Kafka Streams : encore un framework de stream processing ?
Dans les papiers des ingénieurs de Confluent.io depuis 2015, Kafka 0.10 est sorti en mai 2016. Peu après la sortie de la version 0.9 qui introduisait principalement l’API Kafka Connect, la version 0.10 apporte elle un composant majeur : Kafka Streams.
Encore un autre framework de stream processing ?
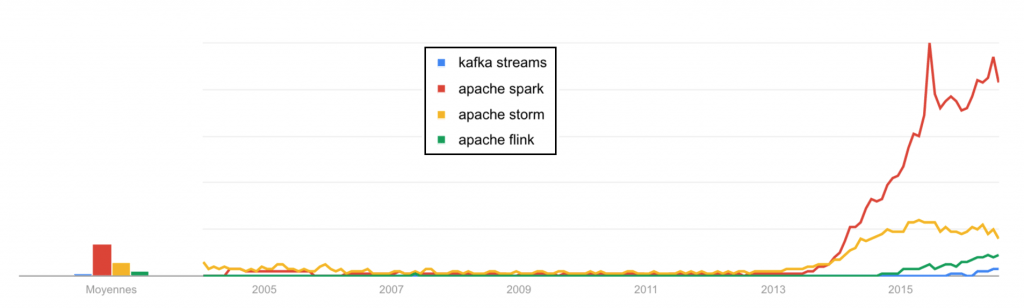
Il faut dire que depuis quelques années, de nombreux frameworks de stream processing orientés “big data” ont émergé. Capables d’évoluer dans l’écosystème Hadoop comme dans des environnements plus divers, les principaux “open-source” sont Samza, Storm, Spark, Flink ou encore plus récemment Héron. Bien souvent, ces frameworks évoluent de deux façons : soit ils montent en flèche, soit ils stagnent puis périssent, écrasés par d’autres moteurs délivrant des meilleures performances, une meilleure API, ou bien une meilleure stabilité. La concurrence est féroce, alors pourquoi ajouter sa pierre ?
Les cas d’usage streaming sont nombreux. Dans certains cas, utiliser un framework de stream processing peut être exagéré, car sa mise en place est synonyme d’un ou plusieurs middlewares de plus (habituellement un système master/slave), d’un gestionnaire de ressources, d’un grand nombre de dépendances, d’une nouvelle API à maîtriser, de complexité opérationnelle…
À l’inverse, utiliser les librairies clientes de Kafka et traiter les données « à la main » en développant sa propre application peut être fastidieux. Gérer la distribution, le sharding, l’ajout ou le retrait de ressources à chaud, la reprise sur erreur ou le redéploiement applicatif sont des vrais sujets.
Kafka Streams se positionne au juste milieu en venant proposer une librairie ultra-légère, complètement basée sur les clients Kafka, ainsi qu’une API, Kafka Streams DSL qui permet à l’utilisateur de décrire d’une manière fonctionnelle les opérations à effectuer sur les flux, tout en abstrayant la manière dont cela est réalisé. L’API en Java 8 permet un code élégant et léger, notamment grâce aux lambdas.
Exemple de code
Avant de détailler les possibilités offertes par l’API, prenons un exemple. Nous avons en entrée un flux Kafka d’évènements décrivant des achats, contenant un identifiant de produit et le prix d’achat de ce produit. Une table référentiel permet d’associer le libellé d’un produit à son identifiant. Nous voulons en sortie un flux enrichi du libellé produit, c’est à dire un flux dénormalisé contenant l’identifiant produit, le libellé correspondant à ce produit et son prix d’achat. Voici un exemple de code pour répondre à ce problème :
// Initialisation des ser/déserialiseurs pour lire et écrire dans les topics Serde<ProduitBrut> produitBrutSerde = Serdes.serdeFrom(new JsonSerializer<>(), new JsonDeserializer<>(ProduitBrut.class)); Serde<ProduitEnrichi> produitEnrichiSerde = Serdes.serdeFrom(new JsonSerializer<>(), new JsonDeserializer<>(ProduitEnrichi.class)); Serde<Referentiel> referentielSerde = Serdes.serdeFrom(new JsonSerializer<>(), new JsonDeserializer<>(Referentiel.class));
// Création d'un KStream (flux) à partir du topic "achats" KStream<String, ProduitBrut> achats = builder.stream(Serdes.String(), produitBrutSerde, "achats");
// Création d'une KTable (table) à partir du topic "referentiel" KTable<String, Referentiel> referentiel = builder.table(Serdes.String(), referentielSerde, "referentiel"); KStream<String, ProduitEnrichi> enriched = achats // Re-partitionnement du flux avec la nouvelle clé qui nous permettra de faire une jointure .map((k, v) -> new KeyValue<>(v.getId().toString(), v)) // Jointure du flux d'achats avec le référentiel .leftJoin(referentiel, (achat, ref) -> { if (ref == null) return new ProduitEnrichi(achat.getId(), "REF INCONNUE", achat.getPrice()); else return new ProduitEnrichi(achat.getId(), ref.getName(), achat.getPrice()); });
// On publie le flux dans un topic "achats-enrichis" enriched.to(Serdes.String(), produitEnrichiSerde, "achats-enrichis");
// Enfin, on démarre l'application KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration); streams.start();
Avant de rentrer dans les détails, où est-ce que ce morceau de code va-t-il être exécuté ?
Le cluster le plus simple du monde
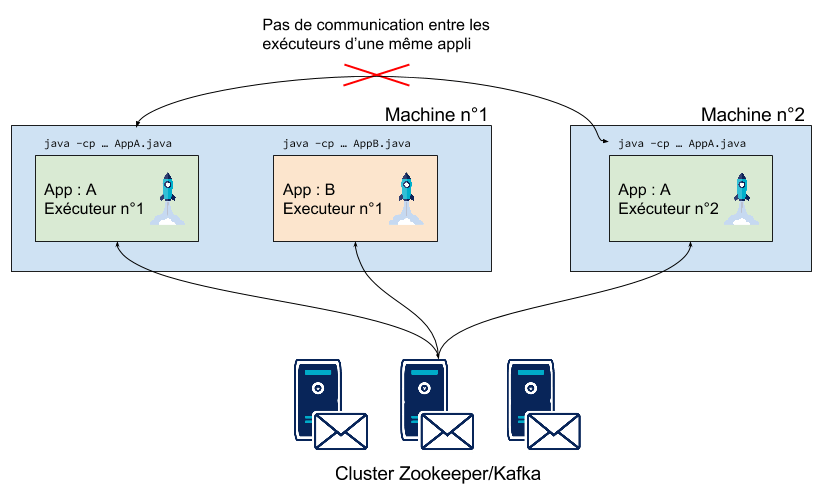
À première vue, ce n’est pas très clair, on se demande si la version 0.10 de Kafka inclut dans chacun des brokers des exécuteurs permettant de traiter les streams. Cela serait pratique du point de vue opérationnel, mais douteux car les performances des brokers pourraient être dégradées par les exécuteurs co-localisés.
Et bien, non ! Les brokers n’embarquent pas d’exécuteurs. Les applications KStreams sont en fait standalones : ce sont de simples programmes Java pouvant être déployés en parallèle sur plusieurs machines. Chaque application KStreams est donc un ensemble de JVMs qui elles mêmes contiennent un ou plusieurs “stream threads” : ce sont les threads qui sont en charge d’exécuter les différentes tâches de la topologie définie par l’utilisateur. Les différentes JVMs d’une même application KStreams (et même les stream threads d’une même JVM) ne communiquent pas entre eux ! Chaque stream thread fonctionne de manière indépendante vis à vis des autres stream threads. Pour des raisons de simplification, nous appellerons un stream thread “exécuteur”. Nous pouvons alors dire qu’une application est constituée d’un ensemble d’exécuteurs répartis sur une ou plusieurs JVMs.
Comment ça marche, « under the hood » ?
Kafka est un système dont les études montrent qu’il est capable d’absorber de grandes quantités de messages en peu de temps par rapport à d’autres messagers. Mais c’est aussi un système dont il faut tirer parti du design pour ne pas plomber ses performances. Nous allons prendre le simple exemple d’une jointure pour décrire le cheminement de la donnée et comprendre comment un tel système peut « scaler » quasi linéairement.
Partons de la base. La plus petite unité de parallélisme dans un topic Kafka est la partition. Le nombre de partitions représente le potentiel de parallélisme. Chaque partition est possédée par un seul broker Kafka, et un Broker Kafka peut posséder plusieurs partitions.

Le partitionnement est régi ainsi :
- C’est le producteur d’un message qui, via la clé du message et un partitionneur détermine dans quelle partition le message va être envoyé. Nous utiliserons le partitionneur par défaut pour tous nos producteurs, pour tous les topics.
- Deux topics ayant le même nombre de partitions sont partitionnés identiquement. C’est à dire que si deux messages dans deux topics A et B ont la même clé, alors le numéro de la partition du topic A contenant le premier message est le même que celui de la partition du topic B contenant le deuxième message.
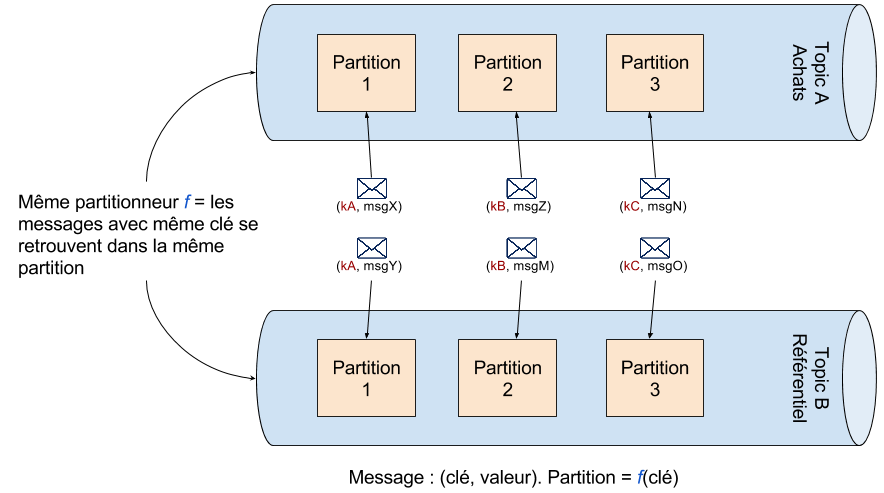
L’opération de jointure est une opération par clé. Dans ce cas, le partitionnement garantit que joindre deux flux revient à joindre une à une chacune des partitions de ces flux entre elles. Si les flux ont chacun n partitions, la jointure peut alors s’effectuer avec un degré de parallélisme de n. En revanche, si les flux n’ont pas le même nombre de partitions, il sera impossible de faire la jointure ! Et c’est sur ce principe que repose la puissance de Kafka Streams : les partitions à traiter sont distribuées équitablement entre les exécuteurs. Ainsi, une partition est traitée par un seul exécuteur, et un exécuteur peut traiter une ou plusieurs partitions.
La répartition des consommateurs d’une même application s’effectue par le partage d’un group.id associé au nom de l’application. Tous les consommateurs (issus des exécuteurs) possédant le même group.id se verront répartir dynamiquement les partitions afin de garantir que chaque partition ne possède qu’un seul consommateur (exécuteur) et que toutes les partitions soient traitées. Ce mécanisme de répartition est géré par les brokers Kafka.
Par exemple, si un topic possède 4 partitions et que l’on démarre deux instances de l’application, la première instance se verra attribuer les partitions 1 et 3, alors que la deuxième instance consommera les partitions 2 et 4.
KStreams et KTables
Deux types de streams existent dans l’API : les KStreams et les KTables. Les KTables sont des Streams « finis », ou encore selon la nomenclature de Kafka : « compactés ». Alors qu’un KStream représente un topic Kafka « infini », une KTable est un topic pour lequel chaque nouveau message clé/valeur écrase l’ancien message avec la même clé, ou insère le message si la clé est nouvelle. Ce n’est finalement qu’une simple Map <clé,valeur>.
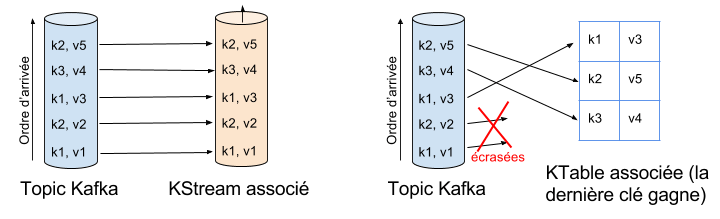
Dans notre exemple, le référentiel des mappings entre les identifiants produit et les libellés associés peut parfaitement être représenté par une KTable. Si l’on décide de mettre à jour le libellé d’un produit du référentiel, l’injection d’un nouveau message écrasera l’ancien ! La politique de log compaction de Kafka nous garantit que nos tuples ne seront pas effacés, contrairement à un topic non compacté qui voit ses messages effacés après 7 jours, par défaut.
Lorsqu’une application travaillant avec des KTables démarre, elle lit entièrement le topic depuis l’offset où elle s’était arrêtée (de la fin par défaut, si elle démarre pour la première fois), puis stocke les messages dans une instance RocksDB qui est un cache persisté et local à chaque JVM. Elle reste ensuite à l’écoute du topic pour insérer tout nouveau message dans son cache.
Pour une instance d’une application KStreams, joindre un KStream(topic achats) et une KTable(topic referentiel) revient donc à :
- lire et mémoriser dans un cache l’ensemble des partitions assignées du topic « réferentiel ».
- joindre chaque tuple provenant des partitions assignées du topic « achats » à la volée avec un tuple de la KTable référentiel.
Cas pratique : retour sur l’exemple de code
Reprenons l’exemple d’enrichissement du flux d’achats :
// Création d'un KStream (flux) à partir du topic "achats" KStream<String, ProduitBrut> achats = builder.stream(Serdes.String(), produitBrutSerde, "achats");
// Création d'une KTable (table) à partir du topic "referentiel" KTable<String, Referentiel> referentiel = builder.table(Serdes.String(), referentielSerde, "referentiel"); KStream<String, ProduitEnrichi> enriched = achats // Re-partitionnement du flux avec la nouvelle clé qui nous permettra de faire une jointure .map((k, v) -> new KeyValue<>(v.getId().toString(), v)) // Jointure du flux d'achats avec le référentiel .leftJoin(referentiel, (achat, ref) -> { if (ref == null) return new ProduitEnrichi(achat.getId(), "REF INCONNUE", achat.getPrice()); else return new ProduitEnrichi(achat.getId(), ref.getName(), achat.getPrice()); });
// On publie le flux dans un topic "achats-enrichis" enriched.to(Serdes.String(), produitEnrichiSerde, "achats-enrichis");
// Enfin, on démarre l'application KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration); streams.start();
Supposons que le flux d’entrée est constitué ainsi : <id_transaction; produitBrut>. id_achat est le numéro du ticket. produitBrut possède un attribut id_produit avec la référence du produit. Nous souhaitons joindre ce flux avec la KTable référentiel en utilisant comme clé id_produit. Nous devons donc transformer le flux et émettre le même message avec la clé id_produit extrait de ProduitBrut plutôt que id_achat. Or cette opération perturbe le partitionnement : un message sur une partition donnée voit sa clé changer, ce qui l’amène très probablement à devoir être géré par une autre partition ! La jointure ne peut plus avoir lieu. Essayez vous-même, vous obtiendrez le message d’erreur suivant:
Invalid topology building: KSTREAM-MAP-0000000003 and KTABLE-SOURCE-0000000002 are not joinable.
Comment faire alors ? Comme dans tout système distribué, il faut à un moment ou à un autre avoir recours à un « shuffle », c’est à dire une re-distribution des données entre les exécuteurs. Or nos exécuteurs ne communiquent pas entre eux. Le shuffle doit donc être indirect : il faut tout simplement ré-émettre chaque message avec sa nouvelle clé sur un tout nouveau topic, et consommer de ce nouveau topic pour effectuer la jointure. Le morceau de code devient :
// Création d'un KStream (flux) à partir du topic "achats" KStream<String, ProduitBrut> achats = builder.stream(Serdes.String(), produitBrutSerde, "achats");
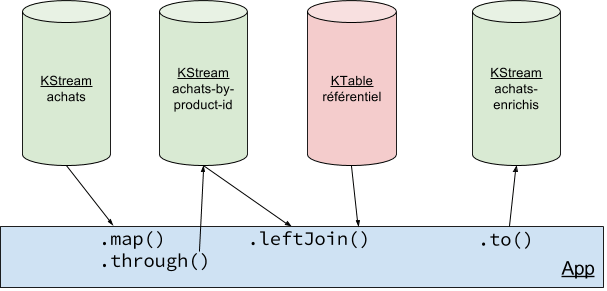
// Création d'une KTable (table) à partir du topic "referentiel" KTable<String, Referentiel> referentiel = builder.table(Serdes.String(), referentielSerde, "referentiel"); KStream<String, ProduitEnrichi> enriched = achats // Re-partitionnement du flux avec la nouvelle clé qui nous permettra de faire une jointure .map((k, v) -> new KeyValue<>(v.getId().toString(), v)) // Copie du flux vers un nouveau topic, avec la nouvelle clé .through(Serdes.String(), produitBrutSerde, "achats-by-product-id") // Jointure du flux d'achats avec le référentiel .leftJoin(referentiel, (achat, ref) -> { if (ref == null) return new ProduitEnrichi(achat.getId(), "REF INCONNUE", achat.getPrice()); else return new ProduitEnrichi(achat.getId(), ref.getName(), achat.getPrice()); });
// On publie le flux dans un topic "achats-enrichis" enriched.to(Serdes.String(), produitEnrichiSerde, "achats-enrichis");
// Enfin, on démarre l'application KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration); streams.start();
La méthode « through » revient à forcer l’opération de « shuffle » en utilisant un topic Kafka intermédiaire pour re-partitionner le flux. Et maintenant, ça fonctionne !
En bonus
- Les KStreams permettent aussi d’effectuer des opérations fenêtrées sur des flux en gérant plusieurs types de fenêtres, avec trois systèmes d’extraction de timestamps pour couvrir un maximum de cas d’usages.
- Il est possible de travailler avec des états (stateful processing).
- La sémantique par défaut est “at least once”.
- En cas de panne d’un des exécuteurs, un mécanisme de reprise intrinsèque au consommateur Kafka se met en place automatiquement. Ce même mécanisme permet l’ajout ou retrait de ressources à chaud.
- Les KTables sont “backées” par RocksDB par défaut, mais cela peut être remplacé par toute autre implémentation de org.apache.kafka.streams.state.KeyValueStore.
- Plusieurs stratégies existent pour créer les topics Kafka nécessaires au fonctionnement de l’application. Je préconise de le faire au moment du déploiement de l’application.
Conclusion
Les développeurs de Confluent n’ont pas réinventé la roue : l’API KStreams est un moyen simple de faire du streaming, en s’appuyant le plus possible sur les composants et concepts existants dans Kafka. De ce fait, le projet ne contient en fait que quelques milliers de lignes de code !
Développer et faire tourner son application de streaming ne nécessite pas d’ajout de middleware en plus. La gestion du cluster d’exécuteurs Java de votre application est cependant entre vos mains. Les cas d’usage plus complexes nécessitant par exemple de l’apprentissage pour un modèle de machine learning ne pourront certainement pas s’appuyer sur cette API, car trop légère.
Retrouvez le code source de l’exemple utilisé sur ce Github pour pouvoir le faire tourner chez vous en quelques minutes, avec ou sans Docker.
Merci Sebastián pour ton coup de pouce Docker, et bien sûr merci les Octos pour vos précieuses relectures !