Introduction à la gestion de version distribuée
Depuis quelques temps déjà, une nouvelle génération de gestionnaires de version a fait son apparition. Elle se différencie par son approche distribuée par opposition à l'approche centralisée sur laquelle repose Subversion. Nous allons dans ce billet comment cela se passe dans la pratique et ce que cela change pour le développeur.
Modèle centralisé
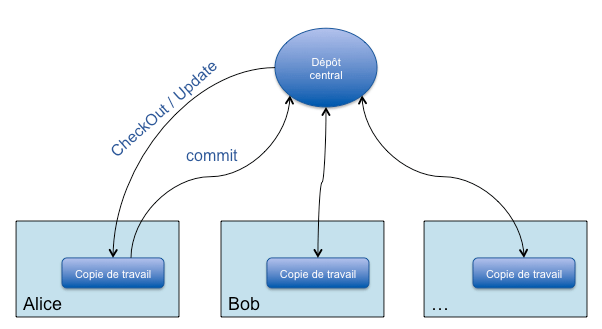
Rappelons tout d'abord le principe de fonctionnement de version (et de tous les systèmes de gestion de version non-distribués) afin de bien saisir les différences entre distribué et centralisé. Subversion est donc composé d'un dépôt unique sur un serveur où se trouve l'ensemble des fichiers, de leurs versions ainsi que des branches qui permettent de gérer plusieurs versions du projet en parallèle. Les développeurs (Alice et Bob par exemple) récupèrent une version du projet sur leur poste de travail (avec la commande checkout) pour pouvoir commencer à travailler dessus. Au quotidien, ils mettent à jour leur copie de travail local (update) depuis le serveur Subversion et renvoient leurs modifications (commit) vers ce même serveur. Ce mode de fonctionnement permet aux développeurs de travailler en parallèle sur le projet, de partager leurs modifications et de versionner les fichiers qu'ils modifient.
Modèle distribué
Lorsque l'on parle de gestion de version distribuée, cela signifie que le dépôt de fichier n'est plus unique sur un serveur mais que chaque développeur possède son propre dépôt. Chacun de ces dépôts contient l'ensemble des versions des fichiers. C'est de ce principe que découle toutes les autres fonctionnalités d'outils comme [Git](javascript:void(0);/1229092993375/), [Mercurial](javascript:void(0);/1229093015273/) ou encore [Bazaar](javascript:void(0);/1229093029171/). Pour illustrer cet article, les exemples s'appuieront sur Git. Même s'ils diffèrent dans le détail, les principes de dépôts multiples et d'échange entre ces dépôts restent globalement les mêmes pour chacun de ces outils.
Origine de Git
Git est un projet initié en 2005 par Linus Torvalds lorsque la licence du précédent gestionnaire de versions utilisé pour le noyau Linux (BitKeeper) ne lui permettait plus de l'utiliser gratuitement. Il est rapidement devenu une référence sur le sujet et on le comprend vite lorsque l'on s'intéresse à l'écosystème qui gravite autour du développement du noyau Linux : une communauté répartie tout autour du globe et un nombre important de branches qui vivent en parallèle. En effet, les branches du noyau sont innombrables :
- les versions contenant des patchs expérimentaux,
- celles servant d'incubateur aux nouvelles fonctionnalités ("zone de quarantaine" avant d'être décrétés suffisamment stables pour être intégrées dans la branche principale),
- les versions de maintenance
- ou encore celles dédiées à un matériel particulier.
Toutes ces branches ne vivent pas sur le dépôt officiel du noyau (parce qu'elles sont maintenues par un autre acteur, ou parce qu'elles n'ont pas encore de légitimité officielle, ...). Certaines ne feront que se synchroniser avec les versions officielles (les "forks"), d'autres seront réintroduites une fois une fonctionnalité terminée (les branches de développement de nouvelles fonctionnalités) et enfin les autres se synchroniseront dans les deux sens avec la branche principale (incubation des nouvelles fonctionnalités). Avec tout ses cas d'utilisations, un modèle centralisé ne peut convenir puisqu'il n'y a qu'un unique dépôt pour un projet et donc tous les développeurs du noyau (et pas seulement les mainteneurs officiels) devraient avoir un accès à ce dépôt. Ce n'est pas toujours souhaitable pour l'une ou l'autre des parties. En effet les mainteneurs officiels ne souhaitent pas que n'importe qui puisse avoir le droit de modifier le noyau officiel et les créateurs d'un "fork" ne souhaite pas forcément rester sur le dépôt d'origine.
Fonctionnement
Commençons par l'initialisation d'un projet géré à l'aide de Git par un développeur seul (Alice). Celle-ci travaille sur sa copie de travail locale, comme avec Subversion, mais avec un dépôt local cette fois-ci :
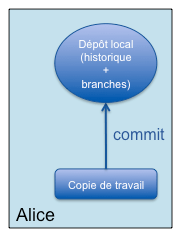
Alice initialise son dépôt personnel sur son poste et enregistre ses modifications sur celui-ci. Pas besoin d'accès à un serveur (mode déconnecté).
git init # initialisation du dépôt
git add ... # ajout de fichiers
git commit -a # commit des modifications/ajouts dans le dépôt
La différence par rapport à Subversion (un référentiel de sources classique) se situe donc lorsque notre développeur ajoute ses modifications au gestionnaire de source (commit avec Git) : celles-ci ne sont répercutés que sur le dépôt local. à ce stade, deux caractéristiques découlent de ce fait :
- il est possible de travailler déconnecté du réseau puisque aucun serveur n'est requis et l'on garde tous les avantages de la gestion de version (parcours de l'historique, retour à une version précédente, ...),
- il est plus facile pour le développeur de versionner ses modifications puisqu'il ne craint plus d'impacter les autres développeurs si la fonctionnalité n'est pas tout à fait stabilisée (versionner et partager deviennent alors deux actions distinctes). En effet, peut importe le nombre de versions qu'il créé, il a la possibilité de les partager seulement lorsqu'il a terminé sa fonctionnalité (il a même la possibilité de créer une seule version sur le dépôt partagé à partir de plusieurs versions locales). Cela évite les effets pervers de versions trop macroscopiques qui contiennent la correction de plusieurs bugs (voir même plusieurs fonctionnalités). Des versions plus régulières permettent de partager la correction d'un bug indépendamment d'autres modifications qui n'auraient rien en commun avec ce bug.
Git permet également de créer des branches (branch) dans le dépôt local et le développeur peut donc se créer des branches privées qu'il ne sera pas obligé de partager :
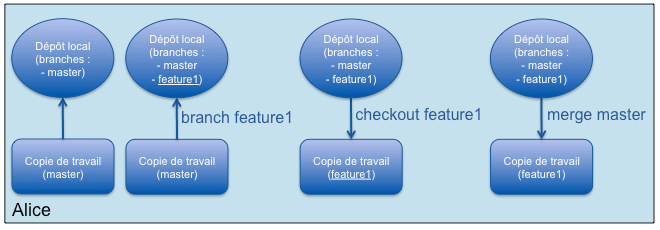
git branch feature1 # création de la branche feature1
git checkout feature1 # passage de la copie de travail sur la branche feature1
… (commits sur feature1)
git checkout master # retour sur la branche master
git merge feature1 # merge des modifications depuis la branche feature1 vers master (branche courante)
Maintenant que le dépôt de l'utilisatrice Alice est initialisé et fonctionnel, Bob va pouvoir cloner (avec clone) le dépôt d'Alice. Il retrouve alors tous les fichiers du dépôt d'Alice, mais aussi toutes leurs versions et les branches partagées du dépôt.
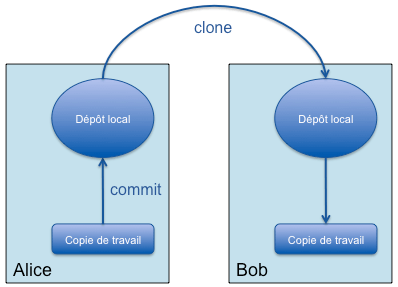
Bob clone la branche master du dépôt d'Alice tout en créant son propre dépôt. Il récupère l'historique complet de la branche. Cela lui permet de travailler en mode déconnecté sur l'historique :
git clone $alice_repository
Le dépôt de Bob n'est alors plus dépendant de celui d'Alice. En effet, Bob a le choix lorsqu'il clone le dépôt d'Alice :
- il peut "forker" le projet d'Alice en restant indépendant et ne plus jamais se synchroniser et faire vivre son projet sans lien avec le projet d'origine,
- il peut se mettre à jour régulièrement depuis le dépôt d'Alice (pull) afin de faire évoluer son projet en parallèle sans remonter la moindre version à Alice,
- ou encore, il peut choisir de renvoyer ses modifications (push) à Alice pour rester synchronisé.
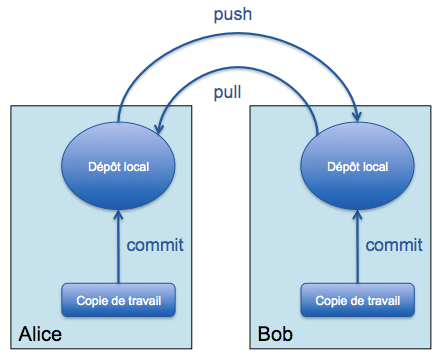
Du point de vu d'Alice :
git pull $bob_repository
git push $bob_repository
Avec 2 développeurs qui travaillent sur le même projet et veulent rester synchronisés, ce mode de fonctionnement est acceptable, par contre lorsqu'il y a plus de développeurs, il devient vite difficile de savoir qui possède la dernière version du projet. Pour cela, il est possible d'imaginer n'importe quelle topologie de dépôts et organiser un minimum le processus de travail collaboratif. Il est par exemple possible de revenir au mode centralisé avec un dépôt qui n'appartient à aucun des développeurs et qui sert de référence comme l'est le dépôt Subversion. On garde cependant les avantages du modèle distribué (mode déconnecté, commit et branches locales, échange pair à pair). Le modèle distribué offre donc une flexibilité que l'on ne retrouve pas avec un gestionnaire de version centralisé.
La possibilité d'échanger des patchs entre les dépôts, qui n'est ni plus ni moins qu'un "merge" entre branches distantes, peut rappeler les douleurs que l'on rencontre avec un gestionnaire de version centralisé (tous ne sont évidemment pas égaux quand il s'agit de manipuler des branches). En effet, encore récemment avec Subversion, il fallait se souvenir et indiquer les révisions à passer d'une branche à l'autre, les conflits de "merge" résolus dans une branche devaient être résolus lorsque ces révisions revenaient dans leur branche d'origine, ... L'approche distribuée a forcé les outils comme Git à travailler sur ces aspects et il faut avouer que l'utilisation des branches devient agréable. On découvre des cas d'utilisation que l'on n'osait pas appliquer avec Subversion.
Il est, par exemple, intéressant de créer une branche par fonctionnalité pour pouvoir travailler sur plusieurs fonctionnalités en parallèle. Un développeur peut alors expérimenter plus facilement en travaillant sur ses branches, il gère les changements de priorité des fonctionnalités en mettant de côté les branches moins prioritaires pour les reprendre plus tard.
Git permet non seulement de le faire simplement mais aussi avec une rapidité déconcertante puisque tout est local, plus besoin de télécharger tout le projet lors d'un changement de branche.
Mais alors pourquoi tout le monde n'utilise pas un gestionnaire de version distribué s'il semble n'y avoir que des avantages ? La raison est simple : ces outils restent encore jeunes. Non pas qu'ils ne soient pas stables (le noyau Linux est un bon test aux limites qui montre qu'ils fonctionnent) mais plutôt que l'écosystème des outils qui les intègre manque encore de maturité. Si Subversion est aussi populaire aujourd'hui, c'est aussi pour son intégration avec quantité d'outils liés au développement (bug tracker, IDE, ...). Il existe par exemple un plugin Git pour Eclipse ou pour Jira mais ils ne sont pas encore complets et/ou utilisables par le commun des mortels.
Une autre limite du modèle distribué est que sa flexibilité apporte aussi une complexité potentielle plus importante qu'avec un modèle centralisé. En effet, comme il est possible d'échanger entre tous les dépôts sans restriction, le premier besoin est d'organiser le processus d'interaction avec le gestionnaire de version. Alors qu'avec le modèle centralisé, la version à jour est celle du dépôt unique, il est nécessaire de mettre en place un dépôt qui joue ce même rôle avec un gestionnaire de version distribué. Enfin, la simplicité de création d'une branche peut conduire les développeurs à ne plus trop savoir qu'elle est la dernière version de leur projet.
Cet article pose les bases des gestionnaires de version distribués afin d'aborder dans un prochain article, la mise en place d'un build d'intégration continue "incassable" grâce à Git.