Exemple d'infrastructure MongoBD : haute disponibilité en lecture
Imaginons le cas suivant : nous avons une base MongoDB, alimentée exclusivement par des batchs ordonnancés et via un client back office. Les utilisateurs, très nombreux, y accèdent via une application client-serveur. La consistance ne doit être qu'in fine (eventually consistent en anglais). Nous avons donc, en gros, 1 accès en écriture pour 10 accès en lecture. Quelle architecture pourrions-nous mettre en place pour assurer la haute disponibilité de notre base de données et donc nous prévenir de risques comme la perte d'un disque dur ? Comment pourrions-nous nous prémunir facilement contre une corruption et donc adresser la problématique de back up ? Je vais essayer de vous proposer une réponse unique à ces deux questions, en utilisant les fonctionnalités natives de MongoDB alliées aux possibilités offerte par l'utilisation des services proposés par Amazon Web Services…
Préambule
MongoDB en détail
MongoDB est une base données "NoSQL" de type documentaire. Chaque document est stocké sous un format proche du JSON (le "BSON"), dans une collection. Chaque collection est situé dans une base. Un serveur MongoDB expose une ou plusieurs bases.
La particularité fonctionnelle de MongoDB est de pouvoir créer des index, simples ou composites, sur certains attributs de nos documents, et ce, même s'il n'existe pas de schéma. De plus, elle propose un système de requête à base de javascript très simple à la prise en main.
Si vous souhaitez creuser l'utilisation de MongoDB, je vous conseille de jeter un oeil à cet article.
Exemple de cas d'utilisation
Un cas d'utilisation de ce genre d'infrastructure pourrait être la mise en place d'un moteur de recherche sur des données de sources multiples et variées. Notre infrastructure sert à agréger le contenu, à l'exposer à un moteur de recherche puis à l'affichage des résultats de requêtes utilisateurs.
Architecture
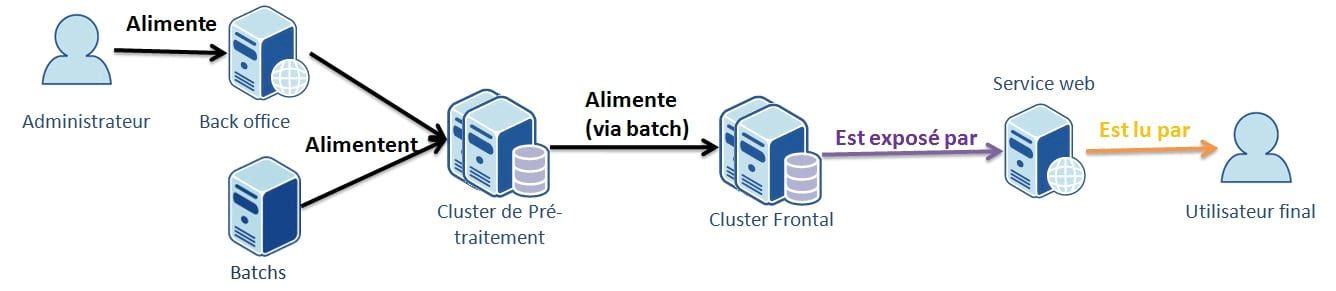
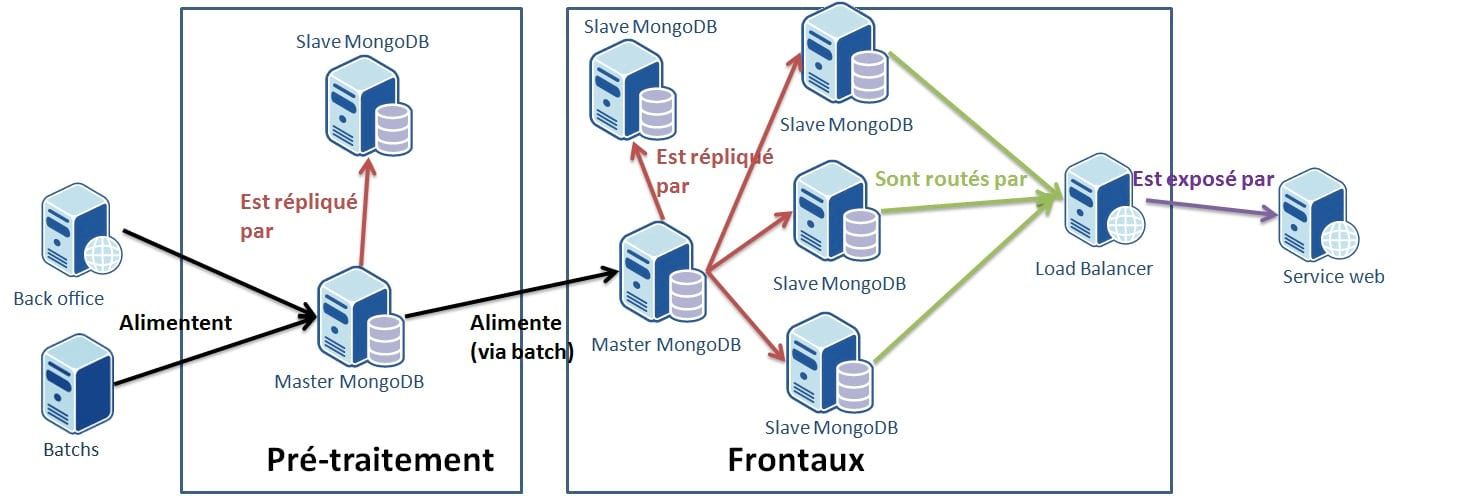
La chaîne complète fait intervenir deux environnements: un environnement de pré-traitement, sur lequel se feront les écritures et un environnement "frontal" sur lequel se feront les lectures. Les deux fonctionnent en isolation (d'où la nécessité de deux bases maîtres), le lien étant assuré à l'aide d'un batch de synchronisation. Ce découpage nous permet de concentrer toutes les opérations d'écritures, plus ou moins complexes et donc plus ou moins gourmandes en mémoire et en CPU sur un seul serveur sans impacter la charge en lecture, alors qu'elles se font 24 heures sur 24. Et vice-versa, la charge en lecture (24/24, plusieurs hit/s) n'impactera pas les calculs nécessaires aux opérations d'écriture. L'intégralité des écritures se font sur la base maître du "pré-traitement" alors que l'intégralité des lectures se font sur les esclaves du "frontal". Enfin, un problème lors de l'intégration des batchs (maître KO, corruption) n'entrainera pas d'impact sur l'accès en lecture, assurant toujours un niveau de haute disponibilité.
Pré traitement
Dans cet environnement, différents batchs ordonnancés alimentent une base MongoDB, à l'aide de données en provenance de services distants et de fichiers. La base MongoDB est répliquée afin de faire face à d'éventuels crashs et de permettre la mise en place d' un système de sauvegarde sans impacter les opérations d'écritures (voir plus bas). En effet, en cas de corruption de notre base, cette corruption sera répliquée sur l'esclave. Il est donc nécessaire d'avoir une sauvegarde quotidienne afin d'éviter d'avoir à rejouer l'intégralité des batchs. De même, on peut se servir de cette sauvegarde pour alimenter le serveur maître de l'environnement frontal.
Frontaux
Cet environnement est découpé en plusieurs couches. La première consiste en un serveur maître et un premier esclave. Le maître sert exclusivement à la synchronisation avec le pré traitement, afin d'éviter que la synchronisation n'impacte la lecture. L'esclave permet de mettre en place un mécanisme de fail over si le maître venait à crasher. On ferait basculer la synchronisation des autres esclaves vers celui-ci (après l'avoir transformé en maître), ainsi que la synchronisation pré-traitement/frontal.
Les autres esclaves servent à l'exposition des données. Le load balancer aura pour tâche de rediriger les accès sur l'un ou l'autre de ces esclaves.
Et pourquoi pas un Replica Set ?
MongoDB propose un autre mécanisme de réplication, nommé Replica Set. Celui-ci permet de mettre en place un mécanisme de fail over automatique et de load balancing (sur l'écriture) et donc réduit le temps de bascule et d'indisponibilité et améliore les performances. Les serveurs élisent entre eux le Maître. Si celui-ci tombe, une nouvelle élection à lieu pour qu'il soit remplacé. Nous aurions donc pu remplacer l'architecture maître/esclave de notre environnement frontal par celle-ci.
Toutefois, la possibilité de se connecter à un tel montage n'est pas supporté par tous les drivers de langage disponibles (d'après une étude que nous avons fait sur le projet auquel je participe, PHP et Ruby ne le supporte pas à 100%) et c'est relativement complexe à mettre en place. Dans notre cas, cela ne semble pas forcément approprié, n'ayant pas besoin de fail over automatique. En effet si notre maître frontal tombe, les esclaves sont toujours accessibles en lecture et il n'est nécessaire qu'il ne redevienne accessible qu'au moment de la synchronisation entre pré traitement et frontal.
Mise en place
Réplication
Comment mettre en place nos deux groupes de master/slave, en pré-traitement et en frontal ? MongoDB propose un mécanisme natif et asynchrone pour cela.
Master
Pour démarrer un serveur maître, rien de plus simple ! Dans le répertoire bin de votre version de MongoDB, lancer la commande suivante : mongod --master [--dbpath "emplacement de vos fichiers BSON"]
Grâce à l'argument --master, notre instance de Mongo générera un journal de transaction, qui pourra être consommé par les différentes bases esclaves. Ceux-ci, chaque seconde, vérifient s'il y a eu une nouvelle écriture, et, le cas échéant, la reproduisent. Attention toutefois, ce journal a une taille limitée. Par défaut, il est de 5% de l'espace disque libre, avec un minimum de 1Go pour une machine de 64 bits, mais seulement 50 Mo pour une machine 32 bits. Toutefois, si nous voulons gérer nous même la taille du journal (par exemple 500 Mo), nous pouvons lancer notre serveur maître avec la commande suivante : mongod --master --oplogSize 500 [--dbpath "emplacement de vos fichiers BSON"]
Cela peut être nécessaire dans le cas de réplications trop lentes par rapport aux nombres de commandes exécutées sur le maître. Dans notre cas, étant sur un serveur 64 bit, la valeur par défaut nous semble suffisante.
Slave
Démarrer un serveur esclave est presque tout aussi simple qu'un serveur maître. Cela se fait via cette commande : mongod --slave --source "master_host"[:"master_port"] [--dbpath "emplacement fichiers BSON de l'esclave"]
Si nous ne renseignons pas le port du maître, l'esclave essayera de s'y connecter sur le port 27017 par défaut. Attention, si nous tenons de lancer un esclave sur le même serveur que le maître, il ne faut pas oublier d'utiliser l'option --port "nouveau-port" dans la commande de lancement de notre esclave.
Il est possible de créer autant d'esclave que l'on souhaite pour un seul maître. Toutefois, d'après la documentation officielle, au delà d'une dizaine, les performances de réplication ne risquent plus d'être au rendez-vous. De plus, il n'est pas possible de faire de la réplication d'esclave à esclave, du fait de l'absence de journal de transaction.
Chaque esclave va récupérer en temps réel chaque écriture du journal de transaction du maître. Néanmoins, dans le cas où la consistance entre le maître et le ou les esclave n'est pas prioritaire, il est possible de créer un délai entre chaque scrutation du journal grâce à l'option --slavedelay. Par défaut, celui-ci est d'une seconde. Par exemple, pour un délai d'une minute, la commande serait : mongod --slave --source "master_host"[:"master_port"] --slavedelay 60 [--dbpath "emplacement fichiers BSON de l'esclave"]
A l'opposé, il peut arriver qu'un esclave ne soit plus synchronisé avec son maître (KO durant un certain temps par exemple) et synchronisable (le journal de transaction a déjà flushé certaines opérations depuis le KO de l'esclave). Pour éviter ce genre de problème, il est nécessaire de lancer l'esclave avec l'option --autoresync. L'esclave copiera alors l'intégralité du contenu du maître s'il est désynchronisé. Attention toutefois à votre volume de donnée. Cette opération peut être dans ce cas relativement couteuse pour la maître et l'esclave. Il est donc important de bien définir la taille du journal de transaction pour éviter un maximum un état de désynchronisation de l'esclave.
Enfin, pour revenir à notre architecture initiale, il faut rendre nos esclaves accessibles en lecture. En effet, ceux-ci n'acceptent aucune requête par défaut. Pour ce faire, il est nécessaire d'utiliser une dernière option, seulement activable via le shell mongo. Lancer donc tout d'abord le shell sur votre serveur esclave. mongo --host "mon_esclave" Puis, entrez les commandes suivantes : use admin db.getMongo().setSlaveOk()
Synchronisation base de pré-traitement / base front office
Comment synchronisez notre environnement de pré-traitement avec celui de front office ? L'utilisation d'un batch faisant un simple dump du pré-traitement pour ensuite l'intégrer au maître "frontal" semble être la solution la plus simple avec MongoDB. Voici en détail comment cela se met en place.
Dump
MongoDB permet de gérer très simplement les actions de sauvegarde et de restauration, en local ou à distance. Dans le cas de notre serveur de pré-traitement, il suffit de se mettre dans le répertoire /bin de votre installation de MongoDB et de rentrer la commande suivante pour faire une sauvegarde : mongodump --host "mon_serveur_de_staging"
Ce dump aura la forme d'un répertoire "dump" contenant autant de répertoire que de base (dont un pour la base contenant les informations d'administration), contenant chacun un fichier BSON par collection, plus un fichier BSON d'index. L'arborescence pourrait avoir cet aspect là :
dump --base1 ----collection1.bson ----collection2.bson ----system.indexes.bson --base2 ----collection3.bson ----system.indexes.bson --admin
Dans notre cas d'étude, notre serveur n'étant alimenté que par des batchs, il est aisé de savoir si des actions d'écriture sont en cours ou non. Dans le cas contraire, il est nécessaire de "flusher" toute les actions d'écriture en cours et d'empêcher qu'il y en ait d'autres. Toutefois, si on ne veut pas faire tomber nos batchs en erreur, il faut, dans ce genre de cas penser à répliquer le serveur de pré traitement et faire le dump sur le répliqua. Quoi qu'il en soit, pour réaliser ces actions, il faut lancer le shell : mongo --host "répliqua_de_mon_serveur_de_pretrairement" Puis lancer les commandes suivantes : use admin db.runCommand({"fsync" : 1, "lock" : 1})
Vous l'aurez compris, "fsync" force le flush, et "lock" verrouille notre base. Les "1" ne servent qu'à indiquer le lancement des commandes. Ensuite, il ne reste plus qu'à lancer le dump sur le répliqua.
Pour déverrouiller la base, toujours dans le shell, il faut lancer les commandes suivantes : use admin db.$cmd.sys.unlock.findOne()
Restore
Une fois le dump produit, il ne nous reste plus qu'à faire l'action de restauration sur le serveur maître de notre ferme de serveurs frontaux. Il est toutefois nécessaire d'assurer l'intégrité de notre base à l'issue de cette commande. Pour ce faire, il faut associer 2 options au lancement de votre commande. La première, --drop, supprimera tout le contenu de notre serveur d'arrivée. Cela évite d'avoir de la duplication de donnée, des conflits d'ids. La seconde, --indexesLast, forcera la création des indexes seulement une fois le contenu de vos différentes bases et collections inséré. Cela permet de se prémunir d'une mauvaise indexation. Au final, voici la commande qu'il faut lancer, dans le répertoire bin de votre installation de MongoDB : mongorestore --dbpath "mon_master_frontal" --drop --indexesLast "chemin_vers_mon_repertoire_dump"
Limitations
Ce mode de synchronisation offre toutefois de grosses limitations dans la cadre de bases très volumineuses (plusieurs centaines de milliers de documents) et répliquées. On a pu observer des chutes de performances importantes, voire une impossibilité de solliciter nos bases pendant près d'une heure, le temps que la restauration puis la synchronisation soit terminée. Il est donc nécessaire de limiter la fréquence de ces actions, si c'est le mode de fonctionnement qui est utilisé
Finalement, dans notre cas, nous avons décidé d'utiliser une synchronisation par delta, où nous ne poussons vers le serveur frontal que les données qui ont été mises à jour sur le pré-traitement. MongoDB ne permettant pas nativement un tel mode fonctionnement (ne serait qu'un dump par delta), nous avons dû le faire de façon programmatique. Pour cela, nous avons créé un batch, qui extrait du serveur de pré traitement les données modifiées depuis son dernier lancement, identifiées grâce à un timestamp, pour ensuite transmettre les modifications vers le maître des serveurs frontaux. Grâce à ce mode de fonctionnement, nous pouvons maintenir une fréquence élevée de synchronisation (plusieurs fois par jours), sans chute de performance.
Sauvegarde
Afin de se prémunir de toute corruption des données, notamment en pré traitement, il est nécessaire mettre en place des mécaniques de rejeux de nos batchs et de sauvegarde de nos bases. Nous avons décidé de traiter ces deux problématiques à l'aide d'un bucket S3 loué à Amazon. Cela nous permet de nous assurer que le taux de perte de fichiers soit proche du 0%. Voici les différentes mécaniques associées.
Rejeux
Afin de pouvoir rejouer nos batchs de pré-traitement, toutes nos données disponibles sous forme de fichier sont disposées sur le bucket S3. Chaque batch y scrute un répertoire qui lui est alloué pour récupérer les données qu'il doit insérer. Je vous propose de pousser la donnée manuellement à l'aide d'un plug in firefox, S3Fox Organizer. Nos batchs, quant à eu, récupéreront ses fichiers via l'outil en ligne de commande S3cmd.
Pour récupérer un fichier par exemple, lançons la commande : s3cmd get s3://"mon_bucket"/"mon_batch"/"mon_fichier"
Back up
Pour ne pas avoir à réintégrer l'intégralité des données fournis par les différents batchs, le mieux reste de sauvegarder régulièrement la base de pré-traitement. Pour ce faire, faisons régulièrement un "dump" sur le répliqua, puis sauvegardons le sur le bucket.
Pour ce faire, il n'y qu'à utiliser S3cmd et la ligne de commande suivante : s3cmd put staging_dump.tar.gz s3://"mon_bucket"/"mon_répertoire_de_sauvegarde"
Conclusion
J'espère avoir pu vous montrer qu'il est très facile de réaliser ce cas d'étude avec MongoDB, un peu de programmation et une petite aide d'Amazon. Bien sûr, cette architecture n'est valable qu'à 3 conditions:
- Notre modèle de donnée est adapté à un stockage documentaire. Dans le cas contraire, il vaut mieux étudier une autre solution NoSQL ou une base de données relationnelles classique
- La sollicitation en écriture ne nécessite pas une haute disponibilité. Dans le cas contraire, il faudrait étudier une solution à base de replica set, permettant un fail over automatique (avec les limitations que cela implique sur les technologies permettant de s'y connecter).
- Le volume de données d'une collection nous permet d'avoir des temps de traitement correct lors de l'agrégation. Si ce volume venait à augmenter drastiquement et que les temps d'agrégation en entrée devenaient trop long, il faudrait envisager une architecture à base de sharding, ce que propose nativement MongoDB.