation par étages des systèmes opérationnels jusqu’aux datamarts. Chaque étage dispose de son modèle de données spécialisé optimisé pour sa mission, pour garantir des performances idéales à chaque étage.
Plus le volume de données manipulé par chacun des étages augmente, plus le système ETL doit être capable de fournir un débit important.
Cette architecture est performante lorsque le volume de données à transférer entre chaque étage reste limité, mais se transforme en voie de garage lorsque la taille des photos opérationnelles quotidienne augmente. Cela vient du fait que le système décisionnel va passer principalement son temps à transférer des données plutôt qu’à les traiter.
L’architecture décisionnelle « traditionnelle » est adaptée aux volumes de données stables et aux chaines d’industrialisation de production d’indicateurs stable dans le temps.
Architecture In Memory
Catégorie de solutions : Qlicview, ActivePivot, HANA, …
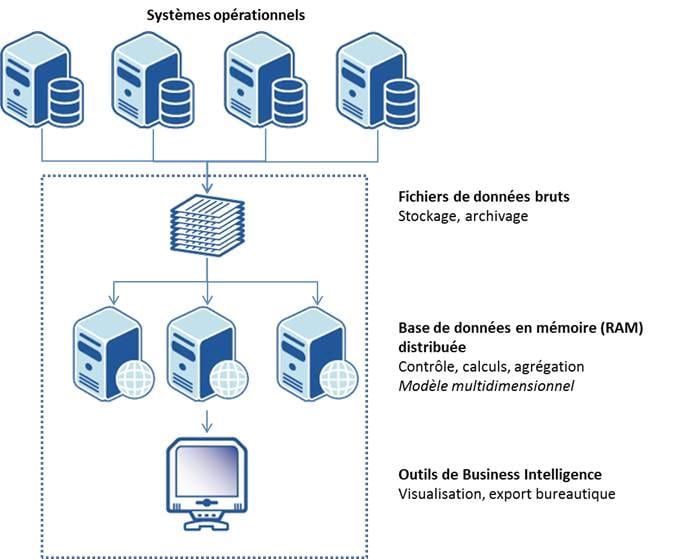
L’architecture d’un système In Memory repose sur la capacité à monter en RAM l’ensemble des données à analyser dans un système unique qui assure l’ensemble des fonctions décisionnelles.
Cette architecture In Memory a été rendue possible par l’évolution des capacités RAM des serveurs et la diminution sa diminution des coûts. Un serveur commodity hardware peut posséder très facilement jusqu’à 512 Go de RAM[1], en 2012.
Pour dépasser cette limite, deux types d’architecture In Memory ont émergée :
- Distribuée : les données sont partitionnées sur plusieurs machines de type commodity hardware
- Approche appliance : les données sont montées en mémoire sur des systèmes capables de supporter plusieurs To de RAM.
Les fichiers d’entrée sont conservés pour assurer le stockage persistant. Les disques SSD, dont la capacité peut atteindre 200 Go en version commodity (< 300 USD)[2], permettent de bénéficier d’un débit de chargement 10 fois supérieur à celui d’un disque dur HDD. Les données In Memory n’ont plus besoin d’être stockées.
L’architecture des processeurs multi-core permet de traiter un grand nombre de requêtes en parallèle sans la contention qu’on observerait avec les I/O des disques durs.
Cette architecture permet d’offrir des services d’analyses performants, même en temps réel (mise à jour des données et re-calcul au fil de l’eau des agrégats) et de simulation.
Architecture Massivement Parallèle
Catégorie de solutions : Hadoop,Teradata
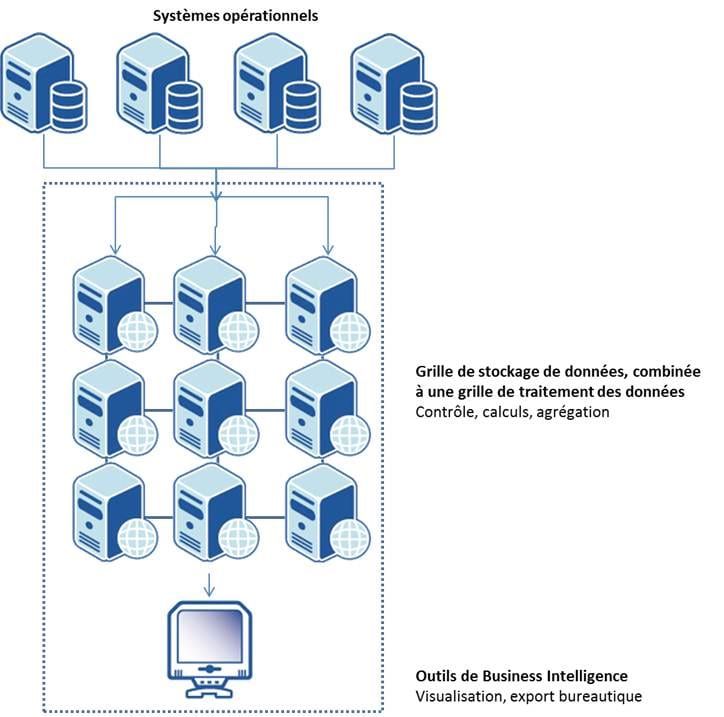
L’architecture Massivement Parallèle repose sur la division du stockage et des traitements sur une grille de serveurs. Les données sont stockées par block et répliqués entre les serveurs et les traitements (script SQL et code de calculs) sont transférés sur les serveurs impliqués par le traitement. La donnée ne bouge pas d’un serveur à l’autre, c’est le code de traitement (d’un volume toujours très faible) qui se déplace. Ce principe s’appelle la colocalisation entre traitements et données.
L’architecture Massivement Parallèle permet de stocker une quantité de données immenses (sans limites) et de manière élastique. Plus la taille de la grille augmente, plus sa capacité de traitement augmente.
Hadoop est une solution Massivement Parallèle Open Source, conçue pour fonctionner sur du commodity hardware.
L’architecture massivement parallèle est idéale et nécessaire pour des systèmes qui vont dépasser la dizaine de 10 To et au-delà.
Elle permet également de mettre en œuvre des traitements particulièrement complexes (datamining & machine learning, simulation numérique, …)
Conclusion
L’évolution des technologies hardware (RAM, multi-core, SSD, parallel computing) et software (architecture distribuée) est en train de fondamentalement bouleverser le paysage des architectures décisionnelles et de datamining.
L’architecture décisionnelle « traditionnelle » avec sa base de données n’est plus l’unique architecture de référence. Il existe à présent 3 architectures de référence complémentaires à maîtriser : base de données, In Memory et massivement parallèle. Ces 3 architectures continuent cependant à partager un facteur de taille, à savoir la qualité de données.
Si on s’intéresse enfin à la dimension humaine associée à ces changements, la mobilisation est à l’ordre du jour :
- Les équipes de production doivent à présent être capable de maitriser des infrastructures unitairement plus simples, mais de plus grande taille à base de commodity hardware ou du matériel spécifique (appliance).
- Les équipes de développement doivent comprendre comment utiliser la puissance du massivement In Memory et de la programmation parallèle, en se détachant progressivement des bases de données relationnelles.
- Les centres de compétences décisionnelles doivent pouvoir accompagner ces équipes à maitriser les évolutions profondes de la technologie, pour tirer profit au mieux de ces architectures et des réductions de coûts qu’elles offrent pour des systèmes de plus en plus puissants.
[1] Taille de la RAM d’un serveur DELL [2] Source DELL
Article précédemment publié sur www.decideo.fr