La technologie GPGPU – 1ère partie : Le côté obscur de la (Ge)Force

Les processeurs graphiques ou GPUs sont aujourd’hui capables de beaucoup plus que des calculs de pixels dans les jeux vidéo. Pour cela, Nvidia développe depuis quatre ans une interface matérielle et un langage de programmation dérivés du C, CUDA (Compute Unified Device Architecture).
Cette technologie dite GPGPU (General-Purpose computation on Graphic Processing Units) exploite la puissance de calcul des GPUs pour le traitement des tâches massivement parallèles.
Contrairement au CPU, un GPU n’est pas adapté à un traitement rapide de tâches qui s’exécutent séquentiellement. En revanche, il convient très bien au traitement d’algorithmes parallélisables. Cet aspect est abordé plus en détail dans cet article.
Les GPUs sont d’ores et déjà utilisés dans de nombreux domaines. Leur utilité et efficacité n’est plus à démontrer. Par exemple, le National Center for Atmospheric Research aux Etats-Unis a porté 1% de son code de recherche et prévision météorologique sous CUDA et obtenu un gain de performance de 20% sur la totalité de l'application.
Le monde de la finance s'est lui aussi rapidement intéressé au potentiel du GPU. Des simulations financières complexes sont maintenant utilisées pour limiter les risques et pouvoir les traiter rapidement.
Par exemple, la société SciComp a amélioré son produit star SciFinance pour fournir des modèles de prix de produits dérivés avec CUDA qui tournent entre 20 et 100 fois plus rapidement qu’avec un code séquentiel (source Nvidia).
En France, BNP Paribas a implémenté une architecture GPU pour réduire sa consommation électrique et accélérer le temps de calcul. Leur plateforme contient deux modules Tesla S1070, consommant 2kW qui remplacent environ 500 cœurs CPU, consommant 25kW. Les bénéfices sont :
- Réduction par 190 de l’ensemble de la consommation électrique donc diminution de l’impact environnemental.
- Des temps de réponses divisés par 15.
- Réductions des coûts.
Pourquoi les GPUs sont bénéfiques dans le domaine de la finance ?
Les applications liées à la finance exigent de hautes performances de calcul. Voici quelques exemples pour lesquels l’utilisation de GPU peut-être avantageuse :
Analyse de risque
Le GPU est approprié pour l’exécution de multiples simulations nécessaires afin d’évaluer avec précision le degré de risque d’un portefeuille boursier. Le calcul de la VaR, par exemple, est un indicateur important dans le domaine financier. La VaR peut se calculer à l’aide d’une simulation de Monte-Carlo, très gourmande en temps à cause du besoin de simuler de nombreuses trajectoires avec multiples paramètres. Un tel algorithme est très bien adapté pour un GPU car il s’appuie sur l’exécution d’un grand nombre de tirages aléatoires et calcule la probabilité d’occurrence de chacun des résultats. Ces probabilités sont indépendantes et calculées en parallèle, le résultat final est calculé par agrégation des résultants intermédiaires. Pour plus d’information, je vous renvoie à une série d’articles écrits par Marc Bojoly sur ce type de calcul, ici ou encore ici.
Évaluation des produits dérivés
L’évaluation de produits dérivés requiert un long temps de calcul. Une entreprise peut avoir besoin de calculer les stratégies de couverture pour des centaines de milliers de porteurs dans un portefeuille, de façon régulière. Une résolution numérique d’équation différentielle, une simulation de Monte Carlo peuvent être utilisées ou encore un arbre binomial de Cox-Rubinstein. Ces deux dernières techniques sont particulièrement appropriées à l'utilisation d’un GPU. Des librairies (BLAS, LAPACK) ont aujourd’hui également été portées sur GPU pour accélérer la résolution numérique d’équations différentielles.
Autres bénéfices du GPU
La puissante brute théorique d’un CPU ou GPU peut se mesurer en FLOPS (FLoating point Operations Per Second). Cette mesure ne représente pas la puissance réelle d’un processeur car un autre facteur de vélocité de calcul est l’échange de données en mémoire, non prise en compte ici.
L’exemple de BNP Paribas introduit d’autres avantages que les performances de calculs. En effet, un GPU consomme peu, n’est pas très onéreux et occupe peu d’espace.
Le tableau ci-dessous compare GPUs et CPUs en termes de puissance, prix, consommation électrique et dimension.
| Fabricant | Type | Modèle | Gflos (DP*) | Prix | Watt (Max TDP**) | Dimension |
|---|---|---|---|---|---|---|
| Single CPU/GPU | ||||||
| Nvidia | GPU (448 cœurs) | Tesla C2070 | 515 | 2500 $ | 238 W | |
| Nvidia | GPU (448 cœurs) | GeForce 570 GTX | 198 | 350 $ | 218 W | |
| Intel | CPU (10 cœurs) | Xeon E7-8870 | 96 | 4616 $ | 130 W | |
| Intel | CPU (6 cœurs) | Core I7-970 | 94 | 583 $ | 130 W | |
| IBM | CPU (8 cœurs) | Power 7 | 265 | 34 152 $ | 1700 W | 4U |
| Quad CPU/GPU | ||||||
| Nvidia | 4xGPU (1792 cœurs) | Tesla S2050 | 2060 | 12 000 $ | 900 W | 1U |
| IBM | 4xGPU (32 cœurs) | Power 7 | 1060 | 101 952 $ | 1700 W | 4U |
* : Double Précision ** : Thermal Design Power
Comparaison du coût d’un GigaFlop
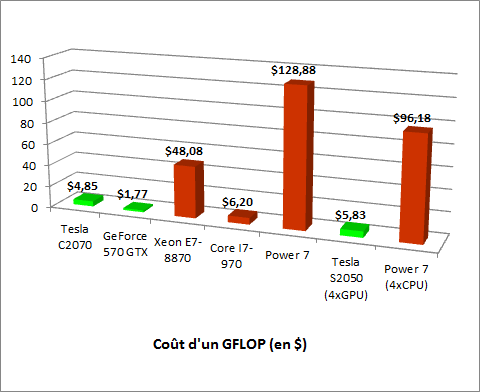
En termes de rapport prix/puissance, les cartes Nvidia sont, de loin, les plus intéressantes. Dans ce comparatif, seul le processeur, Intel Core i7-970 tire son épingle du jeu. Le dispositif le moins coûteux est la GeForce 570-GTX, bien connue des gamers, mais non prévue pour un usage professionnel. Les cartes Tesla se montrent les plus économiques pour ce type d’usage, en plus d’être les plus puissantes par unité.
Comparaison de la consommation électrique par GigaFlop
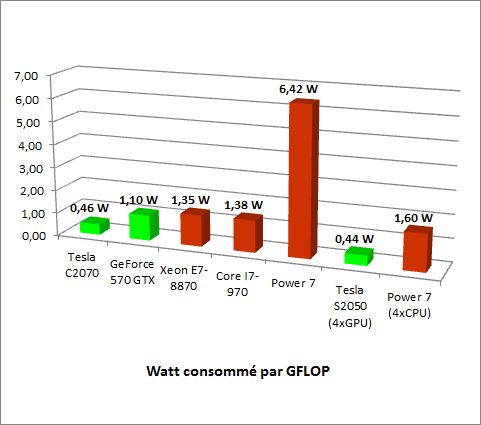
Les résultats obtenus sont comparables aux précédents, les cartes de la firme de Santa-Clara sont celles qui ont un meilleur rendement électrique pour fournir une puissance donnée. Une consommation électrique inférieure entrainera irrémédiablement une baisse du dégagement calorifique d’où un besoin de refroidissement moindre, paramètre lui aussi à prendre en compte dans un datacenter.
Coût sur 3 ans
Mettons ce résultat en perspective et calculons le coût par an de la consommation électrique pour chaque dispositif. Calculons aussi ce coût sur 3 ans en incluant le prix d’achat. Nous obtenons le tableau ci-dessous :
| Modèle | GFLOP | Coût sur un an ($) | Coût de la consommation électrique sur 3 ans + prix d'achat ($) |
|---|---|---|---|
| Tesla C2070 | 515 | 330,29 | 990,87 |
| GeForce 570 GTX | 198 | 316,1 | 948,3 |
| Xeon E7-8870 | 96 | 180,41 | 541,23 |
| Core I7-970 | 94 | 180,41 | 541,23 |
| Power 7 | 265 | 2 359,21 | 7 077,63 |
| Tesla S2050 (4xGPU) | 2060 | 1 248,99 | 3 746,97 |
| Power 7 (4xCPU) | 1060 | 2359,21 | 7 077,64 |
Le calcul du coût de la consommation électrique est basé sur :
- 0,1311€/kWh en heures pleines
- 0,0893€/kWh en heures creuses
- 24h = 16hp + 8hc
- Les coûts ont été convertis en $ pour inclure le prix du matériel (cours du 4 octobre 2011)
A l’aide de ce tableau, refaisons le calcul du coût d’un GigaFlop, incluant donc la consommation électrique sur 3 ans et le prix d’achat du matériel :
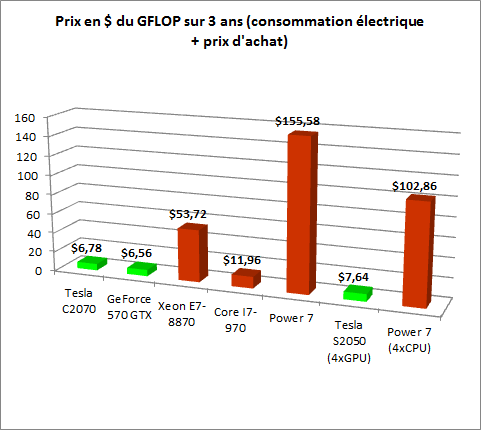
Pas de surprise ici, les cartes de la firme au caméléon s’en sortent encore le mieux.
Le dernier élément de comparaison est l’espace occupé. Le système Tesla S2050 est au format 1U (19" x 1.75" x 17.7") et délivre 2TFlop. Le power 7, même en configuration 4 CPU prend 4 fois plus d’espace mais avec une puissance de calcul 2 fois moindre, donc 8 fois plus encombrant pour une même puissance.
De même, si nous voulons la même puissance de calcul qu’un système S2050 à base de Xeon, nous aurons probablement besoin de 6 racks 1U, chacun supportant 4 processeurs, donc 6 fois plus volumineux qu’une solution Nvidia. Le gain de place peut ne pas être négligeable, en fonction du prix du prix du m². Au Japon par exemple, ce critère peut-être déterminant.
Architecture d’un GPU versus CPU
Une telle architecture est dite « orientée débit ». La dernière en date de la firme de Santa-Clara, nom de code « Fermi » comptabilise 512 cœurs.
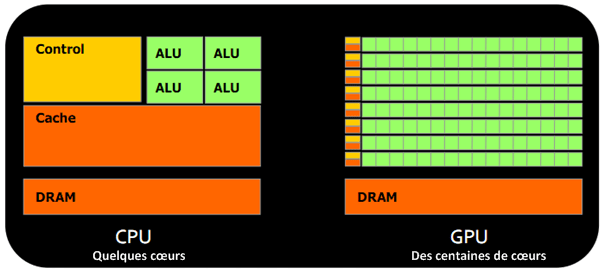
Architecture CPU vs. GPU
Les microprocesseurs traditionnels (CPU) sont essentiellement « orientés basse latence ». Le but est de minimiser le temps d’exécution d’une seule séquence d’un programme en réduisant la latence autant que possible. Ce design prend l’hypothèse traditionnelle que le parallélisme dans les opérations que doivent effectuer le processeur est très rare.
Les processeurs orientés débit posent comme hypothèse que leur charge de travail nécessite un parallélisme important. L’idée n’est pas d’exécuter les opérations le plus rapidement possible séquentiellement, mais d’exécuter des milliards d’opérations simultanément en un temps donné, le temps d’exécution d'une de ces opérations est finalement presque sans importance. Dans un jeu vidéo par exemple, les performances se mesurent en FPS (Frames Per Seconds). Pour cela, il faut qu’une image, avec tous les pixels, s’affichent tous les 30 millisecondes (environ). Peu importe le temps d’affichage d’un seul pixel.
Ce type de processeur a de petites unités de calculs indépendantes qui exécutent les instructions dans l’ordre où elles apparaissent dans le programme, il y a finalement peu de contrôle dynamique sur l’exécution. On utilise le terme SIMD pour ces processeurs (Single Instruction Multiple Data).
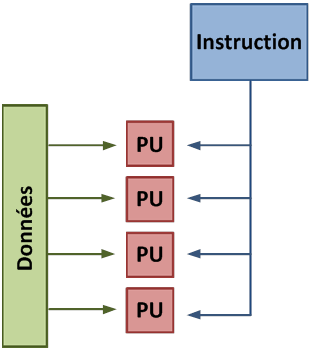
Mode de fonctionnement SIMD
Chaque PU (Processing Unit) ne correspond pas nécessairement à un processeur, ce sont des unités de calculs. Dans ce mode, la même instruction est appliquée simultanément à plusieurs données.
Moins de logique de contrôle implique plus de place sur le chip dédié au calcul. Cependant, cela a aussi un coût. Une exécution SIMD obtient un pic de performance quand les tâches parallèles suivent la même branche d’exécution, qui se détériore quand les tâches se séparent en branches. En effet, les unités de calcul affectées à une branche devront attendre l’exécution des unités de calcul de la branche précédente. Il en résulte une sous-utilisation matérielle et une augmentation du temps d’exécution. L’efficacité de l’architecture SIMD dépend de l’uniformité de la charge de travail.
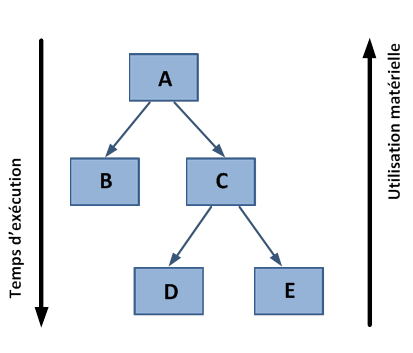
Cependant, du fait du grand nombre d’unités de calcul, il peut ne pas être très important d’avoir des threads bloqués si d’autres peuvent continuer leur exécution. Des opérations à longue latences effectuées sur un thread sont « cachées » par d’autres prêtes à exécuter une autre série d’instructions.
Pour un CPU quad ou octo cœurs la création de threads et leur ordonnancement a un coût. Pour un GPU, la relative latence « couvre » ces 2 étapes, ce qui les rend négligeables. Cependant les transferts de mémoire ont des conséquences plus importantes pour un GPU qu’un CPU à cause de la nécessité de déplacer les données entre la mémoire CPU et la mémoire GPU.
La technologie GPGPU, représentée majoritairement par Nvidia sur les segments professionnels semble répondre à certaines limitations que connaissent actuellement les fondeurs de CPU. Après ce premier article présentant les concepts fondamentaux du GPU Nvidia, j’expliquerai plus en détail les spécificités de la technologie CUDA dans un prochain billet.