De l’applicabilité de certains principes du « manufacturing » aux chaînes de batch - Part 1
On parle beaucoup des principes Lean appliqués à l’IT, de théorie des contraintes, on essaye de voir comment ces concepts, ces pratiques voire ces « philosophies » s’appliquent ou s’adaptent à notre monde informatique. Alors, je me suis lancé, avec humilité croyez moi, dans un exercice de style : appliquer certains principes du manufacturing pour optimiser une chaîne de batch, ie. augmenter le nombre d’éléments traités dans la fenêtre de batch disponible.
Une chaine de batch n’est rien d’autre qu’un ensemble d’étapes qui transforment, enrichissent des données en d’autres, plus riches
Imaginez une chaine de construction d’un produit quelconque. Cette chaîne n’est rien d’autre qu’un ensemble d’étapes qui transforment – au sens le plus large du terme – une matière première elle-même introduite en début de chaîne. Formulé autrement et de façon moins abstraite, prenez une chaine de construction de téléphones portables. On peut schématiser et simplifier cette chaîne pour la voir comme un ensemble d’étapes qui vont assembler, transformer, valider des composants électriques unitaires (résistances, transistors…) pour en faire un produit vendable : un téléphone portable.
Mais comment relier la chaine de batch et une chaîne de montage ?
Simplement en voyant une chaîne de batch comme un ensemble d’étapes qui transforment, enrichissent des données, des fichiers pour générer d’autres données, d’autres fichiers. Si vous n’êtes pas d’accord avec ce modèle, arrêtez-vous là, vous n’aimerez pas la suite ;-)
Prenons un cas concret et illustrons cela avec une chaine de batch qui prend en entrée des fichiers contenant des millions de lignes. Chacune de ces lignes qui en fait correspondent à des opérations bancaires (par exemple, virement, prélèvement convention carte bleue..) devra être traitée, transformée, enrichie. En sortie de cette chaine de batch, d’autres fichiers correspondant concrètement à des évènements comptables. Entre les deux, les grandes étapes détaillées ci-dessous.
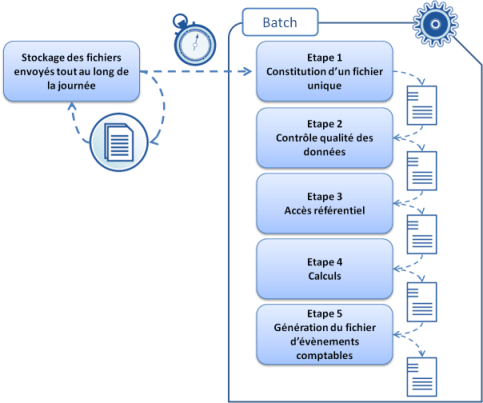
Tout au long de la journée, des fichiers sont stockés et accumulés puis à 20h, la chaîne de batch démarre et traite l’intégralité des opérations, des lignes, stockées. Et comme de bien entendu, notre intention est simple : augmenter le nombre d’opérations, de lignes traitées dans la fenêtre de batch disponible…
Mesurer et détailler pour optimiser au mieux
« C’est du bon sens » dirait un sceptique. Effectivement. Du coup, il est facile d’établir le tableau suivant et de représenter la répartition des temps de traitement par étape :
Mais ce n’est pas tout. Regardons en détails le temps de traitement d’une opération dans cette chaîne :
Ce que l’on remarque c’est qu’une opération, prise à l’unité n’est en fait traitée que sur une infime partie du temps total de traitement. Par exemple, lors du passage de l’étape 2, la première opération, la première ligne du fichier est traitée en quelques secondes puis stockée en sortie de cette étape dans un fichier où elle attend 15 minutes avant de passer à l’étape 3. Toujours en entrée de cette étape 2, la dernière opération patiente 15 minutes avant d’être traitée et d’être écrite dans le fichier en sortie de l’étape 2. Bref, chacune des opérations attend globalement 15 minutes (une partie en amont et en aval de l’étape) sur l’étape 2. Cette analyse se répète bien entendu sur chacune des étapes et elle permet d’observer qu’une opération passe en fait énormément de temps à attendre, avant d’être traitée…
Ce que nous dit le « manufacturing », c’est qu’il faut lotir ; séparer le fichier en un ensemble de fichiers de plus faible volumétrie pour optimiser le temps de passage, réduire en amont et en aval le temps d’attente des opérations
Bien lotir permet de réduire mécaniquement les temps de traitements
Imaginons que l’on décide de lotir en sortir de l’étape 1. Il existe un optimum pour la taille du lot ; ie. un fichier trop léger ou trop volumineux dégradera les temps de traitement mais peu importe. Imaginons pour notre exemple que l’optimum soit 3 : le fichier issu de l’étape 1 est loti en 3 fichiers de tailles moins importantes et chacun des fichiers est alors traité de manière séquentielle :
Si l’on observe à nouveau les temps de traitements et le séquencement des étapes, voilà le résultat :
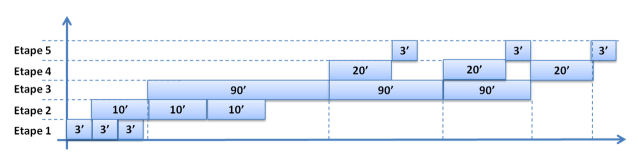
Une remarque tout de même : Il existe une limite dans nos systèmes que n’a pas le manufacturing : les ressources (CPU, mémoire…) des machines. En effet, l’exécution conjointe des étapes 2 et 3 n’est possible que si les machines ont assez de ressources.
Ce que l’on remarque :
- c’est que le temps total de traitement est passé d’environ 6h à environ 5h : un gain d’une heure « simplement » en lotissant un peu mieux les fichiers.
- Que les premières opérations « sortent » de la chaîne de batch bien plus tôt qu’auparavant
- Que la chaîne de batch s’est quelque peu « fluidifié »
Reste à optimiser le flux…