Dans le billet CQRS l’architecture aux deux visages (partie 1), nous vous avions présenté les bases d’une architecture CQRS. En effet une application combine des fonctionnalités de consultation d’une part (Read) et traitement métier d’autre part (Write). CQRS propose d’aborder ces deux groupes de fonctionnalités comme deux contextes d’utilisation distincts afin d’appliquer des stratégies de design adaptées à leurs besoins spécifiques.
Dans cet article, nous allons essayer d’apporter des réponses à la question laissée en suspens : comment construire une application satisfaisant aux exigences liées au contexte de restitution d’information d'une part, et au contexte de traitement de l’information d'autre part, tout en conservant un modèle explicite respectant les principes DDD évoqués dans l’article Domain Driven Design, des armes pour affronter la complexité ("Domain-driven design is not a technology or a methodology. It is a way of thinking and a set of priorities, aimed at accelerating software projects that have to deal with complicated domains").
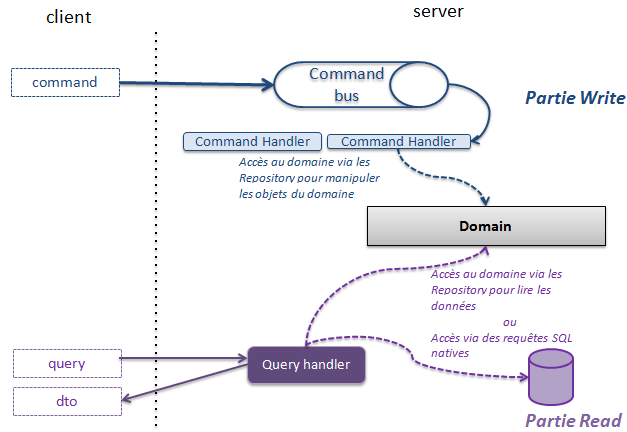
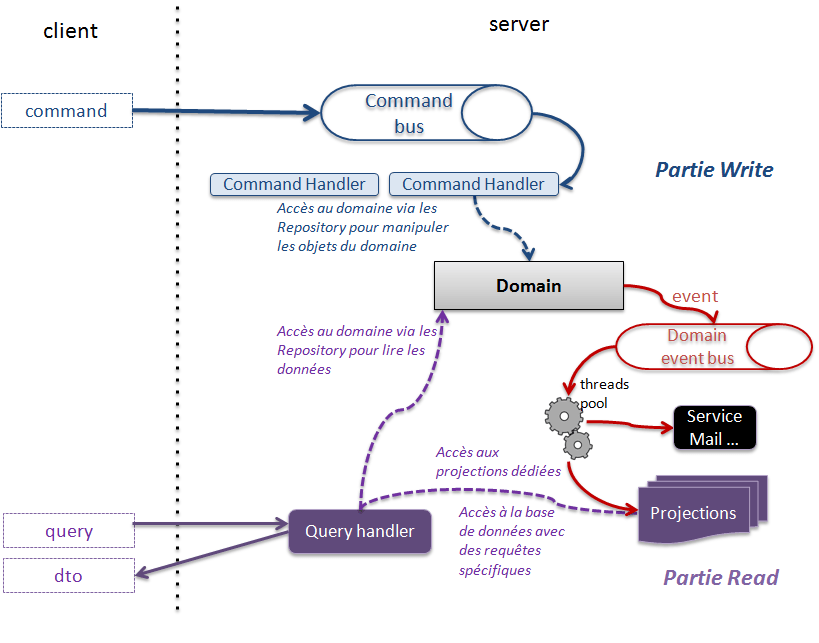
Pour illustrer notre propos, nous allons nous reposer sur un cas d’usage rencontré dans bon nombre d’applications : avoir une recherche simple et performante. Mais avant de commencer, voici un schéma qui rappelle l'architecture décrite dans l'article CQRS l’architecture aux deux visages (partie 1).
La suite de cet article montre comment faire évoluer l’architecture du système mis en place en mettant en oeuvre deux concepts pour satisfaire ces exigences : les évènements au coeur du domaine (domain events) et l’asynchrone.
Un retour sur Dr Read et Mr Write...
Avant même de parler de domain event et d’asynchrone, attardons-nous quelque peu sur ce que l’architecture précédemment décrite autorise. Du fait de la séparation des opérations Command et Query, on peut envisager sereinement d’utiliser des stratégies de persistance différentes pour la partie Write et pour la partie Read. Pourquoi ? Pour profiter des avantages des différentes technologies de persistance et faciliter la gestion des contraintes du système. On pourrait, pour la partie Write, choisir une solution de persistence de type document afin de s’épargner un mapping fastidieux ; et pour la partie Read, choisir une solution type RDBMS pour faciliter la recherche par critère. Bien entendu, ces choix ne sont pas systématiques, ils sont à faire en fonction des contraintes du système (besoin de partitionnement, scalabilité…).
Très bien, mais du coup comment mettre à jour mes projections partie Read sans pour autant impacter mon domaine ? Tout simplement, grâce à un évènement qui indique que dans la partie Write, quelque chose a changé et que ce quelque chose doit être pris en compte dans la partie Read.
Domain events… please help !
De très bons articles détaillent ce que sont les domain events. Pour aller au plus simple, nous allons nous contenter de la définition “un évènement est quelque chose qui s’est produit dans le passé”.
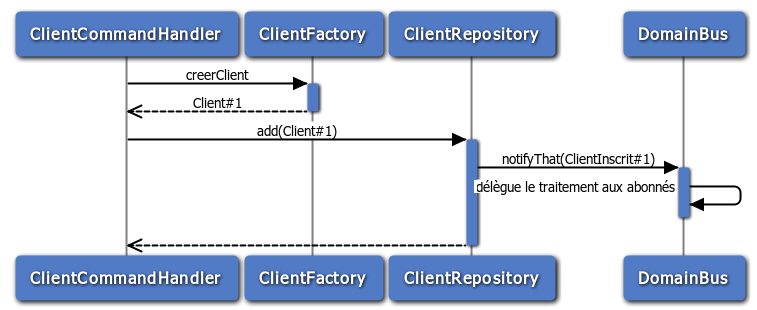
Dans le cas de l’inscription d'un nouveau client dans mon système, l’évènement produit serait ClientInscrit, il porte les données relatives à l’entité créée.
De plus, cet évènement serait publié sur un bus auquel plusieurs objets peuvent êtres abonnés pour initier une action liée à cet évènement.
Le schéma ci-après illustre ce qui se passe lors de l'inscription d'un nouveau client.
Dans ce contexte, notre système pourrait avoir un objet lié à l’évènement ClientInscrit dont la seule responsabilité serait d’ “indexer” la nouvelle référence client pour la recherche, et de mettre à jour une projection adaptée pour l’affichage de la liste des clients.
Les évènements circulant sur ce bus peuvent également être utilisés pour des problématiques beaucoup plus proches du domaine, par exemple : notifier un agrégat de la modification de l’adresse du client afin de déclencher un processus métier particulier.
Quels bénéfices tirons-nous de l’introduction des domain events
- Une meilleur appréhension du comportement du domaine : les évènements du domaine permettent de décrire le comportement de l’application et de mettre en avant la dynamique du modèle.
- Une meilleur isolation des responsabilités : les gestionnaires d’évènements du domaine se conforment davantage au principe de responsabilité unique (Single Responsability Principle). Ils favorisent également la communication entre les différents bounded context.
Bilan
Avec les domain events, le code gagne en expressivité et est mieux découpé. Cela permet d’exploiter au mieux le paradigme de programmation orienté objet. De plus, cela facilite la mise en oeuvre de projections dédiées pour la partie Read à partir d'évènement issus de la partie Write sans pour autant polluer le code métier.
Mise à jour asynchrone du Read au service de l’utilisateur
Wikipédia indique que, “en informatique un programme est une séquence d'instructions qui spécifie étape par étape les opérations à effectuer pour obtenir un résultat”. C’est vrai, mais quelque peu réducteur. En effet si un ensemble d’instructions s’exécute en séquence, l'informatique moderne permet à minima de simuler des exécutions parallèles. Ces unités de traitement peuvent communiquer via des messages. L'émission d'un message avec éventuellement un mécanisme de callback pour traiter un message de retour sans suspension du traitement en cours peut être considéré comme une communication de type asynchrone. Cela signifie que l’on sait exploiter des systèmes informatiques de manière synchrone et asynchrone.
Et là, vous vous dites wahhhh… quelle découverte !!! Mais tant pis, je continue…
C’est une bonne nouvelle car les utilisateurs ont besoin d’interagir avec le système de manière synchrone et asynchrone.
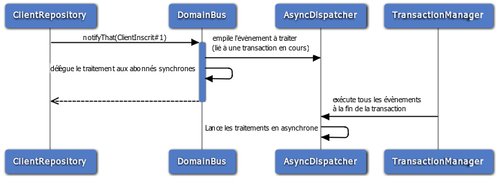
Pour poursuivre notre exemple, lorsque j’ajoute un nouveau client dans mon système, en tant qu’utilisateur, j’ai besoin d’un feedback immédiat m’indiquant que l’information que je viens de saisir a bien été prise en compte (et qu’elle ne sera pas perdue). En revanche, je suis prêt à accepter que le système de recherche de client ne prenne en compte l’ajout de ce client que plus tard (quelques (milli)secondes plus tard). Cela signifie que, pour maximiser la réactivité de mon système, j’accepte de rendre cohérente la partie partie Read "plus tard".
Afin de ne pas pénaliser l’utilisateur, le traitement de mise à jour de la partie Read provoqué par l’évènement ClientInscrit sera effectué en dehors de la transaction utilisateur. Aussi il est nécessaire que le déclenchement du traitement de ces évènements ne soit réalisé qu’après le succès du traitement synchrone (incluant la transaction en base de données) comme le montre le schéma ci après.
Quels sont les bénéfices à traiter certains domain events en asynchrone ?
- La facilité de mise en oeuvre d’un système offrant une bonne performance ressentie : les évènements du domaine sont exploités pour déclencher des traitements synchrones et/ou asynchrones sans pour autant polluer le code métier, le traitement important qui impacte ce que l’utilisateur souhaite faire est traité en synchrone, le reste en asynchrone.
- La possibilité de distribuer les traitements asynchrones : il faut néanmoins faire attention à utiliser des évènements sur le bon niveau d’objet du domaine (agrégats) et disposer de toutes les informations nécessaires au traitement de l’évènement.
Bilan
Si la gestion asynchrone des domain events apporte beaucoup sur la performance ressentie de l’utilisateur et la distribution du traitement de l’information, certains points restent néanmoins plus complexes à gérer, notamment le traitement de l’échec des traitements asynchrones. On peut choisir de les logger uniquement ou de prévoir dans le système un mécanisme de compensation des traitements en échec (notification de l’utilisateur via mail ou directement dans son navigateur…)
Conclusion
Cet article a permis de montrer comment exploiter le concept de domain event dans une architecture CQRS. L’architecture présentée a évolué comme le montre le schéma ci dessous.
Dans cette architecture, certaines commandes entraînent la publication d’évènements sur le domain event bus, certains de ces évènements sont traités pour mettre à jour des projections précalculées qui sont à leur tour exploitées par les query handler. Dans notre cas, le but étant d’améliorer les performances ressenties et éviter des requêtes multi-critère multi-jointure…
Sans nous étendre plus longuement sur un sujet qui mériterait un article à part entière et qui fait déjà l’objet de nombreux billets sur internet, nous orientons l’architecture vers un système capable de gérer la partie Write en ACID (Atomicity, Consistency, Isolation, Durability) et la partie Read en BASE (Basically Available Soft-State services with Eventual Consistency) dans le but d’offrir plus de confort à l’utilisateur.
Bien entendu DDD et CQRS ne peuvent se résumer à ces quelques articles de blogs. Nous n’avons pas abordé toutes les problématiques, ni toutes les possibilités offertes par ce type d’architecture comme l’event sourcing ("Event Sourcing : stop thinking of your datas as a stock but rather as a list of events…") évoqué dans l’article event sourcing & nosql. Néanmoins la mise en oeuvre d’une architecture CQRS sans event sourcing ne devrait plus vous faire peur, car elle n’apporte pas de complexité technique démesurée, et permet d’avoir des applications plus ouverte à l’évolution de vos besoins.