Les Observables dans la vraie vie
Dans cet article nous allons voir un cas d’usage où les Observables se révèlent particulièrement pertinents pour rendre le code plus simple, plus maintenable.
Repérer un scanner de code-barres !
Ouaip ! L’exemple est plutôt spécifique, mais il illustre bien le genre de problématiques qui sont tout à fait adaptées à l’usage des Observables.
Un scanner de code-barres simule un clavier. Quand on scanne un code-barre, il reproduit celui-ci en émettant des événements keypress, terminant la séquence par la touche “Entrée” (dont le keyCode est 13).
Imaginons-nous en train de développer une application qui permet notamment aux utilisateurs de rechercher des produits à partir de leur référence. Une référence produit est un code de 16 caractères. Plutôt que de les retaper à la main, l’utilisateur doit pouvoir utiliser un scanner de code-barres pour lancer la recherche.
« Y’a qu’à laisser l’utilisateur mettre le focus dans l’input du formulaire de recherche. Il scanne le code et ça marche ! »
Effectivement, c’est le comportement natif.
Mais la fonctionnalité de recherche est contenue dans une popup, que l’on ouvre via un bouton. Or, on nous a précisé que l’application devait être super-ergonomique ! On veut que si l’utilisateur scanne le code, alors la popup doit s’ouvrir et l’input se remplir avec le code scanné, peu importe où se trouve l’utilisateur sur la page.
Finalement, la question que nous devons résoudre est : comment allons-nous faire la différence entre un code scanné et les autres événements keypress ? Par exemple, si l’utilisateur appuie sur une touche par mégarde avant de scanner un code-barre, cette touche ne doit pas se retrouver dans l’input.
Résoudre ça de façon classique et impérative
A priori, nous avons besoin d’écouter les événements keypress… Puis nous devons probablement… enregistrer les touches appuyées (= faire un buffer) en agrégeant les codes correspondants à ces touches (keyCode) !
Du coup, si la touche pressée est “Entrée”, alors on remplit l’input puis on nettoie le buffer. Autrement, on ajoute la touche au buffer.
Essayons ça :
const ENTER_KEY_CODE = 13
let keyCodesBuffer = []
document.addEventListener("keypress", (event) => {
const keyCode = event.keyCode
if (keyCode === ENTER_KEY_CODE) {
fillInputWithKeyCodesBuffer()
cleanBuffer()
} else {
addToBuffer(keyCode)
}
})
function fillInputWithKeyCodesBuffer() {
// …
}
function cleanBuffer() {
keyCodesBuffer = []
}
function addToBuffer(keyCode) {
keyCodesBuffer.push(keyCode)
}
Pas mal.
Mais pas suffisant : le code ne différencie pas les code-barres scannés des keypress manuels.
Après quelques tests, on sait que le scanner enchaîne les événements keypress en quelques millisecondes. Il est donc acceptable de se dire que si aucun événement n’a été émis après 50ms, alors il ne s’agit certainement pas d’un code scanné et nous pouvons nettoyer le buffer.
const ENTER_KEY_CODE = 13
const MAX_INTERVAL_BETWEEN_EVENTS_IN_MS = 50
let keyCodesBuffer = []
document.addEventListener("keypress", (event) => {
const keyCode = event.keyCode
if (keyCode === ENTER_KEY_CODE) {
fillInputWithKeyCodesBuffer()
cleanBuffer()
} else {
addToBuffer(keyCode)
cleanBufferAfter(MAX_INTERVAL_BETWEEN_EVENTS_IN_MS)
}
})
function fillInputWithKeyCodesBuffer() {
// …
}
function cleanBuffer() {
keyCodesBuffer = []
}
function addToBuffer(keyCode) {
keyCodesBuffer.push(keyCode)
}
function cleanBufferAfter(timeout) {
setTimeout(cleanBuffer, timeout)
}
C’est mieux ! Mais nous venons d’introduire un bug subtil : si le code met plus de 50ms à être scanné en totalité, nous allons en perdre un bout… Puisque le buffer est nettoyé 50ms après que le premier événement.
Il faut donc renouveler le timeout si un nouvel événement arrive avant 50ms.
const ENTER_KEY_CODE = 13
const MAX_INTERVAL_BETWEEN_EVENTS_IN_MS = 50
let keyCodesBuffer = []
let cleanBufferTimeout
document.addEventListener("keypress", (event) => {
const keyCode = event.keyCode
stopCleanBufferTimeout()
if (keyCode === ENTER_KEY_CODE) {
fillInputWithKeyCodesBuffer()
cleanBuffer()
} else {
addToBuffer(keyCode)
cleanBufferAfter(MAX_INTERVAL_BETWEEN_EVENTS_IN_MS)
}
})
function fillInputWithKeyCodesBuffer() {
// …
}
function cleanBuffer() {
keyCodesBuffer = []
}
function addToBuffer(keyCode) {
keyCodesBuffer.push(keyCode)
}
function cleanBufferAfter(timeout) {
cleanBufferTimeout = setTimeout(cleanBuffer, timeout)
}
function stopCleanBufferTimeout() {
clearTimeout(cleanBufferTimeout)
}
Voilà ! À présent nous avons quelque chose qui fonctionne.
Prenons un peu de recul et posons-nous la question : que se serait-il passé si nous avions pu analyser les événements keypress et leurs prédécesseurs au fur et à mesure de leur arrivée ? Le code aurait-il été plus simple ? Essayons voir…
Résoudre ça avec des Observables
Personnellement, je trouve que les Observables sont une abstraction parfaite pour traiter ce genre de problématiques.
Les Observables sont des collections immuables d’événements asynchrones que l’on peut manipuler via des opérateurs.
Si nous avons l’habitude d’utiliser des choses comme map et filter sur des tableaux, alors nous sommes déjà familiers avec cette manière de raisonner.
À l’heure actuelle, le concept des Observables en JavaScript n’est qu’au stade 1 de la proposition. Nous allons donc utiliser la librairie RxJS qui implémente le concept des Observables en JavaScript et nous fournit les opérateurs pour les manipuler.
En passant, Il est intéressant de noter que cette librairie est la version JS de la suite ReactiveX, qui implémente le concept dans de nombreux langages (Java, Scala, .Net, Python, Ruby, Swift…). Le concept et l’API que nous allons utiliser ici peut donc se transposer dans d’autres langages.
Si le concept des Observables vous paraît toujours mystérieux, je vous suggère de lire cette excellente introduction à la Programmation Réactive par André Staltz.
Au lieu de répondre individuellement à chaque événement, nous allons donc les collecter dans un seul flux que nous allons ensuite transformer.
const keyCode$ = Rx.Observable.fromEvent(document, "keypress")
// ---(ev)--(ev)--------(ev)--->
.pluck('keyCode')
// ---(43)--(51)--------(13)--->
Le signe $ à la fin du nom de la variable signifie “Stream”. C’est une convention pour indiquer que la variable en question est un Observable ; ce qui est particulièrement utile dans un langage non-typé.
Nous avons donc un flux de keyCode. À chaque fois qu’un événement keypress est émis, un nouvel événement est poussé dans le flux avec pour valeur la keyCode correspondante.
Au final, nous aimerions avoir un flux auquel nous pouvons souscrire et dont chaque événement représente le code scanné. Nous devons donc créer des batchs de keyCodes de manière à isoler les codes scannés des keypress parasites.
Pour cela, nous pouvons buffer (mettre en tampon) notre flux avec une stratégie de debounce : quand un événement est émis, nous attendons 50ms pour le prochain. Si un nouvel événement est émis, nous attendons à nouveau 50ms. Sinon, nous faisons un batch des événements qui ont eu lieu.
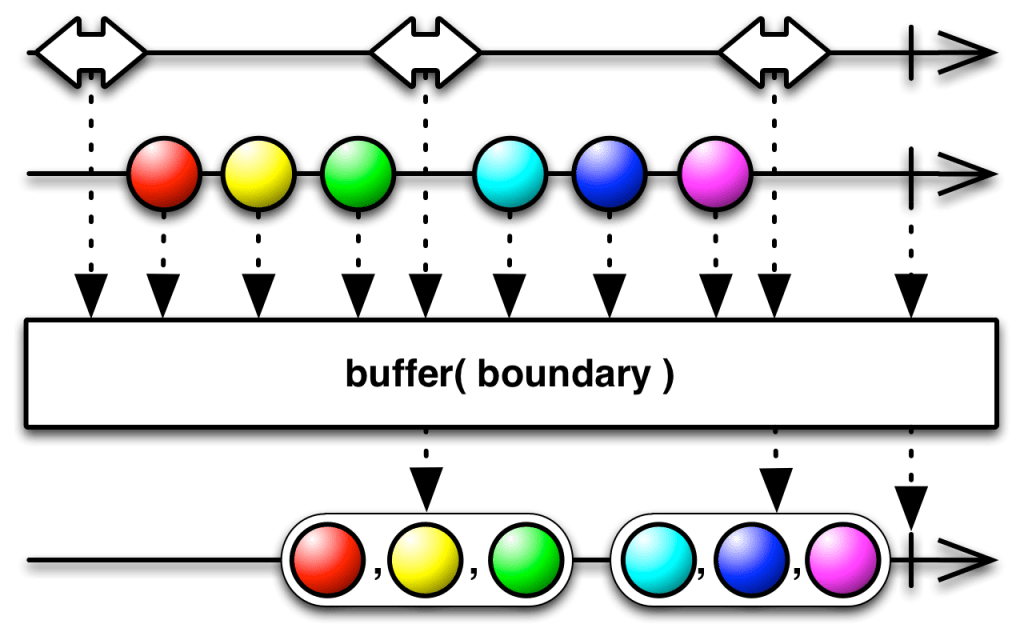
Ce que nous souhaitons faire, avec l’opérateur buffer
const MAX_INTERVAL_BETWEEN_EVENTS_IN_MS = 50
const keyCode$ = Rx.Observable.fromEvent(document, "keypress")
.pluck('keyCode')
const keyCodesBuffer$ = keyCode$
// --(43)-(64)----(32)-----(65)-(77)-(13)--->
.buffer(keyCode$.debounce(MAX_INTERVAL_BETWEEN_EVENTS_IN_MS))
// --([43,64])----([32])-----([65,77,13])--->
Jusqu’ici, tout va bien !
À présent, tout ce qu’il nous reste à faire est de filtrer les batchs qui ne ressemblent pas à des codes scannés. Or nous savons qu’un code scanné, c’est une séquence qui se termine par la touche “Entrée”.
const ENTER_KEY_CODE = 13
const MAX_INTERVAL_BETWEEN_EVENTS_IN_MS = 50
const keyCode$ = Rx.Observable.fromEvent(document, "keypress")
.pluck('keyCode')
const keyCodesBuffer$ = keyCode$
.buffer(keyCode$.debounce(MAX_INTERVAL_BETWEEN_EVENTS_IN_MS))
.filter(isFromScan)
function isFromScan(keyCodes) {
return keyCodes.length > 1 && keyCodes[keyCodes.length - 1] === ENTER_KEY_CODE
}
Enfin, souscrivons au flux que nous venons de créer afin d’exécuter le callback à chaque fois qu’un nouvel événement est émis.
const ENTER_KEY_CODE = 13
const MAX_INTERVAL_BETWEEN_EVENTS_IN_MS = 50
const keyCode$ = Rx.Observable.fromEvent(document, "keypress")
.pluck('keyCode')
const keyCodesBuffer$ = keyCode$
.buffer(keyCode$.debounce(MAX_INTERVAL_BETWEEN_EVENTS_IN_MS))
.filter(isFromScan)
function isFromScan(keyCodes) {
return keyCodes.length > 1 && keyCodes[keyCodes.length - 1] === ENTER_KEY_CODE
}
function fillInputWith(keyCodes) {
// …
}
keyCodesBuffer$.subscribe(fillInputWith)
Notons que rien ne se passe tant que nous ne souscrivons pas à notre Observable car il est paresseux.
Qu’avons-nous accompli ?
Voici une représentation visuelle de ce que nous avons fait pour passer de keyCodes$ − créé à partir des événements keypress − au keyCodesBuffer$ auquel nous avons souscrit :
Transformation du flux de keyCodes en un flux de codes scannés
Il y a un certain nombre de points à noter avec notre code final :
- nous n’avons pas à gérer des choses telles que des timeouts ou des buffers à la main
- du coup, le code plus court, focalisé sur l’intention
- fillInputWith() ne dépend pas d’un buffer global, le rendant plus facilement testable et ré-utilisable (en fait, nous ne sommes pas très loin d’avoir une logique complètement fonctionnelle)
- nous manipulons uniquement des const, rien n’est ré-assigné, ce qui rend le raisonnement plus simple
- les flux créés peuvent être réutilisés pour faire d’autres choses ; nous pouvons ajouter des fonctionnalités sans avoir peur de casser celle-ci
- nous pourrions facilement corriger des problèmes dans ce code en injectant des opérateurs en cas de besoin (ex. : nous pourrions facilement filtrer les keyCodes qui ne nous intéressent pas avec un simple .filter(isValidKeyCode))
Selon moi, la seule difficulté consiste à raisonner avec des flux pour comprendre comment résoudre notre problème avec les opérateurs à notre disposition.
Et finalement, c’est quelque chose qui s’acquiert avec la pratique ?
Pour conclure, je dirai que les Observables sont un bon outil pour résoudre des problématiques où il faut gérer des flux d’événements. Ce n’est pas un marteau doré qu’il faut sortir systématiquement ; mais c’est une excellente abstraction qui peut nous simplifier la vie quand on manipule des données asynchrones.