Git dans la pratique (2/2)
Dans une première partie, nous avons abordé la notion d'index et la différence entre une branche locale et une branche distante. Une fois les notions d'index et de branches locales et distantes bien comprises, il est possible d'aborder des fonctionnalités plus avancées de Git.
Oui, Git est efficace et flexible
Mettre de côté des modifications
Régulièrement, on se retrouve avec des modifications en cours sur notre copie de travail quand vient une tâche plus prioritaire. Plutôt que d'abandonner les modifications déjà effectuées, de commiter des modifications qui cassent une fonctionnalité, ou encore de créer un patch dans un fichier que l'on met de côté, Git nous propose d'utiliser git stash. Cette commande permet de mettre de côté toutes les modifications de la copie de travail et de l'index (il faut penser à ajouter les nouveaux fichiers qui ne sont pas encore suivis par Git). Après avoir exécuté cette commande, l'index et la copie de travail seront dans le même état qu'après un git reset --hard HEAD (ie. plus aucune modification en cours et/ou à commiter) et un groupe de modifications est créé et visible avec git stash list.
Pour reprendre le travail commencé et rangé il est possible de le récupérer de 2 façons différentes :
soit nous avons la possibilité de créer une branche sur laquelle nous pourrons créer autant de commits que nécessaire, de basculer entre cette tâche que l'on peut faire avancer au rythme souhaité si elle n'est plus prioritaire. Dans ce cas, la création de la branche s'effectue à partir des modifications mises de côté avec :
$ git stash branch myfeatureÀ la suite de cette commande, nous nous retrouvons sur la nouvelle branche
myfeatureavec les modifications telles qu'elles étaient avant legit stash(ie. dans la copie de travail ou "stagées" sur l'index mais non commitées),soit nous pouvons réappliquer les modifications sur la branche actuelle avec :
$ git stash pop
Cherry-picking
Il est classique d'utiliser des branches pour gérer les différentes versions des différents environnements où est déployée l'application. Dans notre cas, nous utilisons la branche master pour le développement au quotidien, une branche recette et une branche de production associées à leur environnement respectif. Régulièrement, lors de la découverte d'un bug, une correction de ce bug était déjà présente sur la branche master et nécessitait d'être appliquée soit sur la branche recette ou production. Seulement, il n'est pas envisageable de réaliser un merge de master vers l'une de ces 2 branches car nous ne voulons pas intégrer toutes les autres modifications de la branche master.
Git possède la commande cherry-pick qui permet de sélectionner un commit quelconque et de l'appliquer sur la branche actuelle.
$ git checkout production
$ git cherry-pick d42c389f
Merge vs Rebase
Un dernier point qui surprend lorsqu'on débute avec Git est l'historique qui apparait très peu lisible. En effet, avec 10 développeurs travaillant sur la branche master et synchronisant sur un dépôt centralisé, l'historique finit par ressembler à ça : 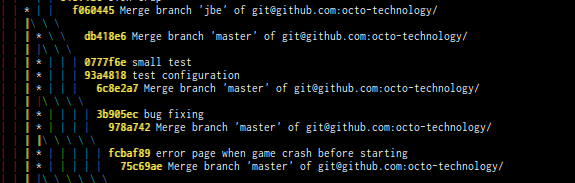
Lorsqu'on utilise git pull, la stratégie par défaut est de merger la branche distante dans la branche locale. Git considère donc qu'il s'agit de 2 branches différentes alors qu'en réalité, nous voulons considérer qu'il s'agit d'une seule et même branche comme nous le faisions avec Subversion. L'historique reflète donc autant de branches qu'il y a de développeurs et Git cré des commits de merge lors d'un git pull qui intègre des commits distants et locaux.
Git permet cependant de travailler avec une logique plus proche de celle de Subversion. Au lieu d'effectuer un merge, il est possible de réaliser un "rebase" lors d'un git pull. Le principe du rebase est de revenir en arrière dans l'historique en mettant de côté les commits qui n'ont pas encore été pushés, d'appliquer les commits de la branche distante sur la branche locale, puis d'appliquer les commits mis de côté à la suite. L'historique est alors linéaire et ne laisse plus de traces de branche ou de commits de merge.
Exemple
Si l'on prend l'exemple suivant qui contient des commits sur la branche master et d'autres provenant de la branche master du dépôt origin :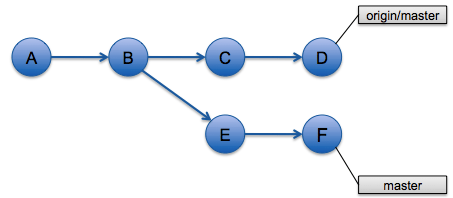
Cas d'un merge
En utilisant git pull (ou git merge origin/master), un commit de merge est créé (G) et l'historique ressemble alors à ça : 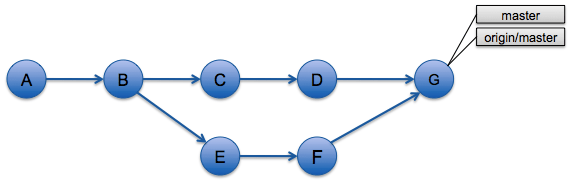
Cas d'un rebase
En utilisant git pull --rebase (ou git rebase origin/master), les commits qui n'existaient que sur la branche master (E et F) sont supprimés et réappliqués à la suite des commits de la branche origin/master. Ce sont de nouveaux commits (E' et F'), c'est pour cela qu'il ne faut pas faire un rebase sur des commits qui sont déjà présents sur un dépôt partagé. 
Résolution de conflit
Que ce soit lors d'un merge ou d'un rebase, il arrive que des conflits apparaissent. Voici comment les résoudre avec Git.
Lors d'un merge
Lorsqu'on effectue un git merge (ou git pull) et qu'un conflit apparait, Git ne commit pas automatiquement. Les fichiers sans conflit seront alors déjà ajoutés à l'index, alors que les fichiers en conflits apparaîtront comme tel lors d'un git status :
$ git status
# On branch master
# Changes to be committed:
#
# modified: test3
#
# Unmerged paths:
# (use "git add/rm < file >..." as appropriate to mark resolution)
#
# both modified: test
#
Pour résoudre le conflit, 2 possibilités :
git mergetoolexécutera un outil de merge sur tous les fichiers en conflit,- les fichiers en conflit contiennent les 2 versions des lignes en conflit comme c'est le cas avec Subversion. Il est donc possible de résoudre manuellement le conflit en éditant ces fichiers. Une fois les conflits résolus, il est nécessaire d'appliquer un
git stagesur ces fichiers.
Enfin, un git commit terminera l'opération de merge.
Pour revenir à l'état du dépôt avant la tentative de merge (au lieu du git commit) :
$ git reset --hard HEAD
Lors d'un rebase
Une opération de rebase (git rebase ou git pull --rebase) n'échappe pas aux conflits. La résolution des conflits peut cependant être nécessaire plusieurs fois lors d'un seul rebase. En effet, les commits étant appliqués 1 par 1, un conflit peut apparaître à chaque fois qu'un commit est rejoué. La procédure est la même que pour le merge (ie. git mergetool ou édition manuelle des fichiers en conflit suivit d'un git stage) sauf que le dernier git commit sera remplacé par un git rebase --continue pour que Git continue d'appliquer les commits suivants.
$ git pull --rebase
...
## conflit
$ git status
# Unmerged paths:
# (use "git add/rm < file >..." as appropriate to mark resolution)
#
# both modified: test
#
$ git mergetool
...
$ git rebase --continue
Pour revenir à l'état du dépôt avant la tentative de rebase (au lieu du git rebase --continue) :
$ git rebase --abort
Cas d'un conflit de binaires
Que ce soit lors d'un merge ou d'un rebase, la résolution d'un conflit de binaires ne se résout pas avec un git mergetool. En effet, pour ce genre de conflit, la résolution se fait en choisissant l'une des 2 versions possibles :
$ git checkout --ours -- binary_file_pathpour sélectionner la version que nous avions avant le merge, ou la version provenant de la branche rebasée lors d'un rebase. En effet, la branche mergée est appliquée sur la branche en cours alors que c'est sur la branche rebasée que l'on applique les commits de la branche en cours. Le
--oursest donc inversé selon l'opération.$ git checkout --theirs -- binary_file_pathpour sélectionner la version de la branche mergée, ou la version que nous avions avant le rebase.
Une fois la version du binaire à conserver sélectionnée, la procédure reste la même :
$ git stage binary_file_path
$ git commit # lors d'un merge
ou
$ git rebase --continue # lors d'un rebase
Modifier un commit
Il arrive que l'on crée des commits en ayant oublié quelques détails (d'ajouter un fichier, de faire passer les tests, ...). Habituellement, il aurait fallu se résigner à créer un nouveau commit qui corrige nos erreurs. Avec Git, il est possible de modifier un commit existant.
Avant d'aller plus loin, attention toutefois, il est très fortement déconseiller de modifier un commit déjà partagé sur un dépôt accessible par d'autres développeurs (ie. après un git push généralement).
La façon la plus simple de modifier le dernier commit que l'on a effectué est d'utiliser git commit --amend au lieu de git commit -m '...'. L'option --amend va ajouter les modifications de l'index au commit précédent et aucun nouveau commit ne sera alors créé.
L'autre façon, plus avancée, de modifier des commits dans l'historique de Git est git rebase --interactive <commit>. Celle-ci permet de ne plus être restreint au dernier commit. Par exemple pour éditer l'historique parmi les 5 derniers commits, il faut exécuter :
$ git rebase --interactive HEAD~6
HEAD~6 désigne le sixième commit ancêtre de la HEAD. Il est nécessaire d'englober un commit de plus que le nombre de commits que l'on veut éditer. Votre éditeur de texte favori sera exécuté par Git (en utilisant la variable d'environnement EDITOR) avec un fichier semblable à celui-là :
pick 4997150 commit n-5
pick 7be917b commit n-4
pick 83270c0 commit n-3
pick c65ad3b commit n-2
pick fa9252b commit n-1
pick 2bf85f8 last commit
Il est alors possible d'effectuer plusieurs actions sur chacune des lignes :
- supprimer la ligne pour supprimer purement et simplement le commit de l'historique,
- changer l'ordre des lignes pour changer l'ordre d'application des commits,
- remplacer "pick" par "edit" pour pouvoir modifier le commit (cf. la résolution de conflit lors du rebase plus haut),
- remplacer "pick" par "squash" pour merger le commit avec le précédent pour n'en créer qu'un seul,
- remplacer "pick" par "reword" pour juste changer le message de commit".
Après avoir enregistré et quitté l'éditeur de texte, Git tentera de rejouer les commits avec les modifications définies.
Il se peut qu'en rejouant ces commits, des conflits apparaissent. Dans ce cas là, Git s'arrêtera au commit qui a échoué ou au commit marqué "edit". Une fois les conflits résolus et/ou le commit edité comme souhaité et les modifications ajoutées à l'index (ie. git stage), il reste à exécuter git rebase --continue pour poursuivre la réécriture de l'historique.
Conclusion
Comme nous avons pu le voir, git permet de pousser très loin la gestion des versions de ses sources. Jusqu'à présent, je ne me suis jamais retrouvé à ne pas pouvoir faire les manipulations que je pouvais imaginer, seulement souvent, il a fallu lire les pages de manuels et diverses documentations que l'on peut trouver sur internet (qui sont d'ailleurs très complètes) afin d'aller plus loin dans la compréhension de l'outil. Un conseil bien pratique lorsqu'on tente de nouvelles actions sur son dépôt Git est d'en faire une copie en cas de fausse manipulation. Donc, comme souvent, un outil qui offre une grande flexibilité requiert une bonne connaissance de son fonctionnement.