Devops corner, épisode 1 : Chef pour les nuls
Cet article est le premier d'une longue (enfin je l'espère) série d'articles visant à partager des retours d'expériences autour de Devops, issus de travaux internes ou de missions chez divers clients. Ils sont aussi l'occasion de détailler un peu plus la session que j'ai présenté récemment à Devoxx France : déploiement d'environnements complets dans le Cloud, en utilisant Rackspace, Capistrano et Chef.
Cette session présentait un système de déploiement automatisé, d'une plateforme complète (applications, infra réseau, monitoring), sur le cloud (AWS, Rackspace ou OpenStack) pour Fasterize. Les gains apportés par un tel système sont importants :
- Pouvoir toutes les nuits redéployer des environnements from scratch et lancer des tests de non régression, qui couvrent à la fois le déploiement et le fonctionnel
- Quasiment plus d'opérations manuelles sur les serveurs
- Une grande facilité à faire évoluer l'architecture
- Scalabilité : ajouter des noeuds en une ligne de commande
Pour en revenir à cette série d'articles, voici quelques exemples de sujets qui devraient être traités :
- Chef pour les nuls
- Les limitations de Chef, et comment les contourner
- Chef solo ou Chef Server
- Template de machine virtuel et/ou déploiement automatique ?
- La configuration : système, réseau, applicative
- Capistrano pour les nuls
- Utiliser Capistrano et Chef ensemble
- Fog pour abstraire le cloud
- Open sourcing de scripts / outils
- ...
Commençons par le sujet du jour : Chef pour les nuls.
Pourquoi une introduction à Chef alors qu'on en trouve des dizaines sur Internet ? Parce que je vais me baser sur les notions présentées ici dans les articles suivants.
Chef, c'est quoi ?
Voici le "magnifique" slide que j'ai présenté à Devoxx.
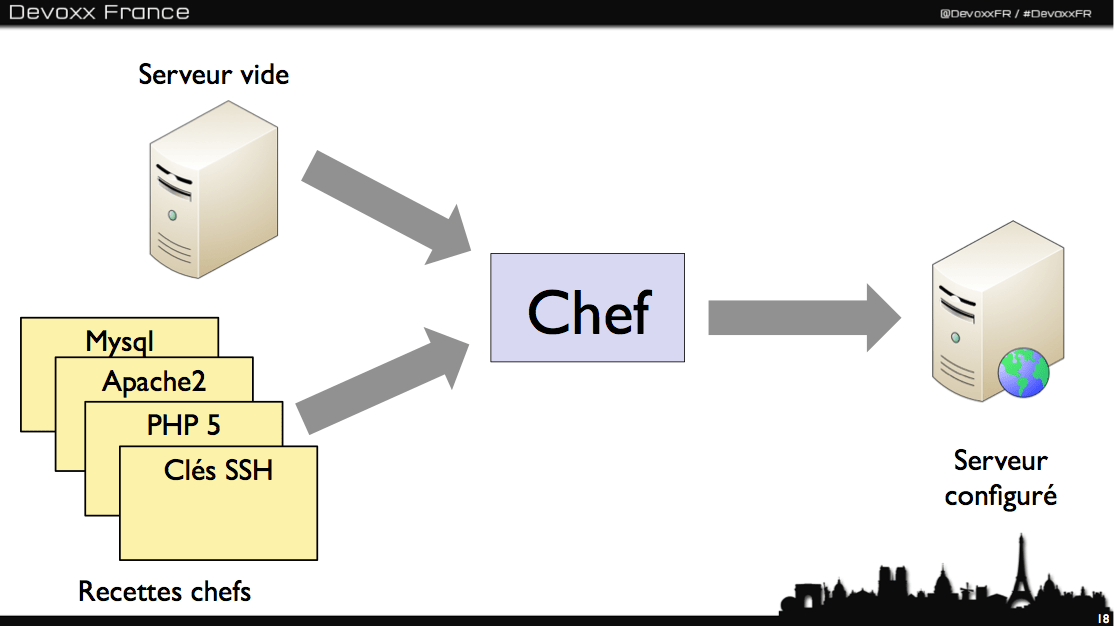
Vous prenez un serveur vide, des recettes Chef, vous secouez bien (comprendre vous lancez Chef), et pouf, votre serveur est configuré.
Chef est donc un outil pour configurer des machines (appelées "node" dans la terminologie Chef). Cela permet par exemple :
- D'installer des packages (exemple : apache2)
- De configurer ces packages (exemple : ajouter un virtual host à apache2)
- De configurer le système d'exploitation (exemple : d'ajouter des clés SSH)
- ...
Chef n'est pas qu'un simple moteur de scripts shell : il a plutôt une approche descriptive: vous décrivez ce que vous voulez, et Chef se charge de l'installer. Quelques caractéristiques de chef :
- Idempotent : Vous pouvez le relancer plusieurs fois sans problèmes, il ne fera que le nécessaire à chaque fois.
- Mutli plateforme : Chef est basé sur Ohai, qui fournit des informations sur le système d'exploitation, de manière agnostique. Chef est aussi un début d’abstraction mutli platforme : il fonctionne aussi bien sous Debian que sous Fedora, ou sous Mac OS ou Windows (mais je n’ai pas essayé). Un exemple : la ressource
packageva savoir si il faut utiliserapt,rpmouyum. - 2 modes de fonctionnement : en solo, ou en mode client-serveur. Plus de détails ci dessous.
- Open source: Chef est Open Source et maintenu par Opscode
Note : Chef est un outil qui se positionne comme Puppet ou CfEngine. Voir ici pour le pourquoi de ce type d'outils. Chez Octo, nous avons choisi Chef, parce qu'il fallait en choisir un et que Chef nous paraissait plus extensible que Puppet (car il utilise le langage Ruby au lieu d'un DSL). Nous ne regrettons pas ce choix. Mais même si nous avons choisi un outil, les sujets traités dans les articles suivants s'appliqueront souvent autant à Chef qu'à Puppet.
Comment ça marche ?
Chef est écrit en Ruby. Il est basé sur le concept de ressources : vous décrivez une liste de ressources, que Chef va déployer. Quelques exemples de ressources : un fichier, un package, un service... La liste des ressources de base fournies par Chef est ici.
Ces ressources vont être regroupées dans des recettes, que vous allez devoir écrire (ou réutiliser).
Qu'est ce qu'une recette ? C'est une description de plusieurs ressources qui forment un ensemble cohérent. Par exemple, nous allons décrire une recette pour memcached. Concrètement, une recette, c'est un ensemble de fichiers écrits en Ruby, organisés d'une certaine façon. Une recette est un dossier contenant les sous dossiers suivants :
- attributes : des paramètres de configuration pour la recette
- recipes : les recettes
- templates : les modèles de fichiers (notamment de configuration) que nous allons déployer
- definitions, libraries, ressources, providers : des dossiers pour étendre vos recettes, créer des nouvelles ressources. C'est hors du périmètre de cet article.
Prenons un exemple. (Si vous ne voulez pas lire l'exemple maintenant, vous pouvez sauter à la fin de l'encart gris). Voici la structure d'une recette pour déployer memcached: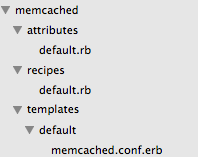
La recette proprement dite, c'est le fichier memcached/recipes/default.rb :
package "memcached"
template "/etc/memcached.conf" do
source "memcached.conf.erb"
variables :port => node.memcached.port
end
On déploie donc 2 ressources :
- Le package
memcached - Le fichier de configuration
/etc/memcached.conf, qui est basé sur un modèle ERB, dans lequel on va remplacer la variableport, par sa valeur cible, contenue dansnode.memcached.port(voir l'explication sur les attributs ci dessous). Voir ici pour plus d'informations sur les modèles.
Le fichier ERB memcached.conf.erb est dans memcached/templates/default :
# memcached default config file
-d
logfile /var/log/memcached.log
-m 296
-p <%= @port %>
-u nobody
-l 127.0.0.1
-P /var/run/memcached.pid
En plus de ces 2 fichiers, il en faut un troisième pour les attributs default.rb, dans memcached/attributes :
default[:memcached][:port] = 11211
Cela permet d'ajouter un attribut au noeud courant, avec un valeur par défaut. Cet attribut est utilisé dans la recette, par node.memcached.port. Chef dispose d'un système de configuration par couche, très bien conçu, qui permet de surcharger la configuration à de multiples endroits.
On peut par exemple utiliser les rôles pour surcharger les configurations. Un rôle est un fichier Json qui contient :
- Une liste de recettes ou d'autres rôles à exécuter
- Une surcharge de fichier de configuration
Exemple cache.json :
{
"name":"cache",
"default_attributes":{
"memcached": { "port" : 11212 }
},
"json_class":"Chef::Role",
"env_run_lists":{},
"run_list":["recipe[memcached]","recipe[munin]"],
"description":"",
"chef_type":"role",
"override_attributes":{}
}
Ce fichier déclare un rôle cache, pour lequel il faut exécuter les recettes memcached et munin (un outil de monitoring), et où le port de memcached sera 11212.
Note : ces exemples sont disponibles sur github.
Comment jouer avec ?
Chef a 2 modes de fonctionnement :
- chef-solo : Dans ce mode, les recettes et rôles sont des fichiers locaux sur le serveur. Chef-solo est autonome, ne fait pas d'appels distants sur un serveur, et est lancé par une commande shell.
- chef-server / chef-client: Il s'agit du mode client/serveur de Chef, dans lequel le serveur contient les recettes et les rôles. Dans ce cas, il y a généralement un démon qui tourne sur chaque machine à configurer, qui se lance toutes les X minutes. Il télécharge alors les recettes sur le "Chef serveur", pour les exécuter localement.
Nous avons choisi d'utiliser le mode chef-solo. Ce choix fera l'objet d'un article à lui tout seul :).
Cela étant dit, pour jouer avec chef-solo, il vous faut plusieurs choses :
Le script chef-solo
Pour l'installer, il y a plusieurs solutions :
gem install chefsi vous avez un environnement ruby configuré.apt-get install chefsi c'est packagé dans votre distribution.
Aucune de ces deux méthodes ne nous satisfait vraiment, cela sera le sujet d'un prochain article.
La documentation officielle d'installation est ici.
Fichiers de configuration pour chef-solo
Il faut deux fichiers de configuration pour chef-solo. Le premier est un fichier Ruby : solo.rb, dont le contenu minimal est :
json_attribs "run_list.json"
cookbook_path "/path/to/cookbooks"
La première ligne indique un fichier json contenant la liste des recettes à exécuter. Par exemple :
{"run_list":["recipe[memcached]"]}
La seconde ligne de solo.rb pointe sur le répertoire contenant les recettes Chef.
Recettes Chef
Où trouver des recettes ? Vous pouvez les écrire vous même, ce n'est pas très compliqué. Sinon, il y en a plein sur internet chez 37 signals, Opscode (la boîte derrière Chef), ou là (ceci est un spoiler pour la suite).
Pour utiliser l'exemple memcached ci dessus, vous pouver cloner le dépôt github (git clone git://github.com/bpaquet/devops-corner.git), puis aller dans le dossier devops-corner/chef_for_dummies. Tous les fichiers nécessaires au lancement de Chef y sont.
Go !
Une fois que vous avez tout ça, il ne reste qu'à lancer Chef :
chef-solo -c solo.rb
Et c'est parti !
Conclusion
Cette introduction très rapide sur Chef nous servira de base pour les articles suivants. Pour aller plus loin :
- les services et les notifications : voir ici.
- les exécutions conditionnelles ici.
- les recettes écrites par 37 signals et Opscode
- écrire son propre fournisseur de ressources : ici.
C'était l'épisode 1. N'hésitez pas à utiliser les commentaires pour des suggestions d'améliorations ou pour poser des questions...