Hadoop : une plateforme de référence pour faire du Big Data
Utilisé par les géants du web comme Yahoo!, Twitter, LinkedIn, eBay et Amazon, Hadoop est un framework libre et open source. Aujourd'hui, il est une plateforme de référence qui permets analyser, stocker et manipuler de grandes quantités de données (dites Big Data).
Fonctionnement d'Hadoop
Basé sur le principe des grilles de calcul, Hadoop fractionne les fichiers en gros blocs et les distribue à travers les nœuds du cluster. Il comprend plusieurs composants : les principaux étant les nœuds maîtres (Master nodes) et les travailleurs (Worker nodes). Les nœuds travailleurs sont parfois appelés nœuds esclaves (Slave nodes).
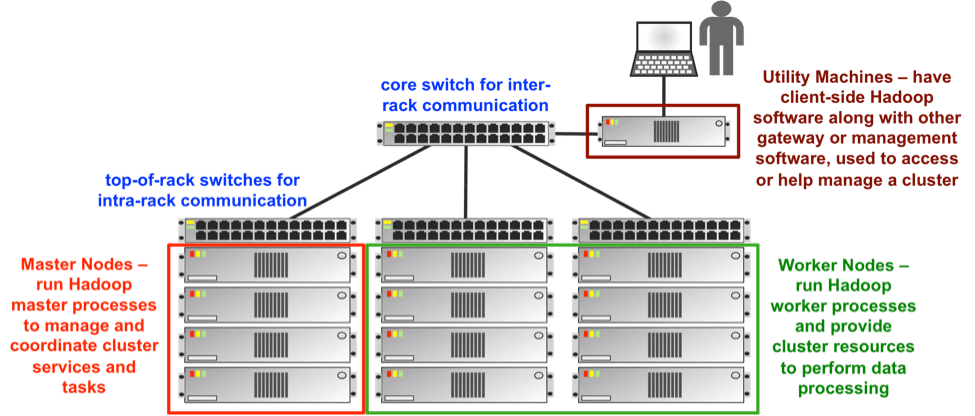
Composition d'Hadoop
Le framework Hadoop se compose des modules suivants:
| Module | Définition |
| Hadoop Distributed File System (HDFS) | Le système de gestion de fichiers distribués permet de stocker les données sur les machines du cluster |
| Hadoop Common | Contient les bibliothèques et les utilitaires nécessaires aux autres modules Hadoop |
| Hadoop YARN (Yet Another Resource Negotiator) | Une plate-forme chargée de la gestion des ressources informatiques du clusters et de les utiliser pour la planification des applications des utilisateurs |
| Hadoop MapReduce | Une implémentation du modèle de programmation MapReduce pour le traitement des données à grande échelle |
D'autre part, le mot Hadoop se réfère également à son écosystème et à l'ensemble des logiciels comme Apache Pig, Apache Hive, Apache HBase, Apache Phoenix, Apache Spark, Apache ZooKeeper, Cloudera Impala, Apache Flume, Apache Sqoop, Apache oozie et Apache Storm.
Solutions Hadoop
Dans la pratique, Hadoop est un standard pour le traitement Big Data et son universalité attire de nombreux acteurs. Cependant, pour l'utiliser il faut bien choisir le produit pour traiter les données. Plusieurs options existent :
- Utiliser version open source d'Apache
- Utiliser l’une des différentes distributions qui contiennent Apache Hadoop
- Utiliser le package Big Data d'un éditeur qui contient ou utilise une distribution
| Solution - - Fonctionnalités | Apache Hadoop | Distribution Hadoop | Package Big Data |
| - MapReduce<br>- HDFS<br>- Ecosystème | V | V | V |
| - Packaging<br>- Outils pour le déploiement<br>- Support commercial | - | V | V |
| - Outillage et modélisation<br>- Génération de code<br>- Interface graphique de planification des jobs big data<br>- Intégration de différentes sources | - | - | V |
Les fournisseurs de distributions Hadoop
En plus d'Apache Hadoop, il existe quatre distributions Hadoop :
- Hortonworks : la Plateforme de données Hortonworks (_HDP:_Hortonworks Data P__latform) comprend le système Hadoop Distributed File System (HDFS), MapReduce, Pig, Hive, HBase et ZooKeeper.
- Cloudera : contient les principaux éléments, de base du framework Hadoop (MapReduce et HDFS), ainsi que d'autres composants destinés aux entreprises qui assurent la sécurité, la haute disponibilité, et l'intégration avec le matériel et les autres logiciels.
- Pivotal : en partenariat avec Hortonworks depuis 2015. Ensemble, ils concentrent leurs efforts autour d'un noyau cohérent de fonctionnalités basées sur Apache Hadoop comprenant des intégrations de produits, l'ingénierie conjointe et soutien à la production.
- MapR : utilise un système de fichier Unix natif au lieu de HDFS. Il propose des fonctionnalités de haute disponibilité (snapshots, la réplication et le basculement avec état).
Beaucoup d’autres éditeurs de logiciels ne développent pas leur propre distribution Hadoop, mais travaillent ensemble avec l’un des éditeurs existants. Par exemple, Microsoft est partenaire de Hortonworks, en particulier pour déployer Apache Hadoop sur son système d’exploitation Windows Server et sur leur service de cloud Windows Azure.
Formations Hadoop
Savoir traiter et faire parler ses données est un véritable avantage compétitif qui ouvre la voie à de nouveaux business models.
Dans tous les métiers du digital, il est primordial d'acquérir de nouvelles compétences et d’effectuer une veille active. L'utilisation des nouvelles solutions amène à la nécessité d'apprendre les outils Big Data. Pour vous aider dans cette démarche, OCTO Technology propose plusieurs formations Hadoop via son organisme OCTO Academy.
> Apprendre les fondamentaux d’Hadoop
Cette formation est une initiation aux fondamentaux d’Hadoop. Elle donne aux participants une connaissance théorique et pratique de la plateforme, à travers plusieurs exercices pratiques appliqués à des cas réels. A l’issue de la session, les participants seront en capacité d’utiliser les outils de l’écosystème Hadoop pour explorer des données stockées sur un entrepôt Big Data.
-
> Administrer la plateforme Hadoop 2.X Hortonworks 1 (HDP Operations: Hadoop Administration 1)
Cette formation Hadoop est conçu pour les administrateurs qui sont en charge de gestion de la Plateforme de données Hortonworks (HDP: Hortonworks Data P__latform) avec Ambari. Il couvre l'installation, la configuration, et d'autres tâches de maintenance du cluster.
> Administrer la plateforme Hadoop 2.X Hortonworks : niveau avancé (HDP Administrator: Hadoop Administration 2)
Cette formation est destinée aux administrateurs de plateforme HDP qui souhaiteraient approfondir leurs connaissances. Le focus est mis sur la haute disponibilité des divers outils, la gouvernance de la donnée, les réglages avancés de la plateforme ainsi que l’automatisation de déploiement de celle-ci.
> Administrer la plateforme Hadoop 2.X Hortonworks : sécurité (HDP Operations: Security)
Cette formation Big Data est destinée aux administrateurs de la plateforme HDP qui souhaiteraient approfondir leurs connaissances en matière de sécurité. Le focus est mis sur les outils permettant de sécuriser la plateforme en termes d’authentification, d’autorisation et d’audit.
> Administrer la base de données HBase avec Hadoop 2.X Hortonworks (HDP Operations: Apache HBase Advanced Management)
Cette formation HBase est conçu pour les administrateurs qui feront l'installation, la configuration et la gestion des clusters Hbase. Il couvre l'installation avec Ambari, configuration, sécurité et de dépannage des implémentations Hbase. Le cours comprend un projet dans lequel les élèves travaillent ensemble pour concevoir et mettre en œuvre un schéma HBase.
> Analyse de données pour Hadoop 2.X Hortonworks avec HBase (HDP Analyst: Apache HBase Essentials)
Cette formation Hadoop est conçu pour les analystes Big Data qui veulent utiliser la base de données HBase NoSQL exécutée sur HDFS pour fournir en temps réel l'accès en lecture / écriture à des ensembles de données éparses (real-time read/write access to sparse datasets). Les sujets traités comprennent l'architecture HBase, les services, l'installation et la conception de schémas.
> Analyse de données pour Hadoop 2.X Hortonworks avec Pig, Hive et Spark (HDP Developer: Apache Pig and Hive)
Cette formation est conçu pour les développeurs qui ont besoin de créer des applications pour analyser les données stockées dans Hadoop en utilisant Pig and Hive. Les sujets traités comprennent : Hadoop , YARN , HDFS , MapReduce , data ingestion, workflow, utilisation Pig et Hive pour effectuer des analyses de données sur les Big Data et une introduction à Spark Core et Spark SQL.

> Développer des applications pour Apache Spark avec Python ou Scala (HDP Developer: Enterprise Spark 1)
Cette formation Spark est conçu pour les développeurs qui ont besoin de créer applications pour analyser les données stockées dans Apache Hadoop en utilisant Spark. Les sujets traités comprennent : aperçu dela Plateforme de données Hortonworks (HDP: Hortonworks Data P__latform), YARN, HDFS, l'utilisation du Spark Core APIs pour l'exploration interactive des données, la construction et le déploiement des applications Spark, l'optimisation des applications, Spark SQL et DataFrame operations, l'utilisation de Spark Streaming et une introduction à Spark Machine Learning Library.
> Apache Spark pour développeurs de Cloudera (Cloudera Developer Training for Apache Spark)
Cette formation développeurs Cloudera pose les bases du développement avec Apache Spark, tout en présentant l’écosystème Hadoop dans lequel il s’intègre. Le principal objectif est la prise en main de cet outil incontournable du paysage du Big Data ainsi que l’acquisition de notions essentielles relatives à son architecture. Des éléments de Spark Streaming et Spark SQL sont aussi abordés.
> Développer des applications pour Hadoop 2.X Hortonworks avec Java (HDP Developer: Java)
Cette formation Hadoop Java fournit aux programmeurs Java une description en profondeur du développement d'applications Hadoop. Les étudiants apprendront comment concevoir et développer les applications MapReduce pour Hadoop en utilisant la Plateforme de données Hortonworks (HDP: Hortonworks Data P__latform). Cette formation intègre la mise en œuvre des combiners, partitioners, secondary sorts, les formats d'entrée et de sortie personnalisés, la jointure de grands volumes de données (joining large datasets), les tests unitaires et le développement de UDFs (User-Defined Function) pour Pig and Hive.
> Développer des applications pour YARN avec Hadoop 2.X Hortonworks (HDP Developer: Custom YARN Applications)
Cette formation Hadoop est conçu pour les développeurs qui veulent créer les applications YARN personnalisé pour Apache Hadoop. Il comprend : l'architecture YARN, les étapes de développement YARN , l'écriture des clients YARN et Application Master et lancement des conteneurs. Le cours utilise Eclipse et Gradle connectés à distance à un cluster 7 - noeud HDP sur une machine virtuelle .
> Développer des applications pour Hadoop 2.X Hortonworks sous Windows (HDP Developer: Windows)
Cette formation Hadoop est conçu pour les développeurs et les analyste Big Data dans Apache Hadoop sur Windows en utilisant Pig et Hive. Les sujets traités sont : Hadoop, YARN, Hadoop Distributed File System ( HDFS ), MapReduce, Sqoop et HiveODBC Driver.
+ Nos formations DATA SCIENCE >