Devoxx France 2015 - Compte Rendu
Pour sa quatrième édition, Devoxx France prenait place cette année au Palais des Congrès qui a attiré près de 2500 personnes sur 3 jours du 08 au 10 avril 2015. Une vraie réussite et une organisation rondement menée !
En guise de rappel, Devoxx est une groupe de conférence initié en Belgique qui regroupe un grand nombre de développeurs du monde Java mais pas seulement. La variété des formats de conférences (keynote, university, quickie, tools-in-action, hands-on-lab) contribue à la richesse de l'événement. Cette année on a parlé BigData, DevOps, IoT et Mobile mais aussi traditionnellement Java Modulaire et la clôture des Cast Codeurs.
Cet article a pour but de faire un tour d'horizon des conférences que nous avons pu suivre, de vous donner un premier retour et de vous fournir les pointeurs pour approfondir si vous le souhaitez.
DevOps
Quand Devops rencontre BigData (Olivier Bazoud, Vincent Heuschling)
- CFP Devoxx
- Présentation : Full
- Ressources : HOL
Cette première session était un Hands’on, animé par Olivier Bazoud et Vincent Heuschling, je n’ai donc pas pu prendre beaucoup de notes. Les 4 exercices sont disponibles sur le GitHub et sont bien découpés. En 3 heures je n’ai pas l’impression d’être allé très loin avec Spark mais j’ai au moins pu toucher du doigt son utilisation.
Objectifs du Hands On Lab (HOL) :
- Manipuler des données avec le REPL
- Analyser des Apache Logs
- Détecter des anomalies dans des logs réseau
- Utiliser un cluster
Dans une architecture BigData, la difficulté repose souvent sur l'analyse de logs. Deux outils principaux du BigData :
- Hadoop (HDFS, MapReduce, OpenSource, Google en 2006)
- Spark (Fonctionnel, In Memory, Midsize Data, Berkeley AMPLab)
Spark part du postulat que la plupart des Datasets ne dépassent pas le Giga, il va pouvoir tenir dans la RAM de plusieurs machines. Quelques avantages :
- Rapide (RAM)
- Fonctionnel (moins de code)
- En pleine croissance (Spark SQL, Spark Streaming, MLlib, GraphX) en 3 ans
- Spark Shell : permet de tester des commandes en live
Les données sont stockées dans un RDD (Resilient Distributed Dataset) qui rejoint le principe habituel d’éclatement de la donnée en partitions qui vont être exécutées sur plusieurs noeuds (1 partition = 1 processus).
Hadoop se base sur le MapReduce (splitter les fichiers sur HDFS pour les traiter parallèlement).
Une brève phrase de conclusion sur le Big Data en général que j’ai finalement bien aimée :
"La difficulté du machine learning réside plus dans le choix des données, de la pondération choisie pour chaque colonne plus que de l'algorithme d'apprentissage en lui même."
Mesos University (Aurélien Maury, Pablo Lopez, Jean-Baptiste Claramonte, Jean-Pascal Thiery)
- CFP Devoxx
- Ressources : Github
![]()
L'objectif de Mesos est d'augmenter la densité applicative dans le cluster, exploitant ainsi chaque machine qui compose le cluster de manière plus efficace, par opposition au fait d'instancier des noeuds dont les ressources ne sont pas pleinement exploitées (ex. : un serveur web qui consomme beaucoup de mémoire mais peu de ressources CPU). Son défi est de fournir ce dont les applications distribuées ont besoin (signal start/stop, monitor-clean, etc.). D'autre part, Mesos supporte tous les types de noeuds au sein de son cluster (VM, conteneur (LXC, Docker), bare metal).
L'architecture de Mesos repose sur un pattern master/slave. Les slaves informent le master des ressources dont ils disposent via des offres. Ces dernières contiennent obligatoirement la quantité de CPU et de RAM disponible. D'autres ressources sont implémentées par défaut. Le master collecte les offres et les distribue aux frameworks. La notion de framework correspond au couplage d'un scheduler qui va, avec le master, lancer les tâches et d'un executor, facultatif, qui va exécuter les tâches. Pour éviter que le master et le scheduler ne deviennent des SPOF, il va être nécessaire de les redonder. C'est là qu'intervient Apache Zookeeper qui se base sur la notion de quorum pour l'élection d'un master, les autres devenant standby master.
Dans les faits, les serveurs dont on dispose sont toujours hétérogènes !
On peut définir ses propres ressources ce qui est pratique dans le cas d'un cluster que l'on construit petit à petit et dont les machines sont donc de puissances et fonctionnalités hétérogènes (ex: on achète une machine avec un GPU car on a besoin de traiter des images).
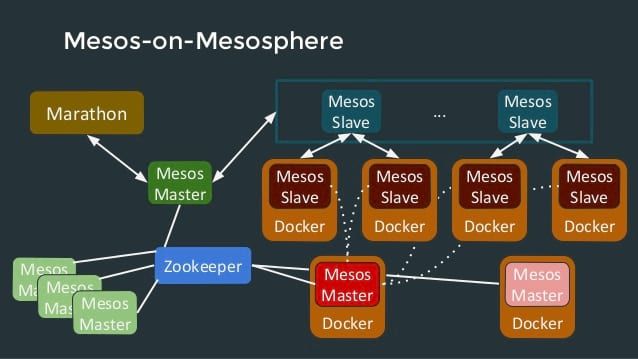
Mesos est un projet qui va apporter une grande valeur ajoutée à votre cluster de machine pour l'exploiter au mieux. Des frameworks tels que Marathon ou Chronos de la Mesosphere enrichissent le framework pour aisément pouvoir construire son propre PaaS et gérer ses jobs. Les speakers ont également mis en avant l'importance du DevOps dans l'utilisation réussie de Mesos. En effet les développeurs sont les mieux placés pour savoir les ressources dont ont besoin leurs applications pour fonctionner.
En conclusion, pour réussir son déploiement Mesos :
Keep C.A.L.M.S ! (Culture Automation Lean Measurement Sharing)
Uniformisez vos postes de développement avec Docker Compose (anciennement Fig) (Etienne Peiniau)
- CFP Devoxx
- Ressources : Github
Ce Quickie par Etienne Peiniau présentait l’outil Fig plutôt connu dans l’écosystème Docker, qui est devenu depuis peu Docker Compose suite au rachat par Docker. Il répond aux cas d'utilisation suivants :
- Déploiement des dépendances applicatives
- Réplication sur les postes de développement
Pour le configurer, on écrit un fichier docker-compose.yml dans son projet qui va assembler à la racine l'ensemble des services docker à bootstrapper.
Quelques commandes utiles (qui s'apparentent fortement à la ligne de commandes Docker) :
- docker-compose up : bootstraper l'ensemble des conteneurs
- docker-compose logs : voir tous les logs en sortie standard des conteneurs
- docker-compose ps : lister les conteneurs de cette composition
En conclusion, j'entendais souvent parler de Fig sans trop comprendre à quoi m'attendre. Après ce quickie, cet outil me semble à la fois indispensable et très simple à utiliser si on a déjà quelques bases en Docker.
Groovy's release process (Guillaume Laforge, Cédric Champeau, Fred Simon)
- CFP Devoxx
- Présentation : Full
Une présentation par l’équipe Groovy, dont Guillaume Laforge, et sponsorisé par JFrog, l’outil de management d’artéfacts utilisés par Groovy depuis peu. Le talk a permis de retracer l'histoire de Groovy et l'évolution de son processus de release pour finir par une petite apparté sur JFrog.
Groovy qui est un compilateur a des besoins spécifiques qui sortent du lifecycle classique de maven. Initialement le déploiement était effectué par Maven avec le plugin Jelly mais manquait de flexibilité. Il leur a été nécessaire de passer à Ant pour plus de souplesse avant de finalement utiliser Gradle, lui même basé sur Groovy.
Concernant l'intégration continue du projet, initialement celui-ci utilisait Codehaus qui :
- se base sur WebDAV pour pousser les artéfacts et la documentation
- prenait plusieurs secondes pour lister / changer de dossier
- prenait plus d'une heure pour uploader des centaines de fichiers Javadoc
- est en cessation d’activité depuis février 2015 et les dépôts sont en cours de migration
Finalement Groovy est passé à Team City développé par Jetbrains. Ce dernier dispose d'une communauté qui maintient des agents de build spécifiques à différentes plateformes. Les besoins de Groovy sont très spécifiques et il ont une grosse combinatoire à tester pour le langage :
- Plusieurs versions du JDK (6, 7, 8, 9)
- Invoke dynamic en 7+
- Toutes les branches de maintenances Groovy
- Backward compatibility avec Gradle, Grails, etc...
D'autre part il leur manquait une grande partie d'automatisation et de nombreux workflows ont été longtemps effectués manuellement (tagging, mise à jour de version, VCS, etc.) engendrant de nombreuses erreurs. Un autre problème se posait pour la maintenance des codes insérés dans la documentation qui finissaient par être obsolètes. Désormais, la documentation réalisée sous Ascii Doctor permet de tester tous les codes unitairement !

Finalement, Groovy utilise JFrog pour la gestion de ses artéfacts. Artifactory est l'équivalent d'un dépôt Nexus qui permet de gérer les différents snapshots générés à chaque commit. Il supporte Python, Debian, Docker, npm, maven, gradle, ivy, nuget, rpm, yum, etc. Bintray stocke les releases qui sont signées et déployées sur Bintray JCenter (synchronisé avec Maven Central). Le site web et la documentation peuvent être uploadés et mis à jour automatiquement.
Scaling Docker with Kubernetes (Carlos Sanchez)
- CFP Devoxx
- Présentation : Full
- Ressources : Github Plugin Jenkins
Google déploie près de 20 milliards de conteneurs par semaine ! Docker, qui adresse les applications orientées services essentiellement, est une nouvelle solution qui apporte ses propres problèmes...
Docker combine LXC et UFS (Union FS), un système de fichiers qui présente différentes couches. Linux est requis (cf. Boot2Docker MAC/WIN) mais on s'approche du Build once, run anywhere et de nombreux dépôts officiels sont disponibles pour récupérer les images Docker
Conteneurs vs VM :
Les conteneurs sont isolés mais partagent le même OS (et librairies lorsque c'est possible). Les VM virtualisent au dessus d'un OS Hôte ou d'un Hyperviseur qui va initialiser un OS complet pour chaque VM.
DevOps :
Docker est un outil orienté développeur car il permet d'exécuter son app localement, de la configurer et d'exposer le minimum. Il est orienté opérationnel car il permet de masquer l'application et de laisser les opérationnels se concentrer sur les problématiques d'infra.
Kubernetes a été crée par Google il y a un peu plus d'un an et vient adresser la problématique de gestion de conteneurs sur plusieurs hôtes. Il peut être qualifié de container cluster orchestration. Il permet de configurer de multiples hôtes (nodes / minions) grâce notamment à une API et offre la possibilité d'agir plus ou moins sur l'emplacement des conteneurs spawnés. D'autre part, il propose un monitoring plus haut niveau que Docker.
Kubernetes est composé d'un master qui joue le rôle de serveur d'API et se base sur ETCD pour la synchronisation de configuration. Il s'articule autour de nodes qui se composent à minima de Docker, ETCD, SkyDNS et Kubelet (qui s'assure de l'état des pods). Enfin les pods sont un groupe de conteneurs collocalisés qui partagent le même network/namespace/ip et volume (host mounted, empty volumes, GCE data disks, ...). Pour chaque pod on configurera le nom de l'image Docker, les ports à exposer, les volumes à monter et un label (tag) si nécessaire.
De nombreux fournisseurs de conteneurs existent déjà :
- Google Container Engine
- Azure
- vSphere
- Rackspace
- oVirt
- Vagrant
- CloudStack
- Ubuntu
- Tectonic (on top of CoreOS)
Carlos Sanchez a cité pendant sa session plusieurs projets/plugins autour de Kubernetes et le support déjà assuré par de nombreux providers nous pousse à vouloir tester rapidement cet outil !
*Data
InfluxDB : La base de données chronologique OpenSource autonome (Nicolas Muller)
- CFP Devoxx
- Présentation : Full
Un quickie de Nicolas Muller présentant la base de données InfluxDB, opensource par ErrPlane (MIT License) écrit en Go, taillée pour le stockage de séries temporelles. Une time serie est un regroupement d'événements qui se sont passés dans le temps :
- fichier log
- timeline twitter
- git commits
- pages vues
- ...
En 2015, on attend d'un outil de collecte, stockage et visualisation d'événements qu'il soit simple à installer et administrer, adapté au BigData, qu'il supporte HTTP et JSON et qu'il soit bâti sur des API. Ce n'est pas encore vraiment le cas des outils existants :
- Graphite : PB d'installation, pas de scaling aisé
- OpenTSDB
- Collectd
- Sensu
- DropWizard
- ...
InfluxDB répond à ces contraintes. Il est simple à installer et manager, n'a pas de dépendances externes, propose une interface HTTP et est scalable horizontalement. Il propose également l'échantillonnage de données par période de temps ce qui est une fonctionnalité souvent attendue.
InfluxDB est assez simple à appréhender. Il est basé sur le concept de Database équivalent à celui qu'on connait avec les SGBD classiques. Le concept de Time Series est une sorte de table pour le temps avec un sequence number et des colonnes. Une série temporelle est composée de points (ou événements) correspondant en quelque sorte aux lignes d'une base de données SQL. Enfin InfluxDB propose une langage SQL Like pour requêter des séries.
Nicolas Muller a évoqué un certain nombre de bonnes pratiques connues à ce jour.
InfluxDB est très adapté à des nombreuses séries avec peu de colonnes. Requêter sur des colonnes autre que le temps est possible mais entrainera de mauvaises perfs. Dans ces conditions, on crée autant de tables qu'il y a de valeur métier.
En terme de nommage, la règle à suivre est la suivante :
<tagName>.<tagValue>.serieName
Exemples v0.8 :
- arduino.uno.shield.ethernet.sensor.dht11.temperature
- arduino.uno.shield.ethernet.sensor.dht12.temperature
- arduino.uno.shield.wifi.sensor.dht22.humidity
- ...
En V0.9, les tags seront gérés directement par Influx :
{
name: <b>"temperature"</b>
tags: {
arduino: <b>"uno"</b>
shield: "ethernet"
sensor: "dht11"
}
}
A noter qu'une migration automatique en V0.9 d'InfluxDB sera possible si on a respecté la convention de nommage ci-dessus en V0.8 et inférieur. De plus, la nouvelle version de Grafana va supporter directement la V0.9.
InfluxDB semble être une techno prometteuse dans le domaine des séries temporelles omniprésentes de nos jours (IoT, monitoring, etc.). Le produit évolue rapidement et Grafana, l'un des incontournables de la DataViz, est associé à InfluxDB et OpenTSB qui permet des montées de versions synchronisées de ces outils.
Avro : la souplesse du JSON, les performances du binaire (Alexandre Victoor)
- CFP Devoxx
- Présentation : Full
Un quickie par Alexandre Victoor (SCGIB) présentant Apache Avro, un système de stockage initialement utilisé pour le stockage distribué dans Hadoop qui est maintenant un projet à part entière chez Apache.
Avro permet d’échanger du JSON (ou binaire ou autre) pour lequel on va pouvoir définir un schéma de référence pour ses données. Ainsi, à l’initialisation, client et serveur réalisent un HandCheck pour vérifier qu’ils sont en accord sur un schéma et commencer à échanger. Dans le cas contraire, la connexion est coupée.
Aux données échangées est associé un hash correspondant au schéma de données utilisé. Ceci permet de facilement faire évoluer un schéma d’échange de données dans Avro et de le diffuser petit à petit vers ses clients. Le schéma complet et donc stocké côté serveur et l’overhead à chaque échange est donc limité à quelques bits pour connaître l’identifiant du schéma.
Applications Concurrentes Polyglottes avec Vert.x (Julien Viet)
Julien Viet, ingénieur sur le projet Vert.x, nous a fait une présentation de ce framework polyglotte dont on entend beaucoup parler depuis un certain temps. Vert.x est un projet sous la fondation Eclipse financé par RedHat, actuellement en version 2.1.x de production, la version 3 milestone 4 est en cours de développement. Java 8 obligatoire depuis la version 3 qui utilise beaucoup les expressions lambda.
Vert.x est une stack pour développer des applications pour la JVM inspiré par Erlang/OTP et Node.js pour les paradigmes asynchrones non bloquants. Il est polyglotte (Java, JS, Groovy, JRuby, Jython, Scala, ...), léger et embarquable adapté aux hautes performances (support du cluster / failover).
Le framework suit le modèle réactif (il implémente reactive-streams en version 3) éliminant ainsi les problèmes de concurrence (l'utilisation du même thread au cours de l'exécution est garantie). Vert.x est composé d'un core léger avec peu de dépendances et expose une API asynchrone.
Vert.x est fondé sur deux principaux composants :
- Verticle qui est déployé dans Vert.x quel que soit le langage et exécuté sur un thread unique. La communication avec lui se fait par messages. De manière générale on va, pour une application donnée, tenter de séparer les différentes briques en autant de Verticles.
- Le Bus d'événements est le système nerveux de Vert.x. Il force l'isolation des Verticles qui échangent des messages grâce à lui. L'échange est essentiellement Point à Point de données immuables dans le format souhaité (généralement JSON ou byte).
Enfin, basé sur Nashorn et SockJS, Vert.x est également utilisable dans le navigateur qui fourni la même API que pour le serveur. En conclusion Vert.x favorise l'écriture d'architectures en microservices par son modèle asynchrone et sa communication par event bus. Sa compatibilité multilangages (automatisée à partir de la version 3) en facilitera d'autant plus son adoption.
Algorithmes distribués pour le Big Data (DuyHai DOAN)
- CFP Devoxx
- Présentation : Full
HyperLogLog est un algorithme qui consomme peu de mémoire pour gérer des compteurs sur un très grand nombre de données, moyennant une perte de précision de quelques pourcents. Pour cela, il faut calculer des probabilités basées sur les données rencontrés (hash a forte variabilité) en analysant le nombre de bits consécutifs à zéro. Il faut également faire des moyennes pondérées pour éviter que certaines valeurs occasionnelles faussent les résultats.
Paxos est un algorithme de consensus distribué. Dans les faits, un maître gère les conciliations et en cas de problème, un nouveau maître prend la main. Il est capable de terminer les travaux du premier. En cas de collision, un délai aléatoire est ajouté avant la reprise.
DuyHai DOAN a eu l’ambition de nous expliquer les algorithmes HyperLogLog et Paxos. Il s'est plutôt concentré sur les justifications sous-jacentes aux algorithmes que sur l'implémentation réelle ou l'utilisation. Mission accomplie !
Jeu de rôle massivement multijouer avec Firebase (Thomas Guerin, Alexis Moussine-Pouchkine)
- CFP Devoxx
- Ressources : Play Store
Pour finir la journée du jeudi, une présentation de la base de données Firebase en action dans un jeu vidéo aux allures d’Ingress ! L'objectif de ce tools-in-action était de faire un jeu android pour capturer les gares avant que les autres ne le fasse.
Firebase est une BDD NoSQL orientée document qui offre un mécanisme de synchronisation de la donnée en temps réel. Elle se charge pour nous de l'abstraction de la couche transport (WebSocket, SEE, ...), des problématiques de coupures réseaux et des fallbacks pour support les anciennes plateformes.
En plus de se charger du problème de synchronisation, Firebase propose de nombreux SDK qui permet de profiter de ce service pour toutes ses applications (Android, Java, Angular, iOS, Ember, React, Node, etc.).
Pour Egress, GeoFire a été utilisé pour apporter le support de la localisation. De manière concrète, on va créer un objet Firebase mappé sur l'url de la base de données. L'authentification sera gérée par Firebase (ex : ref.authWithOAuthPopup), puis on définit des callbacks côté client :
- geoQuery_stations.on("key_entered") : on sélectionne une zone sur la carte, geoQuery va chercher les gares correspondantes
- geoQuery_stations.on("key_exited") : on se déplace dans une autre zone, geoQuery va masquer les gares correspondantes
En conclusion, avec cette petite démo fun, on voit rapidement que Firebase va plus loin qu'une base de données classique. Non seulement elle propose un mécanisme de synchronisation des différentes applications par événements mais aussi elle offre des fonctions pratiques comme l'authentification, où la localisation via la librairie GeoFire.
Performance
Programmation Lock-Free : les techniques des pros (Jean-Philippe Bempel)
- CFP Devoxx
- Présentation : Partie 1, Partie 2
Jean-Philippe Bempel de ULLINK a partagé ses connaissances sur les différentes approches pour proposer des algorithmes sans verrou. Il a évoqué les implémentations proposées depuis Java 7 et les améliorations dans Java 8. Il a évoqué les algorithmes immuables CopyOnWriteArrayList<E> pour insister sur les impacts au niveau du GC.
La stratégie lock striping utilisée par l'implémentation Java 7 de ConcurrentHashMap<K,V> consistait à sharder les données en bloc pour y associer des locks. Cette approche n’est plus utilisée en Java 8.
Il a par ailleurs expliqué les différents type de barrières, gérées par le compilateur et/ou le processeur. Il a évoqué les différents types de verrous processeurs, en lecture et écriture. A noter qu'un processeur x86 n’a besoin que d’un lock en écriture, via des instructions assembleurs proposées par la classe Unsafe. Il a également rappelé que le passage en Kernel n’implique pas forcément un Context Switch. Cela dépend du traitement demandé. Il y a traversée en Ring 0 du processeur.
Finalement, il nous conseille de suivre le blog de Martin Thomson (Mechanical Sympathy) qui prône le rapprochement du code au plus près de la machine et du processeurs. Une conférence de très haut niveau, riche en information, simple dans les explications et technique comme on aime !
HAProxy level 2 : des bases aux problématiques de scaling (Nicolas Helleringer)
- CFP Devoxx
- Présentation : Full
Ce tools-in-action proposait un retour d’expérience sur l'utilisation de HAProxy dans un test géant effectué pour Critéo.
En résumé, HAProxy tient très bien la charge tant qu’il n’est pas saturé en CPU. Une petite combinaison d’outils permet d’avoir de la haute disponibilité entre plusieurs instances HAProxy.
Un monde où 1ms vaut 100 M€ (Thierry Abaléa, Alexandre Victoor)
- CFP Devoxx
- Présentation : Full
Dans le domaine de la finance de marché, les performances sont de l'ordre de la micro seconde. En effet, il faut profiter d'opportunités financières qui sont disputées par des dizaines de milliers de concurrents. Aux Etats Unis, les stock options représentent 1,1M de transactions par seconde.
Objectifs :
La conférence se construisait autour d'une application de finance de marché dont il fallait optimiser les performances. L'architecture initiale de l’application était la suivante :
- un thread unique qui va jouer le rôle d'event loop
- des threads qui interceptent les IO en amont et en aval
- la communication entre les deux est réalisée par une BlockingQueue
Pour se mettre en jambe, le talk a commencé par un petit quizz :
- Pour une matrice donnée, quel est le parcours le plus rapide entre :
- celui en ligne : car il est compatible avec les caches processeurs
celui en colonne: celui-ci invalidera constamment le cache le rendant inefficace
- Pour calculer une valeur absolue, il est plus efficace :
- d'utiliser Math.abs : on fait simplement une opération sur les bits
de faire un if sur le signe: les données étant aléatoire sur le signe, le mécanisme de prédiction du processeur va être inefficace et on va perdre beaucoup de cycle d'horloge à changer de branche de prédiction.
En matière de performance, l'une des obsessions est de constamment mesurer. Faire constamment du microbenchmarking avec JMH par exemple car une intuition d’optimisation peut se révéler fausse ou pire contre productive.
L’outil statistique est primordial dans les mesures de performance. Attention, utiliser la moyenne pour la latence d'un système n'est pas forcément une bonne solution car on n'a pas une distribution aléatoire de valeurs et la moyenne risque simplement d'être noyée dans la variation des valeurs. On utilise l'outil statistique percentile qui permet d'avoir la distribution de toutes les valeurs et de produire un histogramme (cf. HDRHistogram by Gil Tene pour réaliser des histogrammes avec impact minimal sur les performances).
Martin Thompson parle de "Mechanical Sympathy" pour réconcilier le code avec le matériel. En effet pour obtenir les meilleures performances il ne faut pas négliger la machine sur laquelle les instructions de notre programme vont être exécutées.
Pour avoir des performances optimales, on cherche à développer des algorithmes non bloquants, on veut ainsi au moins un thread en progression tout le temps. Plusieurs choix se posent sur le type de file à implémenter ConcurrentLinkedQueue, Queue SPSC ou encore Lamport Queue. Cette dernière utilise une file circulaire qui consiste en un tableau, un index d'écriture et un modulo. Ainsi on a un gain de débit de x4 entre BlockingQueue et Lamport Queue.
Notes sur volatile :
Le buffer (tableau) d'index sont stockés en "volatile". En Java 1.4 on a pas le comportement attendu car c'est le buffer qui est volatile pas la valeur à l'intérieur ! En Java 1.5, le volatile a plus d'utilité car il se base sur le principe d'happens before.
Exemple : si mon tableau a été écrit dans le buffer à un index 2, et qu'au moment de la lecture de l'index par mon consumer il vaut 3, celui-ci va quand même aller chercher la dernière valeur avec laquelle le thread en question à écrit dans le buffer, en l'occurrence 2.
D'autre part, le coeur d'un processeur a un Store Buffer qui permet au registre de limiter un peu les accès au cache L1. Le volatile a un coût lié au fait qu'à chaque accès, il va commiter le Store Buffer dans le cache L1 et vider ce buffer. On perd donc cette optimisation.
Il a été également évoqué l'utilisation d'un Chronicle Logback Appender basé sur un Memory Map File pour des raisons de performance, ou encore de surparallélisation et de context switching lié au changement de processeur d'exécution pour un thread.
En conclusion, un talk très abordable et très intéressant par deux ingénieurs de la SCGIB (Thierry Abaléa et Alexandre Victoor) concernant les enjeux d’une application haute performance en finance et les solutions qu’on peut avoir en Java. Des solutions rapides à mettre en oeuvre et efficaces et toujours la même obsession : mesurer !
Langage
Practical RxJava (Simon Baslé, Laurent Doguin)
- CFP Devoxx
- Présentation : Full
- Ressources : HOL, ReactiveX
Menée par Simon Baslé et Laurent Doguin, cette session était un Hands On Lab sur RxJava que j’ai trouvé très bien construit et où j’ai vraiment découvert et compris l’intérêt que peut avoir Rx dans son projet.
Le GitHub du HOL est fourni (et associé à un projet externe qui sert d’API défaillante https://github.com/simonbasle/practicalRxExternal) et chaque étape a une branche solution associée ce qui permet de comparer avec ce qu’on a fait.
Objectifs du HOL :
- Migrer une application Web composée de divers services, dont certains externes et utilisant des mécanismes de l’API java.util.concurrent vers une application RxJava
- Après la migration des premiers services, on commencera par faire compiler le code naïvement en faisant des appels bloquant dans les contrôleurs appelant ces services jusqu’à arriver à du RxJava full stack et un retour asynchrone avec le DeferredResult Spring.
- On se concentrera ensuite sur la réalisation du ExchangeRateService. Appel de deux API externes :
- Change Doge vers Dollar
- Change Monnaie A vers Monnaie B
L'API gratuite n'est pas fiable. Une API payante est plus fiable il faudrait l'utiliser seulement lorsque l'API gratuite ne marche pas. Etant donné l'API payante, il faudrait tracer les coûts.
Solution :
- Pour compter les coûts, compteur dans l'AdminService
- On wrappe dans un onErrorResumeNext
- On ajoutera un doOnNext pour le logging
ReactiveX est inspiré de Microsoft .NET (linq, rx) porté en Java par Netflix OSS. Il peut être intéressant d'utiliser RxJava dès lors que l'une des problématiques suivantes se présente : Asynchrone, Event Based, IO. Rx vient combler les limites de certains langages et offre des fonctions de composition, transformation, filtrage, gestion d'erreurs avancé, temporalité :
- Java Future => rapidement bloquant (appel à get)
- Callback hell
- Pas de composition
- Limite gestion d'erreurs, d'exceptions, annulations, synchronisation, etc...
Ceci mène souvent à un code plutôt illisible, en tout cas peu autoportant.
Le principe est simple, généralement en Java on manipule les collections en pull (pattern Iterable / Iterator). En RxJava, on va plutôt faire du push de données (pattern Observable / Observer). La donnée devient un flux, poussé vers le consommateur.
- Observable est un flux connectable à un Observer
- Observer propose les actions :
- onNext : déclenchée pour chaque arrivée d'élément
- onError : déclenchée lors d'une erreur
- onCompleted : déclenchée lorsque le flux est terminé
Le framework offre un grand nombre d'opérateurs utiles en tout genre. En voici les principaux :
- Création
- from : créé à partir d'une collection de données
- just : créé à partir d'un objet
- create : créé from scratch
- Sélection
- take : sélectionne n élément à conserver
- single[OrDefault] : retourne l'unique élément attendu, jette une exception sinon
- first[OrDefault] : retourne le premier élément et arrête le flux où jette une exception en cas d'absence
- last[OrDefault] : retourne le dernier élément et arrête le flux où jette une exception en cas d'absence
- filter : sélectionne uniquement les éléments répondants au prédicat fourni
- Collecte
- toList : agrège tous les éléments émis dans une liste jusqu'à ce qu'à complétion de l'émetteur
- toBlocking : permet de retomber dans un comportement synchrone bloquant
- Transformation
- flatMap : chaque élément obtenu est transformé via un "flatMap" en une liste d'autres éléments et mis dans une liste commune qui sera rendu lorsque la méthode "onComplete" est invoquée
- reduce : à partir d'un flux d'événements on va appliquer une méthode qui va nous donner un résultat en sortie onComplete
- Trigger
- doOnXXX : permet d'ajouter un intercepteur sur chaque événement d'un Observable
- Combinaison
- concat : fusion de deux flux l'un après l'autre (bout à bout)
- merge : entrelacement des deux flux selon l'ordre d'arrivée des éléments dans les flux
- Résilience
- retry : on retente un certain nombre de fois l'opération tant qu'une erreur est remontée
- onErrorResumeNext : on wrappe le flux dans cette méthode, s'il plante, on peut effectuer un autre appel
L'intérêt du paradigme réactif ne se fait sentir que s'il est déployé sur toute la stack de l'application. Il est pour cela nécessaire que notre framework REST permette de retourner des "promesses de réponse". DeferredResult est un object de Spring qui permet de retourner des réponses REST asynchrone.
Observable<Map<String, Object>> costObservable = adminService.costForMonth(year, month)
.map(cost -> {
Map<String, Object> json = new HashMap<>();
json.put("month", month + " " + year);
json.put("cost", cost);
json.put("currency", "USD");
json.put("currencySign", "$");
return json;
});
DeferredResult<Map<String, Object>> deferredResult = new DeferredResult<>();
// Souscription du DeferredResult à l'Observable
costObservable.subscribe(
deferredResult::setResult,
deferredResult::setErrorResult
);
return deferredResult;
Avec l’utilisation de DeferredResult, on est enfin complètement asynchrone puisqu'on n’attend pas le résultat de manière active. On ne fait pas de timeout, si le résultat n'arrive pas, on ne fait pas d'attente active, Spring pourra faire autre chose. A noter que DeferredResult est bien un objet Spring et n’a rien à voir avec RxJava. RxJava ne propose pas d’outil pour réaliser des retours asynchrones d’appel HTTP, c’est à la charge du framework utilisé (en l’occurrence Spring). A noter RatPack, une alternative à Spring pour les WebServices http://ratpack.io.
Un hands-on bien mené qui nous a bien montré les intérêts directs que l'on peut avoir à utiliser Rx (polyglotte, performance, fallbacks, etc.).
Ceylon Idioms (Gavin King)
- CFP Devoxx
- Présentation : Full
Ceylon est un langage de programmation sur la JVM à l’instar de Scala ou Groovy qui a passé le stade de la 1.0 il y a quelques mois maintenant. Cette présentation proposait de passer en revue une dizaine d’idiomes intéressants du langage et il est vrai que son système de typage est assez bluffant.
Ceylon dispose déjà de nombreux outils dans son écosystème et est compatible avec de nombreux contextes d'exécutions (Java SE, OSGi, Vert.x, Node.js, Browser, etc.).
Parmi les fonctionnalités caractéristiques :
- Langage multiplateforme grâce à la JVM
- Réification des types génériques (accès au typage générique au runtime)
- Union et intersection de types
- De nouveaux types Nothing ou Anything qui ne sont que la combinaison de types déjà existants
- De nouvelles représentation telles que Tuple ou Function
Tout d'abord, la combinaison des types permet d'avoir des fonctions à plusieurs types de retour potentiel sans avoir besoin de passé par un super type.
File|Path|SyntaxError parsePath(String path) => ...
switch(result)
case(is File|Url)
...
Il est possible d'avoir des collections d'objets hétérogènes fortement typés où l'on pourra jouer avec le switch de Ceylon pour effectuer le traitement adéquat.
List<Integer|Float> list = ArrayList { 1, 1.0, 1 };
Null|Integer|Float elt = list[3];
Le type Tuple est géré avec une LinkedList qui ne lui donne aucune limite et est utilisé pour définir dynamiquement une liste de paramètres à passer à une fonction.
[Protocol,Path] protocolAndPath = parseUrl("...");
// équivalent à
Tuple<Protocol, Path> protocolAndPath = parseUrl("...");
[Integer, Integer, String] tuple = ...
function f(Integer x, Integer y, String string) => x+y
Callable<Integer, [Integer, Integer, String]> callable = f;
Integer integer = f(*tuple)
Gavin King présentait en tout 9 idiomes. La souplesse du système de typage est ce qui m'a le plus marqué dans ce langage et donne envie d'aller plus loin avec et de voir un peu plus ce qu'il permet dans le domaine fonctionnel.
Modular Java Platform (Jigsaw JDK 9) (Brian Goetz)
Brian Goetz est venu nous présenter Jigsaw, le projet de modularisation du JDK dont on commence à désespérer la sortie reportée depuis le JDK 6 ! Jigsaw c'est la volonté de rendre la plateforme Java SE modulaire et de se débarasser du classpath et du rt.jar.
Motivations :
- Java a commencé comme une petite plateforme de ~2500 classes
- Désormais java a grandi mais il est toujours nécessaire d'avoir toute la plateforme même si on ne se sert que d'une partie (JRE = 55Mb)
- Les classes sun.* et *.internal.* sont des classes internes au JDK dont on ne devrait jamais a avoir utiliser directement. Dans les faits, il faut utiliser SecurityManager::checkPackageAccess dans chaque classe pour assurer l'isolation...
- Jar Hell : le problème apparaît du fait que le classpath n'a aucune information sur les choix a effectuer lors d'un possible conflit (lié à l'import de versions différentes du même jar par exemple)
La solution à ce problème de classpath, de sécurité est d'apporter un système de module (une cinquantaine) au JDK utilisable par le Java SE lui même mais aussi par les autres projets. Pour le problème de taille du JDK, la version 8 a commencé par apporter les profils compact :
- compact1 : 11MB
- compact2 : 17MB
- compact3 : 30MB
Le projet Jigsaw a connu du tumulte. Le premier gros travail a été d'identifier les dépendances existantes entre les différents potentiels module du JDK. Désormais, le projet est séparé en 4 JEP :
- JEP 200 : The Modular JDK
- JEP 201 : Modular Source Code
- JEP 220 : Modular Run-Time Images
- JEP TBD / JSR 376 : Java Platform Module System
La JEP 200 a proposé l'ajout d'une nouvelle méthode getModule() à Class permettant de connaître le module qui a chargé la classe.
$ java -XListModule => liste les modules chargés
jar:file:/path/to/jdk/jdk8/jre/lib/rt.jar|/java/lang/Class.class // Java 8-
jrt:/java.base/java/lang/Class.class // Java 9
Les modules peuvent dépendre les uns des autres mais il existe deux types de dépendances :
- Implementation Dependency : utilisé par le module mais non exposée pour les autres modules qui vont l'importer
- API Dependency : une dépendance qui va être nécessaire pour les modules qui vont utiliser le module en question.
Ceci règle le problème d'exposition des packages internes sun.* et *.internal.*.
_La JSR 376 p_ropose un moyen pour les développeurs de définir leurs propres modules. Elle prévoie :
- une API Reflection pour les information du module
- l'intégration avec les outils (Maven, Gradle, IDE, etc)
- l'intégration avec les package managers (RPM, etc.)
- la configuration dynamique des graphs de module (EE Containers)
Finalement j’ai trouvé la présentation très intéressante et le projet à l’air d’avancer correctement !
Java; the next 20 years (Brian Goetz)
- CFP Devoxx
- Ressources : JEP
Après avoir rappelé les évolutions du langage pour proposer les classes génériques, Brian Goetz nous parle des Value Object pour regrouper les attributs des classes en mémoire et dans les conteneurs, afin de réduire le travail du Garbage Collector et les cache-miss du processeur lors de la navigation dans les objets. Cela permettra d’avoir les mêmes performances que le C++ ou C#. C’est une bonne évolution pour les algorithmes à haute fréquence.
Outils
Le taré du terminal : Outil pour développeur de l'extrême (Emmanuel Bernard)
- CFP Devoxx
- Présentation : Full Asciidoc
Présentation d’Emmanuel Bernard (Red Hat, Cast Codeurs) sur sa manière d’utiliser son outil de travail en automatisant au maximum son workflow, pour éviter le context switching durant son travail.
Il nous a notamment parlé de son environnement de commande TMux qui offre la possibilité de préparer plusieurs "univers" qui vont permettre de conserver différents contextes de travail. Il est également un grand friand de Vim qui offre un système de commandes efficace basé sur le pattern suivant :
[action][repetition multiplier]movement
- d2f. : supprimer 2 lignes et avancer jusqu'au prochain "."
- shift + v : mode visuel vim
- set col "n" : largeur du document
- gq : mettre la sélection trop large à la bonne largeur de document
- J : mettre la sélection trop courte à la bonne largeur de document
- 0 : début de la ligne
- W : mot suivant
- dW : supprimer le mot suivant
Il existe également des plugins IdeaVim (IntelliJ) ou Vrapper (Eclipse) qui permettent d'avoir un environnement Vim dans son IDE préféré.
Plusieurs automatismes quotidiennement utilisés par Emmanuel :
Lorsque je me connecte pour la première fois à un serveur, on me demande mon mot de passe et j'envoie automatiquement ma clé ssh en autorized_keys.
Lancer une pull request qui faire le merge et l'ouverture du navigateur à la bonne page automatiquement.
Utiliser remote pour lancer compilation et tests en background et lancer une notification desktop à la fin permettant de faire du context switching efficace sur ses réseaux sociaux !
Le leitmotiv de ce talk fût finalement de ne pas hésiter à automatiser un maximum de tâche que l'on répète ne serait-ce que quelques fois par semaine. Pour s'inspirer, une communauté existe autour des dotfiles qui permet de trouver plein d’exemples (cf. https://dotfiles.github.io) qui donne vraiment envie de s'y mettre ! De même pour Git ou l'utilisation d'alias peut-être un premier gain de temps mais l'écriture d'un plugin relativement simple peut rendre de grands services aussi.
Un Jenkins amélioré avec Docker, Mesos et Marathon (Jean-Louis Rigau)
- CFP Devoxx
- Présentation : Full
- Ressources : TIA Mesos
Inspiré de Delivering Ebay's, ce Tools in Action par Jean-Louis Rigau consistait à présenter rapidement un use case d’utilisation d’Apache Mesos et un de ses framework, Marathon, pour rendre son Jenkins fortement scalable !
Objectifs du Tools in Action (TIA) :
- Simplifier la gestion de Jenkins en le conteneurisant avec Docker et le déployer dans Mesos via Marathon
- Utiliser les ressources de Mesos pour créer des slaves Jenkins à la demande
Jenkins est un serveur d'intégration continue, maintenu par Cloudbees, écrit en Java. Ceux qui l'utilisent savent qu'il est généralement difficile à maintenir et à mettre à jour !
Docker est un gestionnaire de conteneurs opensource, écrit en Go, créé et maintenu par Docker Inc. Il sert à la construction d'applications et au déploiement sur tout type d'environnement.
Mesos est un gestionnaire de cluster opensource par Apache, écrit en C++. Il permet de gérer les ressources de son Datacenter et de se créer son propre cloud en allouant intelligemment ses ressources selon les besoins de ses applications.
Enfin Marathon est un framework Mesos opensource par Mesosphere qui est écrit en Scala. Il se charge du déploiement et management de conteneurs basés sur Mesos et joue en quelque sorte le rôle de sur couche simplificatrice.
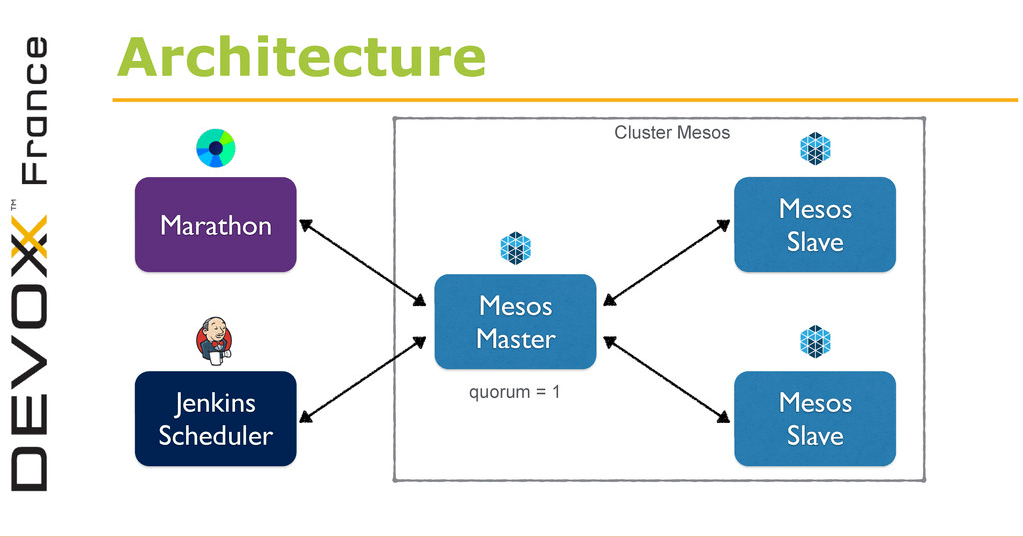
En bref, le schéma d'architecture qui nous a été présenté lors du tools-in-action. J'achète si cela peut permettre de retrouver confiance en son Jenkins !
Le Continuous Merge chez LesFurets.com (Pflieger Arnaud)
- CFP Devoxx
- Présentation : Full
- Ressources : Github
L’équipe des furets ont fait le choix d’utiliser Git en mode feature branch. Malgré toutes les alertes sur cette approche, ils ont persisté et proposé des plugins à Git pour faciliter le merge multiple. L’idée est de sélectionner avant la mise en production, l’ensemble des branches à lier. Le résultat est placé dans un branche tampon sans historique. Les problèmes peuvent alors être résolus suivant plusieurs approches :
- faire un rebase d’une branche sur une autre pour aider au merge global
- ajouter des features flags
- etc.
Avec cette approche, ils publient plusieurs fois par jours.
Mais aussi...
Devoxx c'est 200 conférences en 3 jours et des choix à chaque session difficiles à faire ! Ci-après vous trouverez quelques conférences en vrac, non moins intéressantes !
- Le futur de la robotique personnelle (Rodolphe Gelin) : Cette conférence a été un grand moment. Des démonstrations en vidéo ont montrée où se focalise les recherches en ce domaine. Les robots doivent prélever les informations, deviner les sentiments du locuteur et analyser les signaux sonores pour savoir qu’on leur parle. C’est bien plus complexe qu’utiliser Google Now ou Siri.
- La problématique du contrôle des technologies de l'information (Eric Filiol) : Eric Filiol, grand prêtre de la sécurité nous a expliqué que nos dirigeants proposent des lois inapplicables car ils ne comprennent rien et sont faibles. Cela donne l’illusion de la sécurité, en offrant toute les dérives possibles sur un plateau. Il nous rappelle que les bugs que nous laissons sont les portes ouvertes à notre propre vie privée. Pensons-y !
- I don't always write Reactive applications, but when I do, it runs on Raspberry Pi (Alexandre Delegue) : Une conférence très amusante où une pile de Raspberry Pi organisés en Cloud mobile est utilisée pour un site de commerce codé avec les stacks réactives Scala, Play et Akka.
- La phygitalisation, le super pouvoir du développeur pour créer des objets connectés! (Cyril Lakech) : Avec quelques centaines d’euro, un RaspberryPI, un Arduino, du cable et des LED, ils nous expliquent comment ils ont monté un rayon augmenté. Des leds s'allument et s'éteignent au fur et à mesure de l’ajout des critères de recherche. Cela permet de retrouver plus facilement un produit en rayon. Le code est ridiculement simple et l’expérience est top !
- Un robot peut-il apprendre comme un enfant ? (Pierre-Yves Oudeyer) : Pierre-Yves Oudeyer, directeur de recherche à l'Inria, nous a fait une démonstration d’un robot qui analyse son environnement au hasard, puis privilégie certaines pistes pour améliorer efficacement sa connaissance. Voir un robot sur un tapis pour bébé, jouer avec des mobiles ou communiquant avec un autre robot c’était vraiment sympathique et incroyable d'autant plus quand on sait qu’ils ne connaissaient rien avant de commencer.
- The upcoming decentralisation singularity. (Stephan Tual) : Stephan Tual nous propose de découvrir Ethereum une machine de Turing complètement décentralisée, dérivé des travaux sur les Bitcoins. Ce projet permet de mettre à disposition des développeurs une plateforme résistante aux fraudes.
- Recettes CQRS, pour bien cuisiner son architecture (Thomas JASKULA) : Thomas JASKULA nous parle de son expérience sur des architectures CQRS (Command Query Responsibility Segregation). Il sépare la notion de commande synchrone et d’événement asynchrone. Il propose d’isoler les sous-systèmes en mode DDD (Domain Driven Design) et de les relier via un bus de message. Il propose également la méthode agile “Event Storming” proposée par Alberto Brandolini.
- http/2: A deux c'est mieux ! (Jean-François Arcand) : Jean-François Arcand nous présente les nouveautés de HTTP/2. Il explique en quoi cela représente une évolution importante. Il a la crainte que cela prennent des années avant de pouvoir l’utiliser partout, comme pour l’IP v6 qui date de 1996 ! La norme étant toute récente, il y a encore peu de retours d’expérience. Les évolutions de J2EE pour intégrer cela ne sont pas de son goût. Il préférerait une remise à plat des API pour exploiter au mieux HTTP/2 plutôt que d’étendre les API actuelles des servlets.
- Infinite Infinispan (Ray Tsang) : Une équipe de Google nous explique comment Infinispan permet d’ajouter et surtout d’enlever dynamiquement des machines. Il y a des scénarios plus complexes que d’autres mais il faut retenir que c’est une problématique à intégrer dès le début de la réflexion des architectures élastiques. A noter qu'Infinispan est régulièrement utilisé comme un cache distribué.