Introduction à Flume NG
![]()
Flume est une solution de collecte, aggrégation et transfert de gros volumes de logs. Il a été pensé pour gérer des débits importants avec une fonctionnalité native d'écriture dans HDFS au fil de l'eau. Pour gérer ces gros volumes/débits, il se doit d'être très scalable, et donc distribué. L'outil fait partie de l'écosystème Big Data open source Hadoop. Pour vous aider à le situer, ses alternatives sont Scribe et Chukwa pour les plus connus, et également Kafka même si ce dernier répond à d'autres problématiques de par sa nature (messagerie publish/subscribe).
Flume a récemment subit un lifting profond. Il aura fallu 1 an pour refondre son architecture depuis Août 2011 et réécrire certains de ses composants coeurs. Aujourd'hui, 6 mois après la première release stable, Flume NG (version 1.x) est fiable, performant, définitivement prêt pour la production. Bref il est temps de s'y pencher sérieusement. Je vous propose donc de brosser un tableau de la solution à travers ce billet, en regardant de près ses forces, mais aussi ses faiblesses...
Pourquoi NG ?
Flume a été développé au départ chez Cloudera (éditeur Hadoop) en open source sous license Apache. La première release stable de ce qu'on appelle aujourd'hui la version Flume OG (Old Generation, version 0.9.x) date de début 2010.
Flume OG a subit un refactoring profond pour plusieurs raisons, les principales sont les suivantes :
- architecture complexe avec un master et un zookeeper pour centraliser la configuration
- code endetté avec beaucoup de fonctionnalités peu utilisées
- des limitations techniques notamment concernant la persistence des messages
Flume NG (Next Generation) remplace donc Flume OG pour apporter une réponse à ces limitations, avec notamment une simplification de l'architecture, maintenant composée d'agents "pairs" distribués : plus besoin de master et de cluster Zookeeper.
Flume NG est devenu Top Level Apache project depuis Juillet 2012.
Une architecture composée d'agents distribués
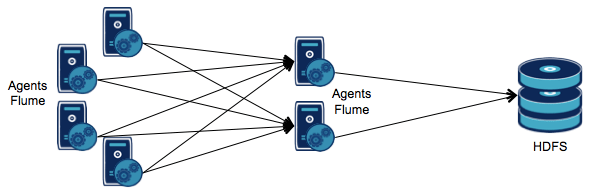
La figure ci-dessus représente une architecture typique d'agents Flume :
- des agents collés aux sources d'événements
- des agents qui vont se charger de consolider les logs afin de les écrire dans un référentiel centralisé, typiquement un cluster HDFS ou une base HBase
L'anatomie d'un agent : route = source+channel+sink
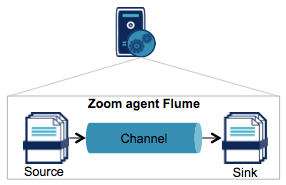
Chaque agent exécute des "routes". Comme illustré dans la figure ci-dessus, une route est constituée de :
- sources, pour consommer les messages envoyés par une source externe (une application, un script, un syslog, ...). Il existe différents types de sources, les principales sont :
- ExecSource : exécuter une commande (uniquement commande bash simple au moment où j'écris cet article) dont l'output sera traité dans Flume en tant que ligne de log. L'exemple le plus classique est l'execution de la commande tail pour récupérer les lignes d'un fichier de log au fil de l'eau.
- AvroSource : mettre l'agent Flume en écoute sur un port TCP et recevoir des logs au format Avro
- SyslogSource : router les logs d'un serveur syslog vers Flume
- SpoolingDirectorySource : récupérer le contenu des fichiers de log (immutables) qui arrivent dans un répertoire
- channels, pour stocker les logs au niveau de l'agent
- FileChannel : persister les logs sur le file system pour garantir la non-perte de message en cas de panne et/ou redémarrage de l'agent
- MemoryChannel : garder les logs en mémoire pour favoriser la performance
- JDBCChannel : utiliser une base de données comme solution de stockage
- sinks, pour consommer les logs d'un channel par lot et les écrire sur une destination. Il existe plusieurs types de sinks, par exemple :
- HDFSSink : écrire dans HDFS ou S3
- HBaseSink et ElasticSearchSink : écrire dans votre base NoSQL. Il existe aussi des sinks open source pour Cassandra, MongoDB, etc.
- AvroSink : rediriger les logs au format Avro sur un port TCP distant. Le couple AvroSource/AvroSink est utilisé pour transférer les logs d'un agent vers un autre.
- FileRollSink : écrire dans le filesystem local
- NullSink et LoggerSink : à utiliser pour tester la configuration et valider que les logs arrivent bien à destination
Pour aller plus loin...
Point intéressant, il est possible d'implémenter des sources, channels et sinks customs pour étendre les fonctionnalités disponibles par défaut. Il suffit d'implémenter les interfaces Java dédiées, et de déclarer ces classes dans le fichier de configuration Flume.
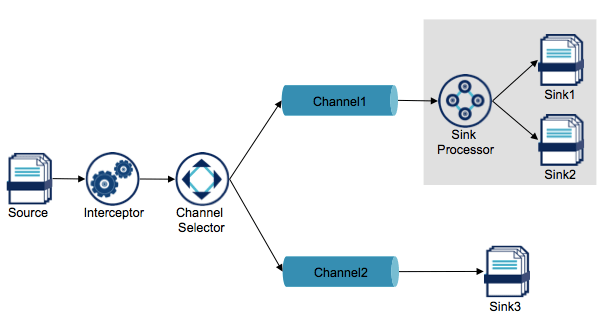
Comme le montre la figure précédente, il existe d'autres composants permettant de rendre le flux de données plus intelligent avec d'autres types de composants :
- interceptors : pour intercépter les logs avant de les stocker dans les channels afin de filtrer, transformer, ou enrichir les événements avec des en-têtes (ex: timestamp, id source, ...)
- channel selectors : pour router le flux (grâce aux en-têtes) sur des channels différents
- sinks processors : pour distribuer le flux sur plusieurs destinations (load balancing) ou adapter la destination du flux en fonction d'une panne (failover)
Installation, configuration et exploitation simplissimes!
L'installation est relativement simple : installer un JDK, définir la variable d'environnement JAVA_HOME, télécharger et dézipper Flume et c'est parti! Bon OK, il faudra aussi ajouter le script de démarrage du service dans /etc/init.d, créer les répertoires /var/run/flume et /var/log/flume avec les bons droits... mais rien d'exotique dans tout ça. Vous trouverez une recette Puppet sur mon GitHub si ça vous intéresse. Enfin n'oubliez pas d'installer les libs Hadoop sur la machine si l'agent doit écrire dans HDFS.
Pour démarrer l'agent, il faut exécuter la commande "flume-ng" avec quelques paramètres, par exemple :
flume-ng agent -n agent1 -f /usr/local/lib/flume-ng/conf/flume.conf -c /usr/local/lib/flume-ng/conf
La configuration est également triviale, il suffit d'éditer un fichier properties avec des paramètres explicites. En voici un exemple :
agent1.channels = memoryChannel
agent1.channels.memoryChannel.type = memory
agent1.channels.memoryChannel.capacity = 100000
agent1.channels.memoryChannel.transactionCapacity = 1000
agent1.sources = tailSource
agent1.sources.tailSource.channels = memoryChannel
agent1.sources.tailSource.type = exec
agent1.sources.tailSource.command = /usr/local/flume-tools/bin/xtail-custom -d /app/logs
agent1.sources.tailSource.batchSize = 100
agent1.sources.tailSource.interceptors = timestampInterceptor
agent1.sources.tailSource.interceptors.timestampInterceptor.type = timestamp
agent1.sinks = hdfsSink
agent1.sinks.hdfsSink.channel = memoryChannel
agent1.sinks.hdfsSink.type = hdfs
agent1.sinks.hdfsSink.hdfs.rollInterval = 360
agent1.sinks.hdfsSink.hdfs.rollCount = 0
agent1.sinks.hdfsSink.hdfs.rollSize = 0
agent1.sinks.hdfsSink.hdfs.batchSize = 1000
agent1.sinks.hdfsSink.hdfs.txnEventMax = 1000
agent1.sinks.hdfsSink.hdfs.codeC = snappyCodec
agent1.sinks.hdfsSink.hdfs.fileType = SequenceFile
agent1.sinks.hdfsSink.hdfs.path = hdfs://namenode:8020/user/hdfs/data/importFlume/dt=%Y%m%d/
Le fichier de configuration ci-dessus permet de configurer une route avec :
- tailSource : la source est un tail sur un répertoire
- timestampInterceptor : les événements sont interceptés pour ajouter une en-tête avec le timestamp
- memoryChannel : les événements sont gardés en mémoire au niveau de l'agent Flume
- hdfsSink : les logs sont écrits sur HDFS en sortie, partitionnés dans différents répertoires (grâce au header timestamp)
Côté exploitation, Flume dispose comme Hadoop d'une fonctionnalité d'export des métriques dans Ganglia grâce à l'ajout de deux paramètres de lancement :
flume-ng agent ... -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=com.example:1234
On peut également exposer les métriques en JSON de la même manière :
flume-ng agent ... -Dflume.monitoring.type=http -Dflume.monitoring.port=34545
Les logs sont propres et les messages d'erreur plutôt clairs et explicites.
A noter également que les éditeurs travaillent d'arrache pied pour offrir des outils clés en main (ex: Cloudera Manager, HortonWorks Data PLatform, ...) pour industrialiser tous ces processus : installer et configurer Flume en quelques clics, superviser les agents (même si ça reste moins poussé que dans Ganglia), etc.
Forces et faiblesses de la solution
Forces :
- Flume NG est intégré à la plupart des distributions Hadoop open source ou commerciales : Cloudera, HortonWorks, MapR ou encore Greenplum
- C'est une solution très simple à installer, configurer et exploiter
- L'architecture applicative et les interfaces Java fournies permettent d'étendre les capacités fonctionnelles de Flume pour l'intégrer avec n'importe quelle solution, que ce soit en source de données ou en destination. Par exemple, dans le cadre d'un projet, j'ai pu implémenter un sink pour Esper sans aucune difficulté.
- La possibilité de greffer des intercepteurs permet d'utiliser Flume comme un ETL en flux. Je l'ai par exemple mis en oeuvre pour anonymiser les données, reformater des données, ajouter des champs, ... avant de les stocker dans HDFS
- Le caractère distribué de la solution permet d'atteindre un bon niveau de performance et scalabilité. A titre d'exemple, j'ai mis en oeuvre Flume sur un projet avec comme objectif d'intégrer 5 milliards de logs par jour dans HDFS, soit environ 70 000 événements par seconde.
Faiblesses :
- Pas de compression des données transférées au moment où j'écris ce billet. Cela peut être très problématique lorsque la bande passante est limitée. Mais cette fonctionnalité ne devrait pas tarder à rentrer dans la distribution, un patch est disponible.
- Flume est lent en écriture sur disque. Le facteur de dégradation des performances entre l'écriture mémoire et l'écriture disque est de l'ordre de 10. Flume est bien moins performant que Kafka (lecture/écriture séquentielle, OS pagecache, etc.) en accès sur disque.
- La mémoire devient vite un goulet d'étranglement dans le cas où vous privilégiez le stockage mémoire plutôt que disque pour des raisons de performance. Or, si vous privilégiez la mémoire, c'est justement parce que vous prévoyez un débit important... Dans ce cas, l'utilisation d'agents intermédiaire (tampon pour absorber un burst à la source ou amortir une panne en sortie) devient vite inutile sauf si vous utilisez une JVM type Zing de Azul ou si vous implémentez un channel pour stocker sur BigMemory de Terracotta par exemple...
- Le produit n'est pas conçu pour être "élastique". En effet, la configuration est très statique et il n'est pas possible de détecter l'ajout d'un nouveau noeud dans la topologie.
- La configuration est trop simpliste et verbeuse. Il n'est pas possible de configurer un template et instancier les routes avec des paramètres spécifiques (port, IP, etc.). Pour un débit optimal, il est préférable de configurer autant de routes que de coeurs CPU disponibles sur la machine, on se retrouve donc rapidement avec plusieurs centaines de lignes de configuration, toutes pratiquement identiques... Bref, un script de génération des fichiers de configuration devient vite indispensable.
- Toutes les fonctionnalités de Flume OG n'ont pas été reportées dans Flume NG. Par exemple le concept de decorator n'existe plus dans Flume NG, ça permettait par exemple de compresser les données transférées entre agents. Il n'y a plus non plus de source de type tail ou tailDir (tail sur un répertoire), il faut maintenant utiliser par une ExecSource, le tail de répertoire doit être scripté.