Jusqu’où peut aller un simple ordinateur de bureau avec une application web java réactive ?

Les promesses de la programmation réactive : permettre de gérer sur une même machine beaucoup plus de connexions en parallèle et de traiter plus de requêtes par seconde, ceci avec peu de threads donc beaucoup moins de mémoire et de CPU qu’avec les modes de programmation classiques.
Nous avons réalisé 3 versions d’une application de test :
- version servlet classique : servlet et appel d’un web service avec Apache HttpClient
- version servlet asynchrone 3.0 : servlet asynchrone et appel d’un web service avec Apache HttpAsyncClient
- version 100% réactive : serveur HttpCore NIO et appel d’un web service avec Apache HttpAsyncClient
Ensuite nous avons soumis ces trois versions à des tests de charge particulièrement agressifs pour voir ce qu’elles pouvaient supporter.
Comment tester ?
Les tests ont été réalisés avec Apache Benchmark
Quelle charge viser ?
Pour se donner une idée, voici quelques chiffres provenant des géants du web. Par seconde :
- Google : 33 000 recherches
- Facebook : 41 000 post, 30 000 like
- Twitter : 4 600 twits
Source : what happens in just ONE minute on the internet
En termes de connexions simultanées, on considère habituellement que le défi ultime pour un serveur web est d'arriver à supporter 10 000 connections en parallèle : c'est le fameux C10k problem. On peut aller un peu plus loin mais pas beaucoup en fait car le nombre de connexions simultanées vers une même machine est en principe limité par le nombre de ports TCP disponibles soit 65 536. D’ailleurs Apache Benchmark lui-même supporte au maximum 20 000 connections simultanées.
Notre objectif : 10 000 connexions simultanées et 50 000 requêtes / seconde.
Les tests réalisés
Le principe est de simuler une application web java. Pour chaque requête utilisateur, cette application va interroger un web service et afficher le résultat à l'utilisateur.
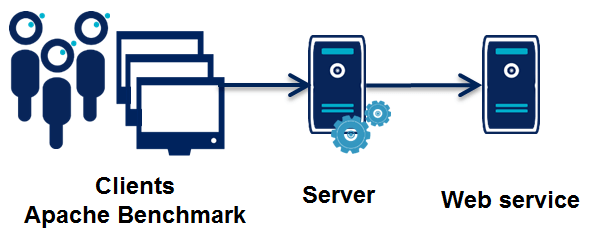
Tout le code utilisé pour les tests est disponible ici : https://github.com/fxbonnet/nio-benchmark
La machine : un PC portable de bureau (pas un serveur !)
- Processeur Intel Core i7-3517U 1.90GHz 2 coeurs, 4 hard-threads
- Ubuntu 13.10 (3.11.0-12.19 Ubuntu Linux kernel)
- Réseau : tests effectués en local
- OpenJDK 1.7.0_51 (OpenJDK Runtime Environment (IcedTea 2.4.4) (7u51-2.4.4-0ubuntu0.13.10.1) OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode))
Préparation de l’injecteur
D’abord un petit test à vide d’Apache Benchmark :
ab -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
socket: Too many open files (24)
La machine n’est pas prête à supporter autant de connexions en même temps. Quelques réglages s’imposent en commençant par augmenter les valeurs dans le fichier /etc/security/limits.conf
# Increases the number of open files by user * hard nofile 65536 * soft nofile 65536 root hard nofile 65536 root soft nofile 65536
Deuxième essai :
ab -r -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient)
Test aborted after 10 failures
apr_socket_connect(): Cannot assign requested address (99)
Des réglages plus approfondis s’imposent pour permettre un recyclage des ports plus rapide. On modifie donc le fichier /etc/sysctl.conf (le fichier est disponible avec le code source des tests sur Github) et on en profite pour ajuster les tailles de buffers et autres paramètres recommandés pour des machines devant supporter un fort traffic réseau.
Pour la suite on va aussi ajouter l’argument -k dans la ligne de commande afin de permettre à Apache Benchmark de faire du keep-alive sur les connexions ce qui devrait aussi permettre d’aller plus loin.
Troisième essai :
ab -r -k -c10000 -n1000000 http://localhost:8080/ This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient) Completed 100000 requests Completed 200000 requests Completed 300000 requests Completed 400000 requests Completed 500000 requests Completed 600000 requests Completed 700000 requests Completed 800000 requests Completed 900000 requests Completed 1000000 requests Finished 1000000 requests
Server Software: Server Hostname: localhost Server Port: 8080
Document Path: / Document Length: 0 bytes
Concurrency Level: 10000 Time taken for tests: 12.004 seconds Complete requests: 1000000 Failed requests: 1529850 (Connect: 0, Receive: 1019900, Length: 0, Exceptions: 509950) Write errors: 0 Non-2xx responses: 49 Keep-Alive requests: 49 Total transferred: 5194 bytes HTML transferred: 0 bytes Requests per second: 83302.25 [#/sec] (mean) Time per request: 120.045 [ms] (mean) Time per request: 0.012 [ms] (mean, across all concurrent requests) Transfer rate: 0.42 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 0 0.2 0 227 Processing: 0 116 116.3 120 266 Waiting: 0 0 1.6 0 252 Total: 0 116 116.3 120 477
Percentage of the requests served within a certain time (ms) 50% 120 66% 230 75% 232 80% 233 90% 236 95% 240 98% 246 99% 251 100% 477 (longest request)
Cette fois-ci, ça passe. On peut observer l'utilisation CPU :
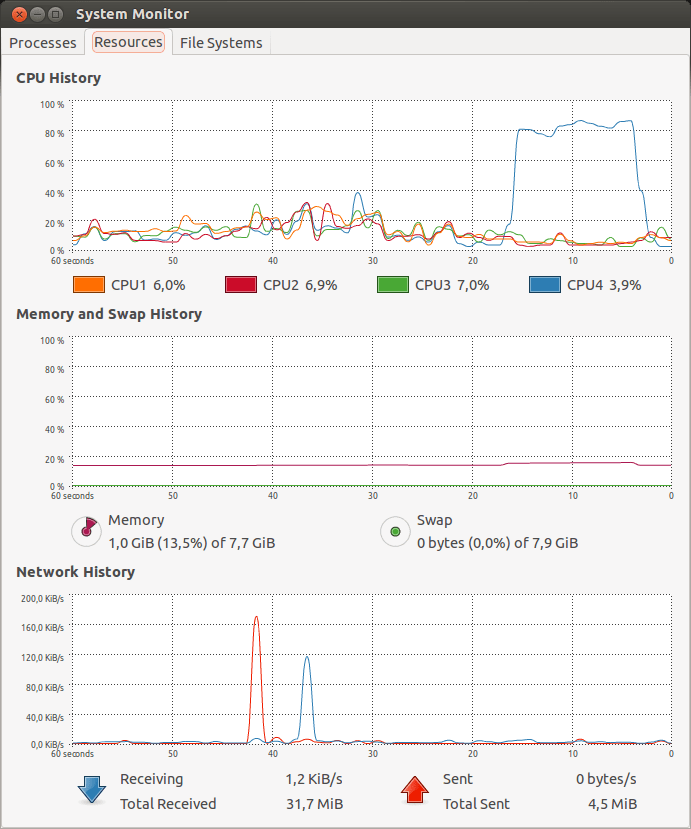
On voit deux choses intéressantes :
- Apache Benchmark arrive à monter à plus de 83 000 requêtes/seconde ce qui est largement suffisant par rapport à notre objectif.
- Il n’a besoin pour cela d’utiliser qu’un seul hard-thread, nos applications pourront utiliser les 3 hard-threads restants.
Préparation du web service utilisé pour les tests
Ce service est implémenté à l'aide d'Apache HttpCore NIO. Il est lui aussi monothread, ce qui laissera les deux dernier hard-threads pour notre application à tester.
Techniquement le service renvoit une vraie réponse HTTP. On peut le tester à l’aide d’un navigateur.
Testons le avec Apache Benchmark :
ab -r -k -c10000 -n1000000 http://localhost:8081/war/hello This is ApacheBench, Version 2.3 <$Revision: 1430300 @@ARTICLE_CONTENT@@gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient) Completed 100000 requests Completed 200000 requests Completed 300000 requests Completed 400000 requests Completed 500000 requests Completed 600000 requests Completed 700000 requests Completed 800000 requests Completed 900000 requests Completed 1000000 requests Finished 1000000 requests
Server Software: Server Hostname: localhost Server Port: 8081
Document Path: /war/hello Document Length: 11 bytes
Concurrency Level: 10000 Time taken for tests: 24.268 seconds Complete requests: 1000000 Failed requests: 0 Write errors: 0 Keep-Alive requests: 1000000 Total transferred: 151000000 bytes HTML transferred: 11000000 bytes Requests per second: 41206.84 [#/sec] (mean) Time per request: 242.678 [ms] (mean) Time per request: 0.024 [ms] (mean, across all concurrent requests) Transfer rate: 6076.40 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 11 300.7 0 15035 Processing: 55 224 52.3 195 594 Waiting: 55 224 52.3 195 594 Total: 165 235 307.3 195 15381
Percentage of the requests served within a certain time (ms) 50% 195 66% 248 75% 274 80% 279 90% 294 95% 332 98% 351 99% 369 100% 15381 (longest request)
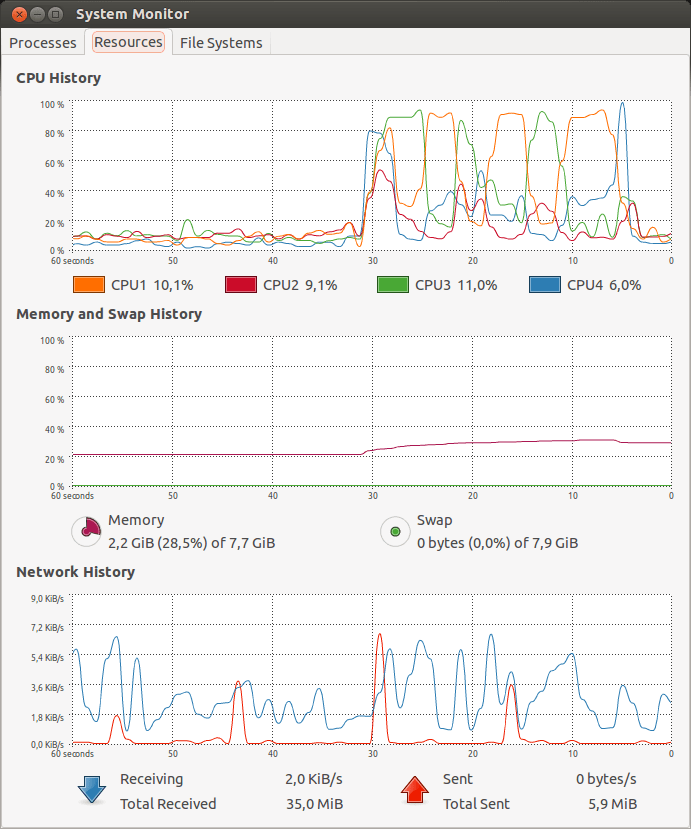
Le service arrive à traiter plus de 40 000 requêtes/seconde et il reste suffisamment de CPU disponible pour nos applications de test.
Préparation des applications de test
Commençons par la version servlet classique :
@Override protected void doGet(final HttpServletRequest request, final HttpServletResponse response) throws IOException { HttpGet httpGet = new HttpGet(HelloServer.SLOW_HELLO_URL); CloseableHttpResponse httpClientResponse = httpClient.execute(httpGet); try { String result = EntityUtils.toString(httpClientResponse.getEntity()); response.getWriter().write(result); } finally { httpClientResponse.close(); } }
Puis la version servlet asynchrone (les servlets asynchrones sont apparues dans la spécification Servlet 3.0). Pour faire réellement du réactif, elle utilise également un client HTTP asynchrone. Le code est donc un peu plus compliqué :
@Override protected void doGet(final HttpServletRequest request, final HttpServletResponse response) { final AsyncContext asyncContext = request.startAsync(); HttpGet httpGet = new HttpGet(HelloServer.SLOW_HELLO_URL); FutureCallback<HttpResponse> responseCallback = new FutureCallback<HttpResponse>() { @Override public void completed(final HttpResponse httpClientResponse) { try { String result = EntityUtils.toString(httpClientResponse.getEntity()); response.getWriter().write(result); } catch (IOException e) { sendError(e, response); } finally { asyncContext.complete(); } }
@Override
public void failed(final Exception e) {
sendError(e, response);
}
@Override
public void cancelled() {
}
};
httpClient.execute(httpGet, responseCallback);
}
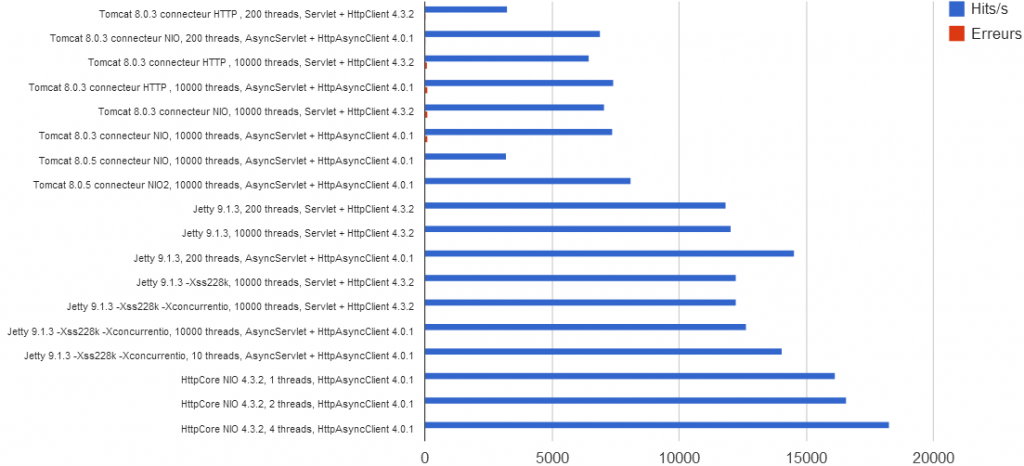
Résultats des tests
| Configuration serveur | Threads | Application | Hits/s | % erreurs1 |
|---|---|---|---|---|
| Tomcat 8.0.3 connecteur HTTP | 200 | Servlet + HttpClient 4.3.2 | 3 250 | 0,8 |
| Tomcat 8.0.3 connecteur NIO | 200 | AsyncServlet + HttpAsyncClient 4.0.1 | 6 926 | 0,3 |
| Tomcat 8.0.3 connecteur HTTP | 10 000 | Servlet + HttpClient 4.3.2 | 6 456 | 1,3 |
| Tomcat 8.0.3 connecteur HTTP | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 7 433 | 1,7 |
| Tomcat 8.0.3 connecteur NIO | 10 000 | Servlet + HttpClient 4.3.2 | 7 053 | 1,5 |
| Tomcat 8.0.3 connecteur NIO | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 7 405 | 1,6 |
| Tomcat 8.0.5 connecteur NIO | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 3 206 | 0,6 |
| Tomcat 8.0.5 connecteur NIO2 | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 8 108 | 0,05 |
| Jetty 9.1.3 | 200 | Servlet + HttpClient 4.3.2 | 11 834 | - |
| Jetty 9.1.3 | 10 000 | Servlet + HttpClient 4.3.2 | 12 066 | - |
| Jetty 9.1.3 | 200 | AsyncServlet + HttpAsyncClient 4.0.1 | 14 543 | - |
| Jetty 9.1.3 -Xss228k2 | 10 000 | Servlet + HttpClient 4.3.2 | 12 255 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio3 | 10 000 | Servlet + HttpClient 4.3.2 | 12 256 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio | 10 000 | AsyncServlet + HttpAsyncClient 4.0.1 | 12 664 | - |
| Jetty 9.1.3 -Xss228k -Xconcurrentio | 10 | AsyncServlet + HttpAsyncClient 4.0.1 | 14 065 | - |
| HttpCore NIO 4.3.2 | 1 | HttpAsyncClient 4.0.1 | 16 137 | - |
| HttpCore NIO 4.3.2 | 2 | HttpAsyncClient 4.0.1 | 16 600 | - |
| HttpCore NIO 4.3.2 | 4 | HttpAsyncClient 4.0.1 | 18 291 | - |
1 les erreurs correspondent à des socket timeout, c’est à dire quand Apache Benchmark n’a pas reçu de réponse au bout de 30 secondes.
2 l’option -Xss permet de définir la taille de la stack associée à chaque thread. En la réduisant, on réduit la mémoire utilisée par chaque thread. http://www.oracle.com/technetwork/java/hotspotfaq-138619.html#threads_oom
3 l’option -Xconcurrentio améliore en théorie les performances des applications qui utilisent un grand nombre de threads, du moins sur certains systèmes. http://www.oracle.com/technetwork/java/hotspotfaq-138619.html#threads_general
NB : environ 30 s sont nécessaires à Tomcat pour remplir son pool de 10 000 threads et 2 Go de RAM sont nécessaires, il a donc fallu ajouter l’option -Xmx2048m au démarrage de la JVM.
Analyse
- Le modèle 100% réactif est le plus performant avec environ 50% de requêtes traitées en plus par rapport à la meilleure application classique même bien tunée.
- Le modèle servlet asynchrone permet de gagner entre 5% et 20% par rapport au modèle classique. Peut-être parce qu’il n’est pas 100% réactif (on ne passe en mode asynchrone qu’en cours de traitement à la fin de la méthode doGet() mais il a quand même fallu initialement allouer un thread du pool du conteneur).
- A architecture strictement identique une application réactive sera plus performante avec 10 threads qu’avec 10 000 ! (cf. tests avec Jetty, avec 10 threads 14 065 hits/s, avec 10 000 threads 12 664 hits/s soit 10% moins ).
- Sans surprise, les meilleurs résultats sont obtenus en dimensionnant le nombre de threads au nombre de hard-threads de la machine (cf. tests avec HttpCore NIO, 18 291 hits/s est le meilleur score obtenu parmi tous les tests et il n’utilisait que 4 threads).
- Là où les applications classiques ont nécessité d’augmenter la taille des pools de threads et la mémoire, l’application réactive sélectionne elle-même par défaut la valeur optimale c’est à dire le nombre de threads disponible sur la machine et consomme très peu de mémoire.
- Les applications non réactives ont besoin d’un temps de chauffe non négligeable (30s) et de plus de mémoire (2 Go). Dans notre exemple, le pic de charge très brutal engendre des erreurs (timeout) alors que les applications réactives se sont bien comporté.
- Il y a des écarts importants entre serveur d’application (Tomcat ou Jetty) et même d’une version à l’autre. Le choix du connecteur dans Tomcat a un impact très fort.
Conclusions
Le modèle servlet asynchrone (introduit dans la version 3.0 de la spécification servlet) est intéressant car il permet des gains de performance significatif pour les traitements qui s’y prêtent. Par contre les serveurs d’applications classiques ne sont pas tous parfaitement préparés à ce type d’utilisations, des tests et des réglages sont nécessaires.
Le modèle 100% réactif est celui qui donne les meilleurs résultats (dans nos tests, un gain d’environ 50%).
On n’arrive pas encore aux chiffres des géants du web mais l’ordre de grandeur y est (10 000 connexions en parallèle mais seulement 18 000 requêtes/seconde alors que notre objectif était de 50 000 requêtes/seconde) mais il ne faut pas oublier que les tests ont été fait sur une seule machine 2 coeurs, 4 threads sur laquelle tournaient à la fois l’application de test, le web service de test et l’injecteur Apache Benchmark. C’est donc un résultat très encourageant. Dans des conditions réelles il faudrait aussi que le réseau soit capable de gérer ce flux (ici tous les tests ont été faits en local).
La programmation réactive a tenu ses promesses : plus de connexions en parallèle et plus de requêtes traitées par seconde en utilisant moins de mémoire et de CPU.
Vous voulez tester chez vous ? Rien de plus simple, tout le code utilisé pour les tests est disponible ici : https://github.com/fxbonnet/nio-benchmark