Datacenter as a Computer : une plongée dans les datacenters des acteurs du cloud
Dans ce papier (de 2009), Luiz André Barroso and Urs Hölzle (entre autres) de Google Inc. présente une introduction aux “Warehouse-Scale Computers” (abrégé WSC); une introduction aux grands datacenters du l’industrie du Web.
Alors certes c’est assez loin de notre quotidien (à la fois en termes d’échelle mais également en termes de métier car on ne construit pas tous les jours un nouveau datacenter) mais ce papier nous aide à nous projeter dans ce qu’est un datacenter chez les acteurs du Cloud d’aujourd’hui. Une merveille qui présente très certainement ce que seront nos datacenters traditionnels à terme, les impacts que cela aura sur les architectures applicatives.
L’objectif ici n’est pas de reprendre l’exhaustivité de ce papier de 90 pages mais de vous faire part des éléments, à mon sens, les plus marquants et qui s’articule autour de plusieurs axes :
- Présentation des concepts généraux d’un datacenter, ses services, son organisation (Alimentation électrique, gestion de climatisation...)
- Un zoom particulier sur les serveurs qui composent un datacenter
- Une analyse très détaillée des enjeux énergétiques associés
- Une discussion (et des études de cas) autour des TCO
- Un zoom particulier sur les pannes et leurs origines
#1 - “Architectural Overview & DataCenter Basics”
Peut-être étiez-vous au courant mais les datacenters sont souvent classifiés en plusieurs types, offrant des niveaux de redondance (et donc au final de disponibilité) différents.
- Tier I et II. Un seul acheminement de l'électricité et de climatisation. Offre une disponibilité < 99,7%
- Tier III. Les circuits de distribution électrique et de climatisation sont redondés (Actif/Passif). Offre une disponibilité < 99,98%
- Tier IV. Le redondance est en actif/actif, la disponibilité grimpe à 99,995%
Un datacenter (et ceux décrits dans le papier) proposent également une offre de services
- Power. Alimenter le système de climatisation, les serveurs... Ce papier est un trés bon moyen de comprendre le circuit de l’énergie électrique au sein d’un datacenter (et notamment les concepts de Uninterruptable Power Supply - UPS ou Power Distribution Unit - PDU). Nous en reparlerons ultérieurement mais c’est l’un des axes d’optimisation les plus importants
- Storage. Stocker les données Plusieurs systèmes possibles : - du NAS. De mémoire, le papier ne s’attarde pas trop sur l’utilisation ou pas de SAN (Difficile donc de savoir s’ils en utilisent ou pas et si non, si cela est du à des coûts prohibitifs ou des fonctionnalités inadaptées à ces architectures distribuées) - du Distributed File System s’appuyant sur des disques locaux. Ainsi la résilience est gérée par le Distributed File System (et la réplication au niveau applicatif des fichiers) et non par l’infrastructure “hardware” sous-jacente. A titre d’exemple, c’est un axe trés fort des solutions “NoSQL” ou même “in-memory datagrid”. En termes de disques, ce sont plutôt des “desktop-class” que des “enterprise-grade” principalement à cause de la différence de prix. Ce n’est pas sans rappeler l’étude de Google sur les taux de pannes des disques durs.
- Network. Transférer la donnée Bien entendu, pour optimiser les coûts, différents types de switchs, réseaux sont utilisés suivant que l’on soit “à l’entrée du DC” ou bien à l’entrée d’un rack. Les réseaux type Ethernet sont privilégiés à de l’Infiniband par exemple principalement pour des raisons de compromis entre performance et coût.
Ce graphique donne quelques éléments de mesures sur des métriques classiques (Capacité de stockage, bande passante, latence). Ces métriques sont simplement agrégées du serveur (Local sur le graphe), au rack puis au datacenter (abrégé WSC dans la légende)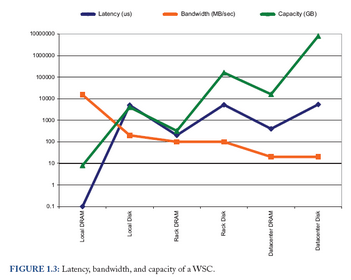
#2 - Hardware Building Blocks = Cost-efficient hardware
Cette étude propose une comparaison du ratio coût/performance de 2 types de serveurs (qui a été basé sur les Superdome (128 cores). Coût : 12 M€. Pour l’autre, le Proliant (4 cores). Coût : 75 k€. 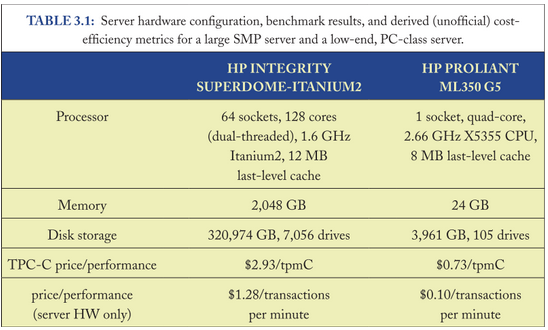
En somme, ce tableau compare le coût de la scalabilité horizontale et de la scalabilité verticale. Ainsi, la ligne “TPC-C price / performance” montre que le Proliant est 3 fois plus efficace (selon le ratio défini préalablement) que le Superdome. Ce ratio est encore plus important d’après la ligne “price/performance (server HW only)” qui retire de l’équation le coût du stockage et donc compare des “capacités de traitement”.
C’est un élément de comparaison qui omet un point : absorber le même “throughtput” avec les deux types d’infrastructure n’induit pas la même architecture. Là où le “Superdome” permettra de centraliser, l”option “Proliant” imposera de distribuer... Et distribuer imposera des communications entre process. Dans le cas du modèle centralisé, les process partagent la même mémoire et la communication entre process est de l’ordre de 100ns (la figure précédente 1.3 le montre). A l’inverse et dans le modèle distribué, les process devront communiquer sur LAN (avec un ordre de grandeur de 100µs). Cela a forcément un impact sur les performances globales, impact montré par ce graphe (lisez bien la légende qui définit l’axe des ordonnées) : 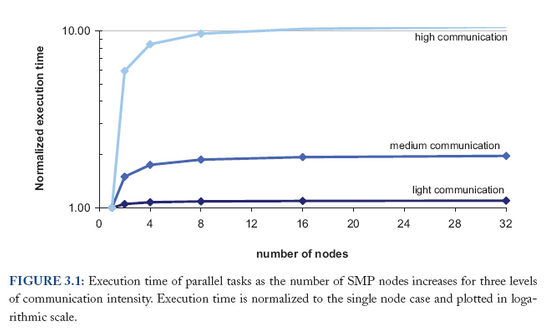
Ainsi, un unique processeur 128 cores (représentant le Superdome) peut être de l’ordre de 10 fois plus performant qu’un cluster de 32 machines 4 cores (représentant un cluster de Proliant) si la communication entre process est élevé. C’est beaucoup moins vrai si la communication entre process est faible. J’avoue qu’il me manque une quantification de “communication élevée” et “faible” notamment pour pouvoir le transposer au Gossip Protocol que l’on utilise souvent dans des stockages distribués.
Ce papier va plus loin et compare ensuite la performance d’un cluster de Superdome avec un cluster de Proliant (toujours en fonction du niveau de communication inter-process qui du coup est distribuée) et démontre qu’à trés grande échelle (> 1500 cores) l’option Superdome ou “high-end server” n’offre plus de réels avantages de performance par rapport à l’option Proliant (quelque soit le niveau de communication inter-process). Rajouter à cela le coût : l’option Superdome ou “high-end server” n’est réellement plus intéressante.
#3 - “Energy and Power Efficiency” : le réel challenge
L’énergie est un sujet d’actualité, notamment à une époque où l’on parle d’énergie renouvelable. Cela traduit deux choses. La première est qu’il y a un enjeu fort autour de l’optimisation de l’utilisation qui est faite de l’électricité dans les datacenters. La seconde, conséquence du point précédent, une volonté voire une nécessité d’optimiser les coûts.
Un indicateur de cette efficience est donc défini ainsi (et adresse des domaines distincts de l’ingénierie) :
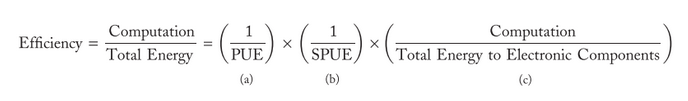
(a) PUE
James Hamilton en parle dans ce papier mais le PUE mesure l’efficacité de l’utilisation de l’énergie électrique (en quelque sorte, cela mesure la perte d’énergie entre l’électricité qui rentre dans le datacenter (ce qui est facturé au final) et l’énergie qui arrive effectivement au niveau des serveurs).
C’est donc une mesure de la qualité du bâtiment lui même et, en simplifiant un peu, la plupart des sources de surcoûts (et donc de dégradation du PUE) sont liées à l’énergie électrique consommée uniquement pour climatiser (entre 40% et 70% de l’énergie électrique). Il y a également des pertes d’énergie lors des conversions haut voltage (115kV) vers bas voltage (220V).
Ainsi, les meilleurs datacenters affichent aujourd’hui un PUE < 1.2 (la majorité étant vers 2 voire plus haut… Les axes d’amélioration sont alors doubles :
- améliorer l’efficience des transformateurs électriques types UPS (c’est assez loin de notre métier).
- limiter l’utilisation qui est faite de la climatisation (électrique). Cela peut passer par l’utilisation de refroidissements mécaniques (cooling tower) ou à eau mais aussi (et là on touche à un mythe) par des salles machines plus chaudes. Ainsi, on pourrait monter les températures jusqu’à 27°C sans voir une augmentation des taux de pannes (cette idée est également reprise dans cette étude de Google sur les pannes des disques durs)
(b) SPUE
Ce paramètre est finalement très proche du PUE mais au niveau d’une machine. SPUE pour Server PUE. L’idée est de mesurer l’énergie utile c’est à dire celle qui permet d’alimenter la carte mère, les disques, les CPU, RAM. On a ainsi une mesure de l’énergie perdue dans l’alimentation, le ventilateur etc...
La plupart des serveurs ont aujourd’hui des ratios entre 1,6 et 1,8 (autrement dit plus de 60% de perte) alors qu’à l’état de l’art, on devrait être à 1,2.
Ainsi PUE * SPUE donne une mesure de la perte d’énergie électrique. Un datacenter standard annonce un total de 3,2… Autrement dit pour chaque 1W utile, il faut injecter 2,2W supplémentaires…
(c) Measuring the efficiency of computing
On cherche à mesurer, sur l’énergie électrique qu’il reste pour alimenter carte mère, CPU, RAM, disques, la partie qui est effectivement transformée en travail : en somme la partie qui permet de répondre à des requêtes ou à exécuter des calculs… On mesure ainsi un “Performance to Power Ratio” (qui est forcément dépendant de l’architecture physique de la machine). James Hamilton dans ce papier en parlait déjà : l’objectif est d’optimiser le “work done by joule”.
Dans ce graphe la performance est définie comme le nombre de transactions par seconde.
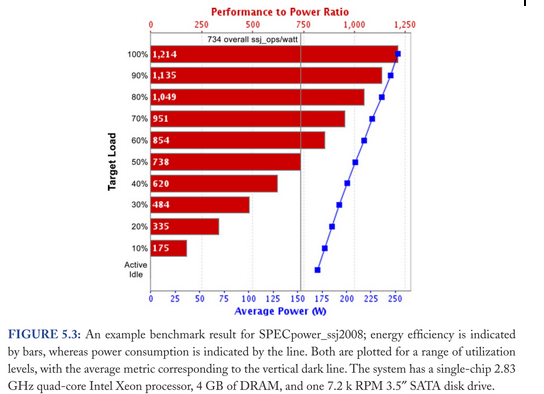
En bref, le ratio n’est pas linéaire. Un serveur qui fonctionne à 100% ne consomme que 30% de plus qu’un serveur en standby (Active idle). C’est la courbe bleue. De fait, le ratio (en rouge) tombe fortement et globalement un serveur qui fonctionne en dessous de 50% de charge “consomme plus qu’il ne travaille”…
Alors ce comportement pourrait être acceptable sauf que les serveurs passent la plupart de leur temps entre 10 et 50%… (je vous invite à aller voir page 55 l’étude qui l’explique). Dès lors le rêve serait une consommation proportionnelle à l’utilisation que l’on fait de la machine (Energy-Proportional Computing). En somme, si la machine est passive (idle), elle consommerait zéro Watt. On pourrait ainsi imaginer des serveurs proposant non pas une consommation linéaire en fonction de la charge mais des zones d’optimum. Typiquement, un optimum du ratio performance-to-power pour des charges entre 20 et 50%… exactement l’inverse de ce que l'on a aujourd’hui.
De façon plus proche, les prochains challenges autour de cette consommation énergétique touche au disque dur. Les CPUs ont beaucoup travaillé pour avoir une consommation proportionnelle à leur utilisation mais des composants comme la RAM ou le disque trés peu (page 59)
_Consommation des CPUs...
La consommation électrique d’un CPU est directement indexée sur sa puissance. Ainsi la consommation décroit en O(K²) lorsque la fréquence du CPU décroît de k.
De plus, pour un CPU donné, la consommation évolue en fonction de l’utilisation qui en est faite. Comme le montre ce schéma, ce n’est pas encore le cas de la RAM ou du disque 
Attention néanmoins au fait que ces choix de CPU auront un impact sur le code et demanderont des optimisations au niveau applicatif. Prenons par exemple un service qui met 1s de latence sur un CPU donné et dont la moitié de cette latence est passée dans le CPU. Si on utilise un CPU 3 fois plus lent, le temps de réponse passe à 2s… Il double…_
#4 - “Modeling Costs” : à un moment, il faut bien…
TCO, Capex, Opex… Autant de termes que l’on pourrait, de prime abord, considérer comme un sujet de financier ou de comptable mais qui, au final, sont bien des sujets d’architecture…
Cette section propose un modèle de TCO, des exemples de calculs mais surtout des éléments de métriques qui peuvent servir de base de comparaison avec d’autres solutions IaaS type AWS.
- Capex. Le Capex s’exprime en dollar per “critical watt”, autrement dit par Watt utile à l’équipement IT. Rappelez-vous du PUE et vous verrez qu’il faut plus de Watts que ce qu’on imagine… A ce jeu, un Datacenter coûte entre 10 et 15$ le “critical Watt” et est rentabilisé sur une période de 10 à 15 ans. En somme autour des $0,10/W par mois. A ce titre également, un serveur (alors bien entendu cela dépend du type de serveur, de sa consommation, de son prix et de sa période de rentabilité (autour de 4 ans) ) coûte $0,20/W par mois (pour un serveur de 4000$ amorti sur 4 ans).
 | Petit exercice de mathématiques<br><br>Sachant qu’un serveur (2,7GHz, 4G de RAM) est utilisé en moyenne à 30% dans le mois (et donc consomme 190W d’après le graphe 5.3) et permet de servir 10 requêtes / seconde, est-il préférable d’aller sur EC2 ?<br><br>La requête ramène une liste qui fait 30ko et le stockage n’est pas considéré. |
- Opex. L’Opex est plus complexe à modéliser car il prend en compte le personnel pour exploiter mais aussi la sécurité, l’emplacement géographique, le coût des licences, l’administration.
#5 - Dealing with failures and repairs
Définir le niveau de fiabilité d’un système est fondamentalement un compromis entre le coût d’une panne (avec de l’évident comme par exemple le CA perdu mais du plus subtile comme le coût de réparation…) et l’investissement nécessaire à sa prévention.
A ce titre, la stratégie traditionnelle est basée sur l’utilisation de matériel fiable. C’est finalement souvent lié au fait que les applicatifs n’ont pas été architecturés pour être résilients à des pannes matérielles. C’est finalement plus simple. C’est également étrange car VonNeumann a démontré en 1956 que tous les systèmes fiables, ont été construits sur des composants non fiables. Ainsi, certains systèmes ont été conçus pour accepter ces pannes, pour fonctionner avec des composants non fiables : des “low-end servers”. Dès lors, ces systèmes plus complexes présentent des avantages de coûts d’infrastructure (nous en avons parlé précédemment) mais aussi des avantages opérationnels (plus de fenêtre de maintenance, de déploiement…)
Principaux types de pannes et indicateurs
Les fautes peuvent être catégorisées :
- Corrupted. la donnée est perdue, impossible à regénérer
- Unreachable. Le service est down, impossible à accéder
- Degrader. Le service est disponible mais dans un mode dégradé
- Masked. Des fautes ont lieu mais elles sont transparentes pour l'utilisateur final (ce qui ne veut pas dire qu'elles doivent être transparentes pour l'IT en général...)
Au delà de la catégorisation, cela permet d’offrir différents indicateurs : - Le yield dans le cas de Brewer. Il s’agit du pourcentage de requêtes réalisées. - L’apdex dont parle le site apdex.org. Il s’agit du pourcentage de requêtes ayant le temps de réponse attendu.
Supervision de la performance
Il existe quelques outils (certainement trés “cutting-edge” ou de niveau académique) qui visent à superviser, diagnostiquer les problématiques de performance sur des plateformes distribuées.
| Outillage | pros/cons | |
| Monitoring "black box" | - WAP5 - sherlock systems | pros : - fonctionne sans aucune connaissance de l’application<br><br>cons : - perte de précision. Les données sont analysées par stats |
| Instrumentation des applications/middleware | - Pip - Magpie - X-trace | exactement l’inverse de l’autre :o) |
Il sera intéressant de positionner tout cela par rapport au marché commercial (peut-être des solutions type Dynatrace).
Principales causes de pannes
Différentes études (dont certaines datent de 1990) ont démontré (et Google confirme)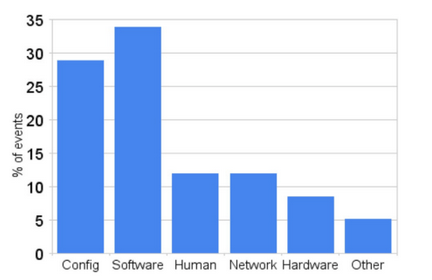
que les principales pannes sont liées à des problèmes de configuration, de software ou même humain. Ce qu’à également montré cette étude issue de Recovery Oriented Computer project de Berkeley, c’est que le taux d’erreurs liées au system management n’a fait qu’augmenter (et je ne pense pas que cette courbe se soit inversée depuis 1993, nos systèmes étant encore plus complexes, distribués…) 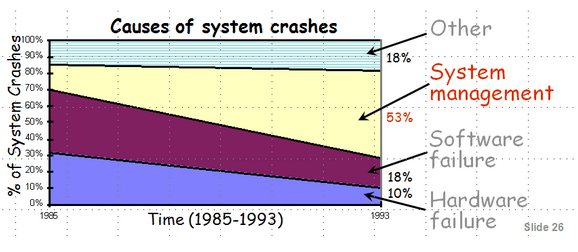
Le lecteur averti aura noté que c’est un des axe d’amélioration dont parlent beaucoup les protagonistes de DevOps.
_Recovery Oriented Computing aborde un point rapport à la disponibilité. La disponibilité se mesure comme uptime = (MTBF – MTTR)/MTBF MTBF = Mean Time Between Failure MTTR = Mean Time To Repair
Une stratégie pour augmenter la disponibilité est donc soit d’augmenter le MTBF, soit de diminuer le MTTR. Le MTTR inclus plusieurs choses : le diagnostic, le fix, etc. Il peut également être amélioré en travaillant sur les temps de redémarrage des serveurs. Un ESB mettant 2h30 à démarrer (i.e. à déployer l’ensemble des services) n’a pas un bon temps de redémarrage). Et mécaniquement il a une disponibilité inférieure à un ESB mettant 6 minutes à démarrer.
Google présente un graphe intéressant : l’axe des x représente le temps de downtime - tout type d’arrêt confondu (donc avec maintenance..) et l’axe des y, le pourcentage de redémarrages qui atteint ce downtime . 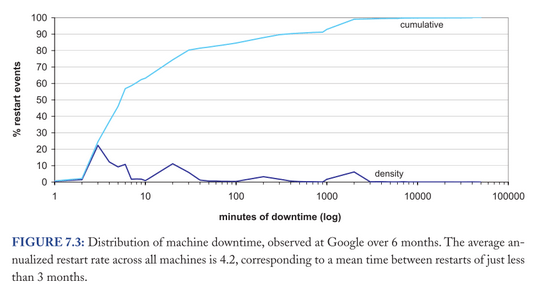
Un graphe intéressant à créer qui démontre que 55% des redémarrages (prévu ou non) durent moins de 6 minutes_
Et de conclure...
Difficile de conclure sur une telle densité d’information...Il est acquis que ces papiers permettent de satisfaire notre soif de curiosité. Mais il faut également y voir un moyen de comprendre les problématiques de ceux qui font les datacenters. Je ne parle pas spécialement des sysadmins dont les problématiques nous sont familières mais de ceux qui font les buildings, achètent les machines, gèrent la climatisation, etc. Il est vrai que cette échelle est rarement rencontrée. Il n’en reste pas moins vrai que l’enjeu énergétique est aujourd’hui réel dans nos datacenters et que ces datacenters sont trés certainement les images de ce que seront nos datacenters demain. N’oublions pas également que ces études sont faites par ceux qui “font le Cloud”. Ce sont donc les datacenters dans lesquels nos applications “cloudifiées” (ie. dont l’architecture a été adaptée) devront fonctionner : - le hardware choisit s’oriente vers du commodity server-class machines en partie car le ratio cout / performance est plus intéressant. - la résilience se doit d’être gérée au niveau applicatif (sur la base du hardware choisi précédemment) et doit permettre de garantir le fonctionnement du service. C’est une des grandes leçons de noSQL : gérer la résilience au niveau applicatif (réplication JVM) plutôt qu’au niveau infrastructure (réplication SAN) - l’écart de performance entre la RAM et le disque est réel (même avec des SSD). Dans le même temps, les capacités de RAM aujourd’hui sont proches du Tera. Enorme ! Il est fort probable que Big Data nous emmène vers ce débat.
Maintenant, repensons à tout cela ; les enjeux électriques, low-end server, le nombre de pannes associées à des erreurs humaines… Remettons-nous en mémoire les messages, les technologies ou pratiques autour de noSQL, DevOps… Reprenons nos architectures, nos systèmes d’information “traditionnels”… Ça change 2 ou 3 trucs non ? :o)