Introduction aux graphes avec Neo4j et Gephi
Les solutions permettant de modéliser, stocker et parcourir de façon efficiente des graphes ont profité de plusieurs éléments qui les ont rendues populaires ces dernières années.
Le premier élément aidant à leur démocratisation est l'explosion des réseaux sociaux. Un cas d’usage évident, facile à comprendre même si, étrangement, les solutions mises en œuvre ne sont pas forcément de « type graphe » (par exemple avec FlockDB chez Twitter).
Le second est lié au mouvement NoSQL qui a aidé à diffuser l'idée que la base relationnelle n'est pas la seule solution de stockage et de requêtage.
Enfin, et même si la théorie des graphes n'est pas neuve, les algorithmes sous-jacents et certaines implémentations ont atteint un niveau de maturité permettant la « commoditisation » de ces technologies, les aidant du même coup à sortir de zones très spécifiques.
Alors qu'est-ce qu'un graphe? A quoi cela peut-il bien servir? Et finalement comment travaille-t-on avec en termes d’API et de solution ?
A travers deux exemples simples, voici une introduction aux graphes, leur stockage et leur analyse, en utilisant Neo4j, une base de données graphe, et Gephi, un outil open-source de visualisation et d’analyse de graphe.
Qu'est-ce qu'un graphe?
Un graphe est une structure de données, associant entre eux des nœuds (ou sommets) par des relations. Ces relations sont appelées arcs si le graphe est orienté et arêtes s'il ne l'est pas. On parle de graphe orienté si les relations entre les nœuds ont une direction.
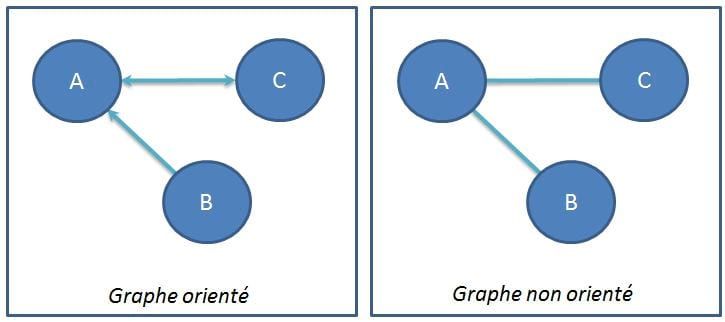
En fait un graphe est une structure de donnée un peu généralisée. Une liste peut être vue comme un graphe orienté, de la même manière un arbre binaire ou n-aire (chaque noeud peut avoir n fils) est un graphe. Il existe plusieurs types de graphes : directionnels, non directionnels, cycliques, arbres, hyper-graphes…
Les cas d'usages de graphes sont nombreux : le graphe social de Facebook qui représente les associations entre des personnes, le réseau LinkedIn qui est un graphe de relations entre des professionnels, Maven qui définit un graphe des dépendances d'une application, ou encore un cluster de machines, un graphe de routage réseau...
Un autre exemple qui démontre de l’apport de la théorie des graphes à l'informatique tel que nous la connaissons aujourd'hui est la gestion de la mémoire au sein de la JVM. En effet, la structure de donnée intégrant les objets au sein d'une JVM n'est autre qu'un graphe d'objets, où chaque objet est un nœud. Les associations entre ces objets (utilisation, héritage, implémentations) sont alors représentées par les liens entre ces nœuds. Ainsi représenté, le graphe objet est utilisé par le garbage collector (GC) qui se doit d'optimiser le parcours de son graphe pour libérer la mémoire...
C'est un problème d'algorithmie pure, particulièrement complexe, et c'est malheureusement ce qui engendre les très connues pauses de la JVM imposées par le garbage collector. Cet algorithme a été raffiné au fil des années. Par exemple, le graphe a été découpé en génération pour raccourcir les cycles GC. Mais les besoins en mémoire ne cessent d'augmenter et le graph grossit. Ainsi, un nouvel algorithme, nommé G1, a été conçu pour supporter de plus large mémoire.
Property graphs
L’enjeu de cet article n’étant pas de présenter tous les types de graphes et leurs cas d'usages, nous nous limiterons au type de graphes le plus riche et souple en termes de représentation: les « property graphs ».
Les « property graphs » sont un type de graphe particulier dans lequel à la fois les nœuds et les relations peuvent avoir des propriétés, ce qui offre donc un modèle de données entièrement dynamique. Neo4j est une implémentation de base de données utilisant une structure de property graph.
Ci-dessous, un exemple de « property graph » inspiré par les présentations historiques de Neo4j :
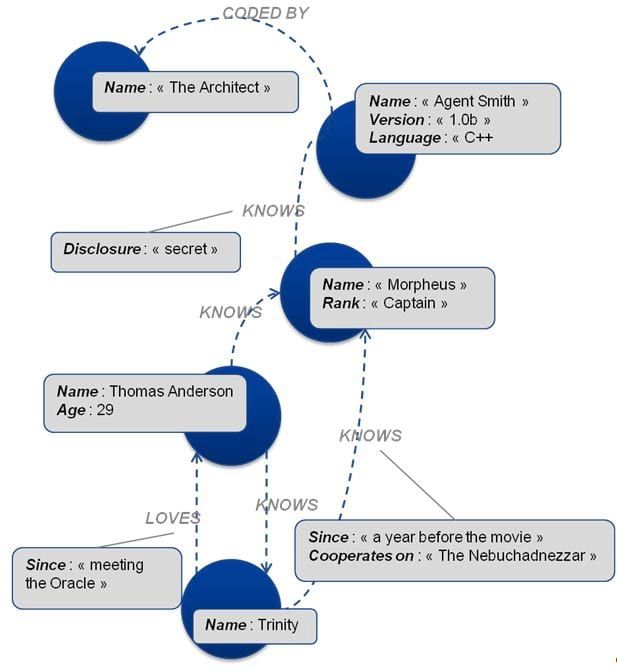
Comme le montre cet exemple, les relations peuvent être multiples et porter une sémantique différente (comme l’indique les relations entre « Trinity » et « Thomas Anderson »).
Requêtes et parcours de graphe
Avec une structure de données en graphe, il est possible de trouver des données de manière très puissante, en parcourant un graphe, c'est à dire en naviguant dans les relations. C'est là que le graphe prend toute sa puissance : trouver le plus court chemin entre deux nœuds, trouver – à partir d’un nœud donné – tous les nœuds ayant une relation « KNOWS » respectant certaines « properties » et étant éloigné au maximum de 3 « hops » ...
Sur une base de données graphe telle que Neo4j, on peut ainsi réaliser deux grands types de requêtes:
sélectionner les nœuds qui répondent à certains critères, du "pattern matching". Ceci présente peu de différences finalement avec ce qu'on saurait capable de faire avec une base relationnelle.
réaliser un parcours de graphe à partir d'un noeud donné
Si on compare une base de données graphe à une base de données relationnelles, on voit qu'il devient possible de réaliser des opérations qui étaient extrêmement coûteuses en performances dans un système relationnel : en combinant ainsi du requêtage assez proche des systèmes classiques et le parcours de graphe, il est possible de réaliser l’équivalent d’une requête SQL complexe utilisant des jointures dont la profondeur n’est pas connue à l’avance.
Exemple 1 : le graphe social des OCTOs
L’idée est simple : extraire de notre outil interne de suivi de l’activité l’ensemble des informations et représenter le graphe social « officiel » OCTO. Officiel car ce graphe représente l’information « qui a passé du temps avec qui en mission ». Reste qu’il est quasiment impossible de retracer les liens informels (sauf à les expliciter à un moment….)
Les choix en termes de modélisation sont également simples : les nœuds sont soit l’équivalent d’une Business Unit, soit un octo(wo)man.
On définit deux types de relations :
- « Belongs to » pour modéliser l’appartenance à une Business Unit
- « Works » pour modéliser la relation projet
En termes de propriétés sur les relations et les nœuds, on conserve le trigramme du collaborateur pour le nœud, et le projet qui lie les collaborateurs pour caractériser la relation.
La seule subtilité consiste à ajouter une propriété « Weight » sur les relations, qui cumule le nombre d’heures passées en projet.
Autrement dit :
- plus des OCTO auront passé du temps en mission ensemble, plus l’attribut Weight de leur relation projet sera forte,
- plus un OCTO aura participé à un nombre important de missions, plus il aura des liens (entrants ou sortants, la directionnalité ne nous intéressant pas dans ce cas).
Code permettant la création d’un nœud OCTO :
public Node createOcto(Octo octo, Node lobNode) {
Node node = null;
Transaction tx = graphDb.beginTx();
try {
node = graphDb.createNode();
node.setProperty("name", octo.getName());
node.setProperty("trigram", octo.getTrigram());
octoNameIndex.add(node, "name", octo.getName());
octoTrigramIndex.add(node, "trigram", octo.getTrigram());
node.createRelationshipTo(lobNode, RelTypes.IS_IN_LOB);
tx.success();
} finally {
tx.finish();
}
return node;
}
Code permettant la creation d’une relation “projet” entre deux noeuds
public Relationship linkOctos(final Node octoToLinkNode, final Node otherOctoNode, Project project, RelTypes type, Object value) {
Transaction tx = graphDb.beginTx();
Relationship relation = null;
try {
if (RelTypes.PROJECT.equals(type)) {
relation = octoToLinkNode.createRelationshipTo(otherOctoNode, RelTypes.PROJECT);
relation.setProperty("name", project.getName());
relation.setProperty("Weight", value);
relation.setProperty("Id", project.getReference());
relation.setProperty("Label", project.getReference());
} …
tx.success();
} finally {
tx.finish();
}
return relation;
}
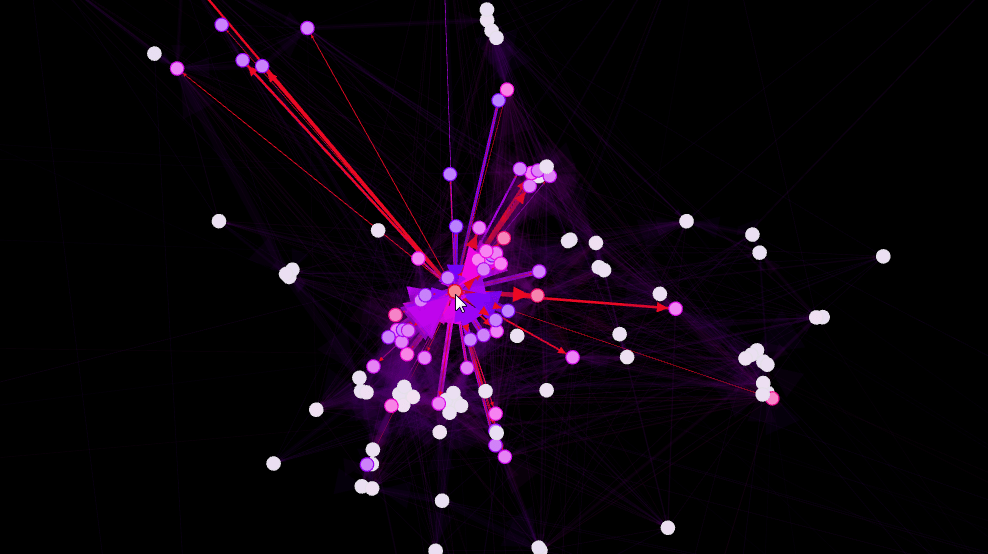
Une fois les données stockées dans Neo4j, on utilise le connecteur adapté pour traiter le graphe dans Gephi. Pour la "mise en forme" et la visualisation du graphe, nous avons utilisé un algorithme de clustering basé sur des forces d'attraction et répulsion, Force Atlas.

On détecte également et très rapidement des personnes qui interviennent sur beaucoup de projets (plus le nœud a une couleur qui tend vers le rouge, plus il a de liens entrants).
Exemple 2 : Analyse/Audit de code
Les audits d'architecture et de code sont très consommateurs de solutions comme Sonar, et JavaDepend ou NDepend suivant que l'on utilise Java ou .Net. Ces outils ont néanmoins quelques limitations :
- ils ne nous permettent pas toujours de bien détecter du code mort sur une analyse statique, entre autres à cause des problèmes induits par la programmation par interface (une classe qui utilise une interface voit l'interface comme dépendance et non l'implémentation), mais aussi par les frameworks qui font de l'injection de dépendance (on ne sait qu'à l'exécution ce qui sera réellement injecté et donc utilisé).
- ces outils ne proposent pas de vue d’ensemble de l’application nous montrant quelle classe ou quel composant utilise quoi dans l'application. En effet quand une application devient vraiment grosse, en avoir une bonne représentation visuelle s'avère difficile.
En somme, modéliser le code sous la forme d'un graphe permettrait de lever ces limitations et d'aider à l'analyse d'impacts.
Dans ce domaine, un logiciel open source intéressant est CDA (Class Dependencies Analyzer). Cet outil permet de charger les jars d'une application, et via le bytecode il est capable de reconstruire le graphe des dépendances de l'application, y compris par les interfaces. Par dépendances on entend : les dépendances d’héritage, d’implémentation mais également les dépendances d’import, de code (appels de méthodes, instanciation d’objets…).
Reste que la visualisation fournie par l'outil ne nous satisfait pas : pas d'analyse, pas de possibilité de grouper, visualisation uniquement d'une liste d'adjacence....
La première option a été de de générer des images avec GraphViz à partir des XML exportés par CDA, mais nous ne pouvions produire que des images statiques gigantesques. Il était donc impossible d’avoir un parcours de l'image du graphe sans une machine de compétition et tout aussi impossible d’organiser les nœuds afin d’améliorer le visuel de l’information.
Une autre option a alors été envisagée : stocker ce graphe dans Neo4j. D’une part, Neo4j est une solution optimisée pour le stockage de graphe, nous n’aurions aucun problème avec de gros graphes (9000 nœuds et des centaines de milliers de relations dans notre cas). Neo4j est capable d’en gérer plusieurs millions mais pour beaucoup de systèmes de graphes (GraphViz par exemple) cela commence à faire beaucoup ! De plus, Neo4j possède un langage de requête puissant, Cypher, qui permet d’interroger le graphe pour obtenir toutes sortes d'informations sur les nœuds, leurs liens et le contenu de ces derniers.
Nous avons donc implémenté un parseur XML permettant d’exploiter les fichiers exportés de CDA et de créer le graphe équivalent (nœuds et relations) dans Neo4J. Pour les aspects visualisation et analyse, il ne restait plus qu’à utiliser Gephi.
Voici le résultat sur une application qui compte pas loin d’un million de LOC et plus de 90000 classes après analyse / clustering dans Gephi.

Une belle « pelote de laine », même si Gephi nous aide grandement pour manipuler ce graphe, zoomer, mettre en place des algorithmes de spatialization pour « écarter » les nœuds et avoir un rendu un peu plus correct, mais aussi cliquer sur les nœuds pour récupérer les informations voulues. Ainsi on peut graphiquement chercher un nœud puis le tirer vers l’extérieur pour voir à quoi il est connecté.
En zoomant et après traitement (spacialisation entre autre),

On voit nettement:
- que certains nœuds (classes) sont très connectés et donc très utilisés par toute l’application. Cela permet donc de révéler le nombre de dépendances visiblement trop important pointant de potentiels problèmes de design.
- que certains nœuds ne sont connectés à rien, il y a de fortes chances qu’ils soient peu utilisés, voire qu’il s’agisse de code mort.
Ensuite selon votre application, c’est à vous de déduire à quoi correspondre les amas de nœuds (cela peut correspondre au module de votre application et s’ils sont bien rassemblés c’est plutôt bon signe )
De plus, la modélisation du code dans Neo4j nous a permis de requêter avec le langage dédié Cypher ou simplement d’analyser en Java notre graphe objet et obtenir des informations utiles sur notre application tels que :
- les nœuds qui n'ont aucune relation (orphelins) et donc utilisés nulle part.
public void findOrpheanNodes() {
NodeManager nodeManager = ((EmbeddedGraphDatabase) graphDb).getConfig()
.getGraphDbModule().getNodeManager();
long number = nodeManager.getNumberOfIdsInUse(Node.class);
int nbNodesWithoutRelationShips = 0;
for (int idx = 0; idx < number; idx++) {
Node n = nodeManager.getNodeById(idx);
if (!n.hasRelationship()) {
System.out.println("This one has no relationships");
nbNodesWithoutRelationShips++;
for (String key : n.getPropertyKeys()) {
System.out.println(key + " : " + n.getProperty(key));
}
}
}
}
- les nœuds qui n'ont aucun lien entrant (qui ont donc de fortes chances d'être du code mort)
- Ici on exclut d’office les nœuds dont le nom finit par Command car on sait qu’il s’agit d’un point d’entrée. (Comme quoi de bonnes conventions de nommages sont bien utiles)
public void findNodesWithNoEntranceLinks() {
NodeManager nodeManager = ((EmbeddedGraphDatabase) graphDb).getConfig()
.getGraphDbModule().getNodeManager();
long number = nodeManager.getNumberOfIdsInUse(Node.class);
int counter = 0;
for (int idx = 0; idx < number; idx++) {
Node n = nodeManager.getNodeById(idx);
int nb = 0;
for (Relationship r : n.getRelationships(Direction.INCOMING)) {
nb++;
}
if (nb == 0) {
for (String key : n.getPropertyKeys()) {
if (key.startsWith("className") && ! ((String)n.getProperty(key)).endsWith("Command")) {
counter++;
System.out.println(key + " : " + n.getProperty(key));
}
}
}
}
System.out.println("Number of node without incoming relations : " + counter + " theses node represent dead code (classes not used), you should delete application entrance point of this list");
}
- Les relations d’une classe. Dans cet exemple, Cypher a été utilisé pour le requêtage. Deux choses sont intéressantes dans cette requête : d'une part la requête Cypher permet de récupérer les relations sortantes de la classe en n, ici ClassWithAlotOfRelationShips... qui serait une classe supposée comme ayant trop de liens sortants, cela va permettre de les visualiser. Ce langage est plutôt visuel : on décrit le sens des relations avec des flèches. Dans la suite, on parcourt le résultat avec un itérateur, ce qui ne devrait pas vous changer de vos habitudes en Java.
@Test
public void searchRelationShipsForNode() {
Map params = new HashMap();
params.put("query", "className:com.octo.server.ClassWithALotOfRelationShipsWhichAreDept");
ExecutionResult result = engine.execute( "START n=node:nodes({query}) MATCH (n)-[r]->() RETURN r", params);
Iterator it = result.columnAs("r");
while (it.hasNext()) {
Relationship res = it.next();
System.out.println(res.getType().toString());
}
}
Bien entendu, cela implique de bien connaître les classes qui sont des points d'entrées de l'application (WebServices, Servlet, BackingBeans JSF...) pour les éliminer des résultats de ces requêtes, de même que pour les classes uniquement utilisées et/ou injectées par les frameworks tels que Spring.
Conclusion
Cet article est loin d’aborder tous les sujets autour des graphes, mais Neo4j – même si d’autres implémentations existent - est un outil qui démocratise ce type de stockage. Les notions de communautés, la détection d'influenceurs, la mesure du « customer churn », l'implémentation de recommandations, et bien entendu le graphe social... sont autant d’usages possibles des structures de graphes très en vogue à l'ère du web social.
Reste que la principale limite du stockage de graphe est sa scalabilité. Il est encore aujourd'hui délicat de distribuer un graphe, de parcourir un graphe distribué. Dans l’univers du distribué, la modélisation communément admise est la liste d’adjacence. Cela a des impacts sur la manière de parcourir et de requêter le graphe et des algorithmes se développent (on notera les travaux autour de Bulk Synchronous Processing et Apache Hama pour l'intégration avec Hadoop par exemple). D’autres ont travaillé leur cas d’usage et FlockDB s'en sort en modélisant une liste d'adjacence userid : list(friends) et en partitionnant sur les userid. Un choix fort qui colle bien aux types de requêtes effectués (principalement par userid...)
Dans d'autres cas, les big JVM de type Azul semblent prometteuses et pourraient permettre de repousser en partie ces limitations. Autant de sujets à suivre.