L’architecture microservices sans la hype : qu’est-ce que c’est, à quoi ça sert, est-ce qu’il m’en faut ?
En 2015, le pic des microservices a été atteint : pas une conférence sans un ingénieur de Netflix pour vous vendre du rêve, pas une semaine sans nouveau framework magique pour tout faire sans se poser de question.
Résultat : une focalisation sur les outils et les belles histoires plutôt que sur les questions de fond.
Il nous a donc semblé utile de faire le point sur les aspects architecturaux des microservices, car choisir un style d’architecture pour un système d’information a des conséquences structurantes sur la vie des projets et l’organisation de l’entreprise.
Note de vocabulaire
Avant d’entrer dans le vif du sujet, il est nécessaire de préciser deux notions :
- On désigne par service un service métier, c’est à dire un groupe de services techniques (REST, SOAP…) qui, ensemble, fournissent une fonctionnalité qui a un sens métier.
- Projet designe un projet de développement informatique sur l’ensemble de son cycle de vie et pas seulement pendant sa "phase projet" avant une bascule en mode maintenance.
1) Pourquoi les microservices : les problèmes des gros projets
L’architecture microservices a été inventée pour résoudre certaines des difficultés causées par les gros projets.
Avec le temps, les projets informatiques ont tendance à grossir : on étend petit à petit les fonctionnalités existantes, on en ajoute d’autres, et on supprime rarement les anciennes.
En même temps que le code et le projet s’étendent, un certain nombre de douleurs apparaissent :
Complexité
Quand la quantité de code augmente, le code devient de plus en plus complexe. Même avec une architecture logicielle solide, les interdépendances entre les différentes briques augmentent avec le temps.
Cette complexité a deux désavantages :
Évolutivité et fiabilité
Plus le temps passe, plus les nouvelles fontionnalités métier deviennent complexes, et plus les différentes briques ont d’interactions. On a beau organiser le code en couches et en composants, il y a toujours des cas particuliers et des rustines qui rendent les choses plus floues.
Au-delà d’un certain seuil, il devient impossible d’avoir en tête un modèle global du projet.
Même avec une base de tests solide, la multiplication des effets de bord de chaque action rend le système moins fiable, et il devient alors plus difficile d’ajouter proprement des nouvelles fonctionnalités et d’effectuer des refactorings.
Scalabilité horizontale
Améliorer la scalabilité d’un système peut demander de modifier des éléments structurants du projet.
Plus un projet est gros, plus ces interventions deviennent coûteuses et risquées.
Le risque est alors de se retrouver avec un système qu’il est impossible de faire évoluer pour un nouveau cas d’usage.
Innovation
Innovation technologique
Pour capitaliser les investissements et faciliter la gestion des personnes, il est normal de vouloir avoir une cohérence entre les différents projets d’une entreprise : même manière de travailler, mêmes langages de programmation, mêmes outils.
Chaque projet est invité à suivre des choix transverses, et peut s’en écarter en fonction de ses spécificités, à condition de le justifier.
Pour les gros projets, la même tension a lieu à l’intérieur même des projets : pour éviter la fragmentation, chaque évolution technique doit pouvoir être propagée à l’intégralité du code.
Avec le temps, les modifications deviennent donc plus coûteuses, et il est plus difficile d’introduire de nouveaux outils pour des besoins spécifiques.
Innovation métier
Pour répondre aux nouveaux besoins métier, il faut être capable de ménager une zone d’innovation à l’intérieur des projets.
Car si certaines nouveautés sont mises en œuvre par de nouveaux projets, la plupart se font sur des projets existants.
Or plus un projet est gros, plus il est critique pour l’entreprise, moins on va prendre de risques de le modifier pour tester de nouveaux produits ou de nouveaux marchés, et petit à petit les enjeux de stabilité vont prendre le pas sur la capacité d’innovation.
2) L’idée de l’architecture de microservices
Les problèmes qu’on vient de décrire sont connus depuis longtemps, et des pratiques issues de l’agilité et de l’artisanat logiciel permettent de limiter leur impact.
Malheureusement, ces recettes demandent d’être rigoureux en permanence, et de l’être de plus en plus, au fur à et mesure qu’un projet grossit et que les personnes changent.
Elles sont donc souvent mises en œuvre sur le papier ou imparfaitement, avec pour conséquence des projets inmaintenables qu’on traine des années avant de les remplacer.
À ce danger, la réponse des microservices est simple et assez radicale : pour éviter les problèmes des gros projets, il suffit de n’avoir que des petits projets.
On va donc limiter la taille des projets à quelques personnes pour avoir des pizza teams d’une taille maximale de sept personnes tout compris. En découpant au besoin les projets et les équipes existantes pour s’y conformer.
Il ne s’agit pas de séparer les gros projets en sous-équipes mais bien de projets indépendants : chacun a son organisation, son calendrier, sa base de code et ses données.
Les échanges entre les projets se font par des services, qu’il s’agisse d’appels de services (REST / JSON) ou de messages.
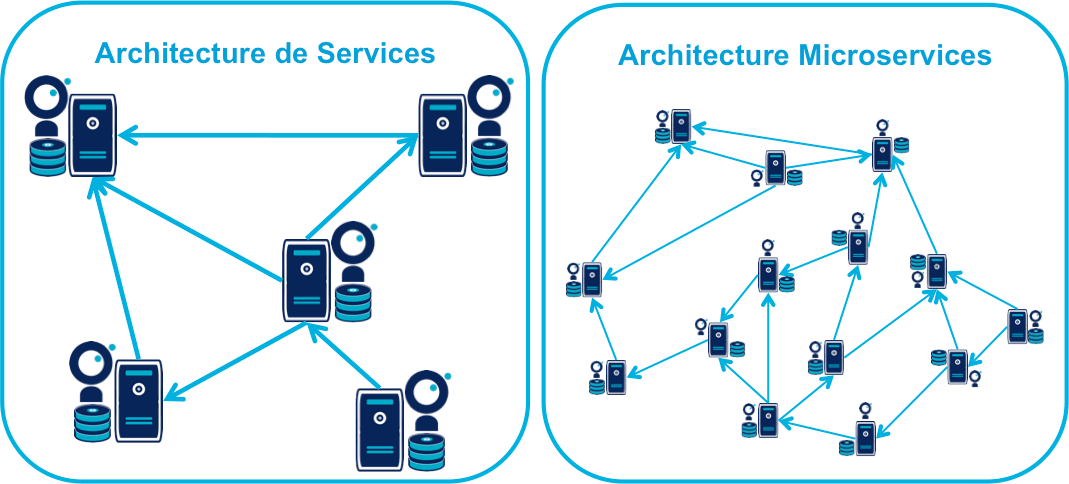
Le découpage se fait par domaine métier, en groupant les services et les types de données qui ont des liens forts, et en séparant quand ils sont suffisamment indépendants.
Si la configuration-type est d’une unité de déploiement par équipe, la régle est plutôt de n’avoir au plus qu’une équipe par unité de déploiement. Si le domaine métier est implémenté en plusieurs applications, elles seront portées par la même équipe.
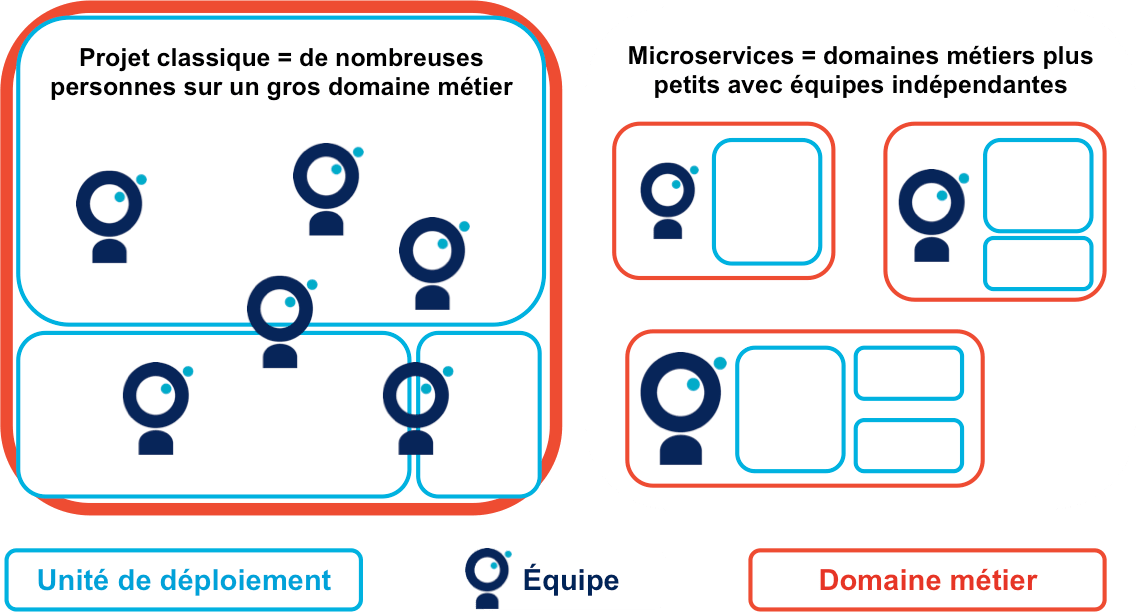
Si vous ne comprenez pas pourquoi tout cela s’appelle "microservices", c’est normal : il s’agit d’un buzzword pour rendre le concept attractif. Dans la même veine, les admirateurs de cette approche appellent "monolithes" les applications classiques, pour mettre en avant leur côté négatif, voire menaçant.
Cette architecture est ainsi à la confluence de plusieurs mouvements de fond de l’informatique :
- la SOA a mis en avant les avantages de l’approche services ;
- l’agile et le lean startup ont fourni les modèles d’organisation des équipes ;
- l’industrialisation des déploiements et la virtualisation permettent de baisser les coûts de mise en production et d’exploitation ;
- le NoSQL a décrispé les choses du côté de l’intégrité des données.
3) Les avantages de l’approche microservices
Complexité
Évolutivité et fiabilité
Contraindre la taille limite les cas particuliers, et permet d’avoir en tête l’intégralité des comportements.
La dette technique est gardée sous contrôle, et le code est ainsi capable d’évoluer. Passer par des appels de services pour communiquer avec les autres domaines formalise les échanges. Les contrats d’interface sont alors plus carrés, et il est plus facile de prendre en compte tous les cas, y compris les cas d’erreurs.
Scalabilité horizontale
Avec des applications d’une taille limitée, il est plus facile d’augmenter la scalabilité en refactorant le code ou en la réécrivant complètement en fonction des nouveaux besoins.
Innovation
Innovation technologique
Les bases de codes et les équipes sont indépendantes et peuvent donc faire leurs choix techniques en fonction de leurs besoins propres.
Innovation métier
Si tout le système d’information est structuré en services, il est facile d’expérimenter en démarrant un nouveau projet s’appuyant sur les données des autres, et plus facile de décomissionner car c’est l’ensemble d’un projet qui sera supprimé.
4) Les prérequis et les limites
Si l’architecture microservices présente de nombreux avantages, elle a de nombreux prérequis et un certains nombres de limites.
Les microservices étant une déclinaison des architectures SOA classiques, on retrouvera les mêmes caractéristiques, mais avec un niveau de criticité supplémentaire.
Le système devient distribué
Les architectures classiques permettent de faire en sorte d’avoir des états indépendants entre les différentes applications : chacun est maître de son domaine métier.
Lors du passage aux microservices, le système devient largement distribué. Cela introduit de nouvelles classes de problèmes particulièrement difficiles.
Le cas le plus compliqué est celui des transactions : à chaque fois qu’une transaction est partagée entre deux applications, il faut gérer des transactions en deux phases ou gérer des annulations. Dans un système basé sur des services, il n’existe pas d’outil permettant de le prendre en compte de manière automatisée. Il faut donc le faire manuellement à chaque endroit du code.
Et même quand on peut se passer de transaction : il y a toujours des références de données cross-applications, et donc un système de gestion d’évènements asynchrones voire de cache à mettre en œuvre pour assurer la cohérence des données.
Ensuite il y a les cas d’indisponibilités des services externes. Car utiliser les services d’une autre application, c’est devenir dépendant d’elle. L’approche design for failure permet de limiter les risques mais demande d’avoir une ingénierie rigoureuse.
Il faut également bien maitriser l’ensemble des qualités de services (SLA) des différentes applications pour ne pas se faire surprendre.
Finalement le système devient plus difficile à tester : les tests d’intégration à effectuer deviennent plus nombreux, et demandent de bien préparer les données et d’être bien outillé pour pouvoir tester les cas d’erreurs techniques et métier.
Services à valeur ajoutée
Même si l’approche REST propose de manipuler des entités simples, il y a toujours une proportion d’appels "à valeur ajouté" qui font appel à plusieurs domaines métier.
Dans le cas des microservices, cela signifie composer des appels entre plusieurs applications.
Cela a pour effet de multiplier les cas d’erreurs à gérer (problème des systèmes distribués) et d’additionner les latences réseau.
Pour les cas les plus critiques, il devient nécessaire d’ajouter des services spécifiques dans les différentes applications, voire d’ajouter des caches de données, entrainant des problèmes de cohérence.
Évolutions transverses
Avec des projets séparés et donc des équipes indépendantes, les évolutions transverses sont plus difficiles à mettre en œuvre. Cela demande aux différents groupes de se synchroniser ou d’instaurer un système complexe de cycle de vie des versions.
Le problème est encore aggravé lorsqu’on veut itérer rapidement car cela demande à chacun de se synchroniser en permanence.
Pour garder une certaine souplesse, la solution naturelle est alors d’isoler des grappes de projets des autres en limitant les interconnections entre groupes (pattern Royaume/Émissaire). Le risque est alors d’ajouter une couche de management intermédiaire qui ne soit pas au contact direct des projets.
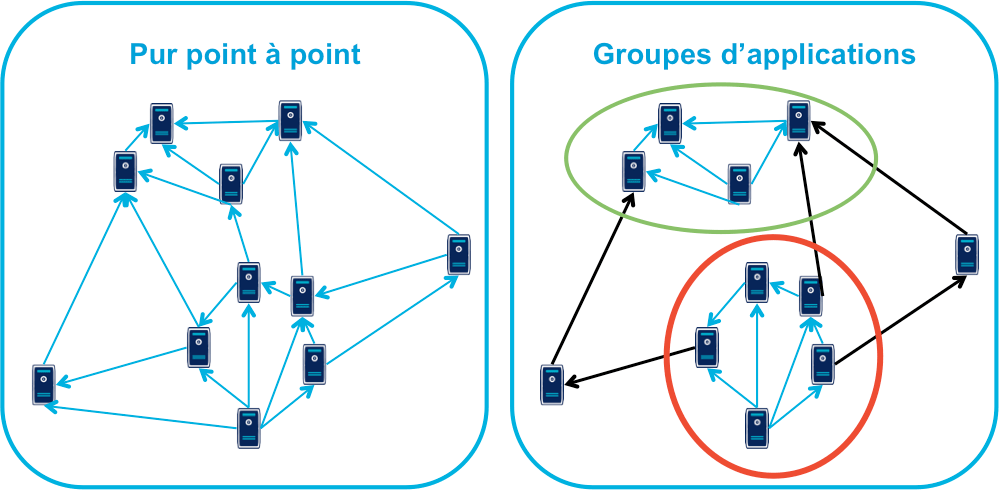
DevOps et provisionning
Multiplier les applications, c’est multiplier le nombre de déploiements et d’instances de serveurs.
Pour éviter les erreurs et les surcoûts trop importants, il faut un workflow très efficace au niveau outils et process avec des déploiements le plus automatisé possible. Cela est d’autant plus vrai pour les tests et les POC où l’on veut des environnements temporaires sous forme de sandbox.
Démarrage de projets rapides et allocation de personnes.
Choisir les personnes, organiser les transferts, constituer un budget… : dans une organisation classique, créer un nouveau projet peut prendre beaucoup de temps et d’argent.
Pour qu’il soit viable de multiplier les projets qui vivent chacun leur vie, il faut que cet aspect organisationnel soit industrialisé.
Avec un gros projet, on peut réallouer la capacité à faire entre différentes parties, alors que des structures plus petites sont sensibles aux variations du volume de travail. Il faut donc pouvoir agrandir ou diminuer des équipes sans que ces changements posent trop de contraintes.
On ne parle pas de mettre en place des pools de développeurs partagés ou de déplacer les personnes comme des pions, mais d’avoir une certaine souplesse.
Maturité d’exploitation et monitoring
Beaucoup plus de services très interdépendants nécessite :
- un très bon monitoring de flux pour savoir rapidement où se posent les problèmes ;
- une grande maturité d’exploitation car cela va multiplier les pannes ;
- un monitoring accessible aux consommateurs des services pour qu’ils puissent comprendre d’où viennent les pannes lorsqu’elles ont des conséquences pour eux.
Technologie et maintien des compétences
Les choix technologiques étant plus nombreux et plus décentralisés, il est plus facile de se tromper : les arbitrages entre innovation et pérennité sont plus difficiles. Permettre de l’innovation pour répondre à de nouveaux besoins, c’est accepter de commettre des erreurs une partie du temps.
Il y a aussi le risque de négliger les bonnes pratiques de développement, car il y a moins d’enjeux et de risques.
Finalement, des applications plus petites ont plus facilement des périodes de pause où il n’y a pas d’évolution à développer dans les domaines qu’elles couvrent, avec par exemple une bascule dans un mode TMA. Dans ce cas, les membres de l’équipes sont répartis ailleurs et les risques de perte de connaissance sont importants.
Stratégie et gouvernance
Pour des gros projets liés aux produits de l’entreprises, la vision stratégique vient directement du métier. Les partenaires étant peu nombreux, il est facile d’arbitrer entre les différentes demandes en fonction du poids de chacun.
Avec des microservices, beaucoup de projets techniques seront éloignés du business et auront de nombreux interlocuteurs. Il faut donc une organisation mature dans sa communication, sa gestion des priorités et dans ses mécanismes de priorisation.
5) Est-ce qu’il m’en faut ?
L’approche fondamentale de la SOA consiste à garder le contrôle de la complexité organisationnelle et métier en la distribuant.
En séparant les projets, on diminue la complexité sur certains axes en échange d’un surcoût à d’autres endroits, notamment celui d’avoir un système plus distribué.
On peut avoir des monolithes bien organisés, scalables, évolutifs…, mais cela demande une forte discipline de tous les instants. L’architecture microservices choisit de ne pas prendre ces risques pour être certain de garder le contrôle.
Par contre, si cela est mis en œuvre dans un environnement mal adapté ou d’une mauvaise manière, on va cumuler les inconvénients sans bénéficier des avantages, et on prend alors beaucoup plus de risques que dans une architecture de services plus classique.
Donc surtout ne vous dites pas qu’il vous faut des microservices, demandez-vous :
- si vous avez les problèmes que cette approche résoud ;
- si vous avez les prérequis nécessaires, ou si vous êtes prêt à faire en sorte de les atteindre avant d’entamer la migration.
Dans ce cas seulement posez vous la question.
Et n’oubliez pas qu’une architecture est un outil qu’on adapte à ses besoins et pas un dogme à respecter : si ce qui vous convient est une solution hybride reprennant certaines des idées des microservices et pas d’autres, lancez vous !
6) Comment j’y vais
Une fois décidé qu’une architecture microservices est la bonne solution, encore faut-il parvenir à la mettre en place.
S’il n’y a pas de solution magique, quelques approches semblent émerger.
Le cas difficile : partir de zéro
La situation la plus attirante est celle d’un nouveau système à créer à partir de zéro : rien à remettre en cause ni à gérer, cela semble la situation idéale.
Malheureusement partir sur des microservices à partir de rien représente le cas le plus difficile :
- il est compliqué de déterminer a priori les limites où il faut découper les différents projets, car on ne sait pas comment le système va évoluer
- comme on l’a déjà vu, les évolutions sont plus coûteuses, car il faut faire du refactoring cross-projet.
À moins d’être déjà mature sur un sujet, il vaut mieux donc partir sur un monolithe dans un premier temps.
Le cas favorable : peler un monolithe
Le cas le plus favorable est celui monolithe qu’on "pèle". En examinant son organisation et sa structure, on va externaliser les morceaux à la bordure du système suivant les lignes de découpe qui sont apparues naturellement.
L’objectif n’est pas de se retrouver avec 50 mini-projets mais plutôt :
- une ou plusieurs applications "cœur" de taille moyenne, cohérentes entre elles ;
- des microservice qui gravitent autour, et qui vont s’en éloigner avec le temps.
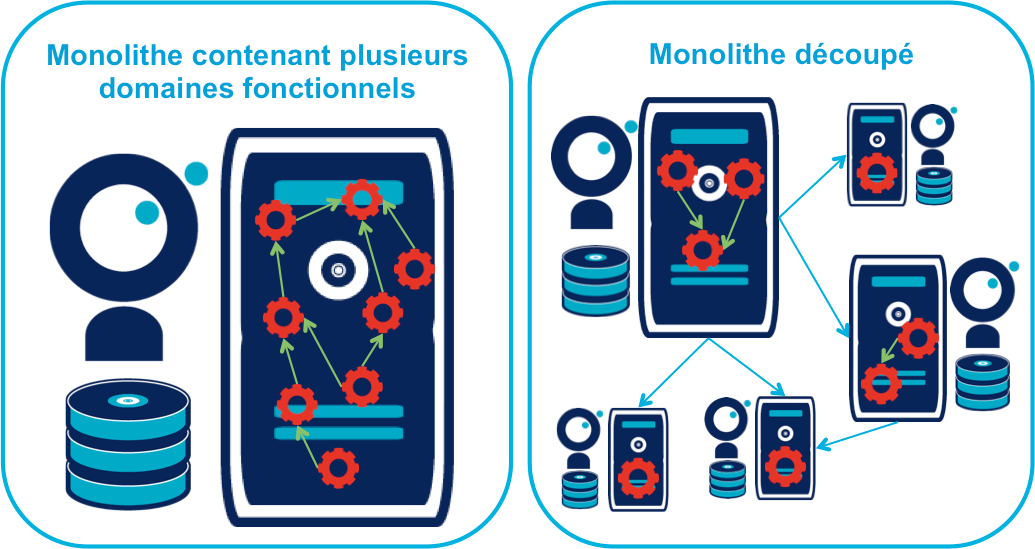
Cette opération est rendue d’autant plus facile que l’application initiale est bien structurée en couches techniques et en briques métier et que cette restructuration est respectée. Les bonnes pratiques du développement logiciel permettent ainsi d’avoir des projets "microservices-ready". Dans le cas contraire, il faut beaucoup détricoter pour extraire certaines parties du code.
Des tests automatisés sont essentiels pour limiter les risques. En leur absence il faut considérer l’application comme du legacy et utiliser les techniques appropriées pour la désendetter.
Avant de s’attaquer au découpage, il faut examiner les problèmes que pose la distribution des données : c’est l’élément le plus structurant et peut rendre l’opération impossible.
Finalement, il faut éviter d’être dogmatique en considérant que l’opération est forcément à sens unique.
Si par la suite d’autres évolutions des projets se rapprochent et que leur séparation pose plus de problèmes qu’elle n’en résout, il ne faut pas hésiter à les refusionner. Refusionner deux projets n’est pas un aveu d’échec mais plutôt un bon signe car cela indique que, lorsque votre métier évolue, votre informatique est capable de s’adapter.
Pour aller plus loin
- How we ended up with microservices sur l’expérience de SoundCloud
- Microservices. The good, the bad and the ugly
- Out of the Fire Swamp – Part III, Go with the flow sur les questions de données
- Introduction to Microservices sur le blog de Nginx
- MonolithFirst par Martin Fowler
- Manœuvre de Conway inversée chez ThoughtWorks
- Domain-driven design