Faire son catalogue d'API
Cet article est un cheval de Troie où le catalogue d'API permet de parler d'un peu d'architecture, de code, d'organisation humaine, de processus projet, de gouvernance de services … Pour les pressés, le code est là.
Pourquoi ?
Quand on démarre un projet, c'est parfois tout un travail de fouille, d'enquête, pour savoir si le service dont on a besoin existe. Les interlocuteurs peuvent alors ne pas être simples à trouver ou ne sont pas facilement accessibles. Et d'autres fois, quelqu'un se sera donné la peine de capitaliser ses recherches dans un wiki. Mais voilà, ce n'est pas à jour et finalement il faut quand même enquêter. Je vous propose dans cet article de fabriquer nous même l’outil pour répondre à un cas simple : La création d’une application catalogue branchée à une UDD. Il suffirait que l’UDD puisse envoyer les fichiers de spécification d'API ainsi que quelques informations basiques au catalogue par un service. Elle restera en interne d’un SI entre équipes, donc pas de besoins de sécurité particuliers. Pour des besoins simples en interne comme celui-ci, une solution d'API Management sera peut être de trop. En effet cet outil vient souvent avec son écosystème complet de modules et de fonctionnalités, et vous aurez certainement à vous plier à ses contraintes. Je vous propose alors de développer cette solution vous-même, voire de partir du code qui va suivre. En fonction de votre expérience avec l'outil, vous pourrez décider s'il vous en faut un peu ou beaucoup plus.
Ma vision du produit
Le catalogue d'API est une application qui affichera la liste des spécifications disponibles, et permettra leur export dans leur format d'origine. Il pourra être alimenté par tous à travers une API REST ou une interface web.
Alimenté par tous
Par opposition à "alimenté par une équipe dédiée" : si vous intégrez l'alimentation de ce catalogue dans votre processus projet, permettre le self-service durant la réalisation d'un projet fluidifiera le delivery. C'est-à-dire que c'est un intervenant de moins avec lequel se coordonner. Et d'autre part laisser cette autonomie aux équipes catalysera l'innovation dans votre entreprise. L'idéal est de laisser la main à tous, et par contre de logguer pour tracer qui fait quoi. Si nécessaire, il est toujours possible de protéger l'API du catalogue en écriture avec OAuth et une interface d'upload avec une page de login, pourquoi pas alimenté avec votre LDAP si c'est le référentiel actuel de votre entreprise.
Le catalogue ouvert en lecture à tous
Si vos équipes ont un accès restreint à ce savoir, il est probable que vous subissiez des services en double, voire du shadow IT. C'est l'accès à vos APIs elles-mêmes qu'il faut contrôler (restriction ou simple log), pas le catalogue qui recense le patrimoine de votre entreprise. S'il faut vraiment protéger l'accès en lecture au catalogue, ici aussi OAuth pour les services et une page de login pour l’IHM feront l'affaire. Au passage, n'oubliez pas le SSO pour que les utilisateurs n'aient pas cet énième compte à gérer. De manière générale, quand la sécurité autour d'un service rend son accès difficile, ce service risque d'être moins utilisé ou pire, les utilisateurs chercheront des solutions de contournement. Une fois en place ces contournements sont très difficiles à détecter et contrôler, et posent donc de plus gros problèmes de sécurité.
Opérations sur le catalogue disponibles par l'API et par IHM
Par IHM c'est courant, mais pourquoi par l'API ? Souvent votre documentation est générée à partir de votre code (annotations Swagger le plus souvent). En déploiement continu, le catalogue devrait être automatiquement mis à jour avec la mise en production de votre API.

Une exception peut être l'utilisation d'une approche top-down. Elle consiste à décrire l'interface dans un fichier de spécification, puis de développer l'API en fonction de cette documentation. Par exemple avec API Blueprint vous pouvez utiliser Dredd pour "exécuter" des tests, à partir de votre spécification, sur votre serveur. Une fois que les tests passent, l'API correspond à la spécification définie. On peut utiliser ce type d'approche dans un contexte où des décideurs ont cette responsabilité, et établissent un contrat avec des exécutants (des prestataires par exemple). Quand l'API passe les tests de la spécification, l'interface correspond à ce qu'on définit les décideurs. Un autre avantage de cette approche, est que vos clients ont accès au contrat d'interface de l'API en amont pour anticiper les évolutions. "Oui mais il nous faut quand même la validation du responsable/référent" : ce n'est pas incompatible avec l'automatisation. Introduisez une étape nécessitant, après publication automatique, un clic sur "Accepter"/"Refuser" (avec un texte décrivant une raison d'ailleurs) de la part dudit responsable avec une notification. Mais sachez que cette étape de validation entre votre équipe et ce responsable dans votre processus est coûteuse en énergie, temps et donc argent. En laissant la possibilité aux développeurs de publier eux-mêmes, et en positionnant le référent en approche conseil plutôt qu'autorité, vous accélèrerez le processus de déploiement et ferez gagner du temps au référent. L'équipe avancera en toute autonomie et le référent ne sera plus mobilisé que pour les cas nouveaux ou exceptionnels : capitalisez sur ce que vous savez déjà faire ! Si l'accès par l'API vous gêne tout de même, et qu'il faut limiter l'accès seulement à l'IHM, une contrainte Access-Control-Allow-Origin devrait suffire.
Et pourquoi t'as pas implémenté la page de login et tout le reste ?
Comme vous avez dû le remarquer avec les ajustements proposés plus haut, tout dépendra de votre contexte. Le code de cette application étant testé, il devrait être un minimum maintenable pour que vous puissiez y ajouter des fonctionnalités indispensables à l'intégration dans votre propre SI sans risquer des régressions.
L'intégration dans le SI
Où ça se trouve
Pour la publication automatique, il est au moins connecté à l'UDD, du moins au script de déploiement, pour automatiser la publication des contrats d'interface. Il est aussi possible de le connecter à d'autres outils pour relever des métriques sur son activité (e.g. les logs d'accès aux endpoints sur le serveur web). Il doit également être possible d'accéder à son interface pour les équipes qui l'utiliseront.
Et la réversibilité, si on s'engage sur cet outil ?
Lorsque vous choisissez un outil, il faut aussi prévoir une porte de sortie : des interfaces minimalistes standards sur lesquelles vous pourriez brancher des outils d'une origine différente, des méthodes de stockage standards que vous pourriez exploiter avec des outils d'une origine différente, et peu de fonctionnalités qui vous rendraient dépendants. Alors pourquoi m'engager avec cet outil ne sera pas "irréversible" :
- L'interface humaine de l'outil est minimaliste. On devrait retrouver ces "actions" dans n'importe quel catalogue, pas de quoi perdre les utilisateurs ou les rendre dépendant d'une fonctionnalité particulière.
- L'interface machine, c'est à dire l'API REST, est également minimaliste et standard (je pousse une spec, je la récupère), ce qui réduit aussi l'adhérence à l'outil (plus il y a de fonctionnalités, plus des systèmes différents ou spécialisés en dépendront).
- La base de spécifications est simple à extraire : peu de types d'objets.
Et pas plus de possibilités donc moins d'adhérence, un outil #KISS qui #LibereTonSI. Cet outil n'existe pas ? Créez-le, et partagez-le.
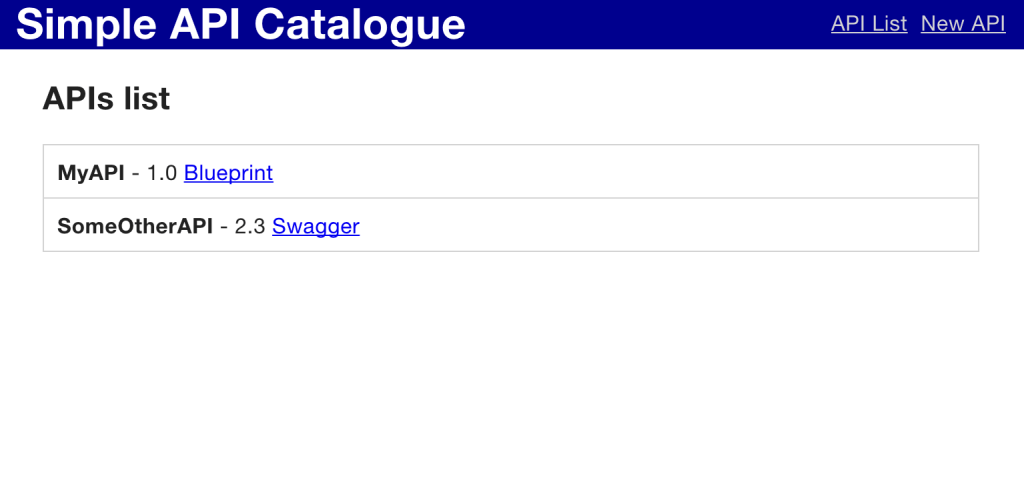
Comment c'est fait ?
Les technologies
Pour faciliter la reprise du code, il est écrit en Java 1.8 (il serait temps de migrer non ?). Pareil, Maven est encore assez connu, alors partons là dessus. Vous pourriez certainement être habitués à Spring, ou Jersey, alors partons sur Spring REST pour l'API. On utilisera aussi JDBC pour permettre l'utilisation de n'importe quelle base SQL qui pourrait déjà être validée dans votre organisation.
Méthode
Pour débuter le projet, on va entamer les problèmes. La méthode Tracer Bullet consiste à débuter une application avec un minimum de fonctionnalités qui permettent de toucher toutes les couches de bout en bout. C'est à dire ici un bout d'API REST pour l'interface avec le catalogue, un bout de base de données et le système de fichier pour stocker la spécification, et un bout sur l'interface web pour voir ce qu'on a stocké. En commençant par les problèmes d'intégration, j'aurai un code minimaliste qui tirera le plus gros de mon architecture logicielle, et donc moins de difficultés pour refactorer les parties les plus structurantes de mon code. Je pourrai aussi savoir au plus tôt si le choix des technologies que je dois intégrer était pertinent, et donc revenir sur mes décisions au moment où c'est encore facile et peu coûteux. Et parce que chez OCTO c'est la pratique, mais aussi parce qu'une application de mauvaise qualité ne devrait pas atteindre la production, on va dégainer TDD. C'est simple, avant de se lancer dans le code de l'application, on écrit un test qui décrit ce que fera notre code. On le lance une première fois pour constater qu'il échoue (si si, mal fait ça peut échouer). Puis on écrit le code jusqu'à ce que le test passe. Une fois qu'on répond au test, on se lance dans le refactoring pour s'assurer que le code est maintenable (en répondant toujours au test bien sûr). Au final, chaque bout de code qui fait quelque chose est précédé d'un test, ce qui résulte en une couverture naturellement importante. Et honnêtement, c'est à chaque fois un tel confort de chambouler son code quand un harnais de tests nous protège des régressions : on a aucune crainte à l'améliorer !
La base de données
Pas de boulot spécifique pour la base H2 qui servira aux tests. Pour le reste c'est du PostgreSQL. Dans le repo GitHub vous trouverez 2 scripts : un pour créer la base avec docker et un pour se connecter dessus avec plsql (basés sur le tutoriel https://hub.docker.com/_/postgres/). Une fois la base lancée, créez la base de l'application CREATE DATABASE cataloguedb. Un exemple de configuration de l'application sur ma base locale PostgreSQL se trouve avec les sources dans application.properties. Vous devrez certainement changer l'utilisateur, le mot de passe, l'adresse de la base et son port. Pour connaitre le port de votre base sur docker : docker inspect <containerId> et trouvez HostPort dans le champ NetworkSettings.
Créer le projet
Pour ne pas avoir à faire le pom.xml moi-même : https://start.spring.io
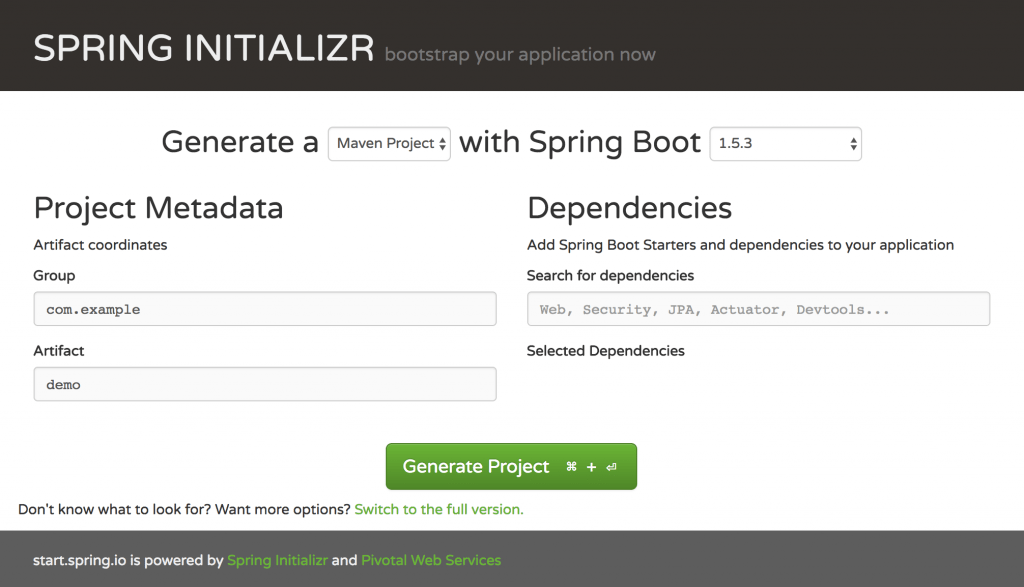
Sur cette interface vous pouvez spécifier les dépendances qui vous intéressent. Dans le cas présent, j'ai demandé :
- PostgreSQL : Pour la base de production de mon application
- H2 : Une base mémoire légère pour lancer les tests d'intégration sans avoir besoin d'une base PostgreSQL
- JDBC : Pour abstraire l'intégration de n'importe quelle base sur mon application
- JPA : Pour abstraire les tables de ma base dans des objets Java.
- Rest Repositories : Pour traduire directement les objets Java en API
- Thymeleaf : Un moteur de template les pages du catalogue
Après avoir choisi vos dépendances sur ce site, cliquez sur "Generate Project", qui vous donnera un zip avec votre projet initialisé. Lancez votre application avec mvn spring-boot:run, et hop, un serveur qui fonctionne.
Choix de design
Normes API
Dans l'URL, chaque collection est le nom de la ressource au pluriel. Chaque ressource est accessible par un identifiant après le nom de la ressource. Les méthodes HTTP:
- POST sert à créer/modifier une ressource.
- GET pour obtenir la ressource
- DELETE supprime la ressource
Sur l'objet API, le nom et la version sont uniques. Quand un POST est effectué avec un nom et une version que la base connait, le catalogue se contente de remplacer les autres champs par le nouvel objet qui lui est fourni. Si vous cherchez comment designer votre API, je vous conseille l'article "Designer une API REST" et sa refcard.

Accès aux fichiers de spécification
L'accès se fait par la ressource de spécification correspondante, puis par l'ajout de "specificationFile" à la fin de l'URL. GET /specifications/1/specificationFile me parait un peu plus naturel que de passer par un endpoint différent.
POST qui remplace une API existante
Il aurait été possible de faire un endpoint pour la ressource qui décrit l'API, et un pour uploader le fichier de spécification. Mais plutôt que de laisser le consommateur gérer ce processus, j'ai préféré l'inclure dans l'interface. Ce type de choix peut être fait pour assurer la qualité de la donnée, mais aussi éviter que tout le monde réimplémente la même chose. La contrepartie c'est que l'interface nécessite de faire du multipart, et peut être moins simple à gérer selon les clients qui l'utiliseront. Mais dans notre cas, CURL (utilisable avec Jenkins) permet cela facilement, et pour une interface d'upload, ce n'est pas bien plus compliqué. Il n'y a pas de solution miracle universelle : L'architecture, c'est une histoire de compromis.
Difficultés
Reimplémentation des méthodes CRUD de Spring REST
Du fait l'implémentation peu commune de la méthode de création de spécifications, Spring REST n'a pas créé automatiquement les méthodes CRUD. Ce n'est pas très grave dans la mesure où, pour certaines méthodes, des spécificités nécessiteraient qu'on fasse ce travail. C'est le cas de la suppression d'une specification, pour laquelle le fichier correspondant doit aussi être supprimé sur système de fichier. J'aurais cependant préféré que Spring génère automatiquement le code le plus direct et que je n'ai plus qu'à surcharger les méthodes que je voulais.
Structure JSON et Multipart
En regardant le code, vous remarquerez que je dois désérialiser les objets JSON et déclencher leur validation moi-même et donc gérer les aussi les cas d'erreur avec leur message. Pourquoi ne pas avoir utilisé un objet dans la signature de la méthode avec l'annotation @Validate ? Il est vrai qu’avec Spring je ne devrais même pas avoir à m’occuper de sérialiser ou désérialiser, il le fait automatiquement. Saut que cette fonctionnalité disparait bizarrement quand dans l'endpoint l'un des paramètres transforme cette requête en requête multipart. Après pas mal de recherche et d'essais, il semble que lorsque vous implémentez un endpoint multipart avec Spring, vous ne pouvez pas désérialiser automatiquement un objet. La conséquence directe est qu'il faut également se charger soi-même des étapes de validation et donc de gestion d'erreur…
Les erreurs, Spring et sa doc
À de nombreuses reprises Spring a tenté de me faire comprendre des choses sans me dire explicitement ce qu'il voulait ou pouvait faire. J'ai un peu lutté pour comprendre que je n'aurai pas toutes les méthodes CRUD gérées automagiquement par Spring à partir du moment où j'implémente l'une des méthodes. Je me suis cassé les dents sur le problème de désérialisation d'objet et de Multipart parce qu'il n'était pas clair que "Spring ne peut gérer les deux à la fois sur un même endpoint". Encore une fois, faites des tests. Votre santé mentale en dépend.
Ce qu'il faut retenir
- L'accès en lecture au patrimoine de l'entreprise devrait être libre : pas de restriction sur l'accès au catalogue.
- L'accès en écriture ne devrait pas être encombré, mais devrait être loggué : utilisez au moins les logs du serveur web, vous aurez l'IP appelante et l'url appelée.
- La facilité avec laquelle on se sépare d'un outil devrait être un critère lors du choix de cet outil : base PostgreSQL avec 2 tables, API REST avec CRUD sur une ressource, agnostique de la spécification (RAML, Blueprint, Swagger ou votre format à vous), technologies Java/Spring/Maven communes.
- L'architecture est une histoire de compromis, il n'y a pas une solution parfaite pour tout : plutôt que de laisser les applications en amont, ou un émissaire devant le catalogue, gérer la cohérence entre l'upload d'un fichier de spécification et l'objet API, l'interface du catalogue prend les deux en charge, mais cet endpoint est de fait moins standard.
- Automatisez ce qui peut l'être : si votre UDD génère la documentation de votre API, pourquoi elle ne la fournirait pas au catalogue au passage ?
- Commencez le projet par les risques : j'ai commencé par l'upload, puis j'ai affiché la liste des services.
- Faites des tests
- Spring n'est pas explicite hors des cas nominaux
Les sources sont par ici : https://github.com/Aigrefin/api_catalogue. Et vous trouverez la spécification de l'API du catalogue, avec les sources, ici : https://github.com/Aigrefin/api_catalogue/blob/master/catalogue-api.apib.