CQRS, l'architecture aux deux visages (partie 1)
Dans un article précédent, nous avons vu comment l’approche DDD, via la définition et l’utilisation d’un Ubiquitous Language et d’un véritable modèle du domaine, peut faciliter la communication entre acteurs projet, aider à l’écriture d’un code plus expressif (et donc plus maintenable), et capable d’adresser la complexité - et les changements - du métier.
Aujourd’hui, nous allons essayer de répondre à certaines questions laissées en suspens par notre première approche de DDD. Comment éviter de multiplier les couches de mapping, sans valeur ajoutée, à différents niveaux de notre architecture ? Comment aller plus loin dans le respect des principes objet tels que l’encapsulation ? Comment faciliter la réalisation d’IHM orientées tâches et activités, présentant des informations vraiment pertinentes pour l’utilisateur ? L’utilisation d’un modèle objet riche est-elle synonyme de dégradation des performances ?

Le pattern CQRS (Command Query Responsibility Segregation) repose sur un principe simple : la séparation, au sein d’une application, des composants de traitement métier de l’information (“command” / écriture) et de restitution de l’information (“query” / lecture). Ce seul principe fournit un cadre d’architecture extrêmement intéressant pour le développement d’applications, en levant un certain nombre de contraintes et en faisant apparaître de nouvelles opportunités.
Comme pour DDD, nous ne faisons pas ici une présentation détaillée de CQRS (se référer plutôt aux excellents papiers disponibles sur dddcqrs.com). Nous allons plutôt identifier les opportunités ouvertes par CQRS qui nous semblent pouvoir apporter le plus de valeur à la majorité des applications que nous développons, et voir comment certains aspects plus “avancés” peuvent être mis en place de manière incrémentale et “tirée” par le besoin.
Dr Read et Mr Write, des gens bien différents
“Qui sait lire et écrire a quatre yeux (ou s’appelle Chuck Norris)”. Cette libre adaptation d’un proverbe albanais résume assez bien la vision qui sous-tend le pattern CQRS. En effet, ses instigateurs partent du constat suivant : dans une application, les besoins fonctionnels et non-fonctionnels peuvent être très différents selon que l’on s’intéresse à ses composantes de lecture ou d’écriture.
En effet, nous avons globalement les besoins suivants : - En traitement / écriture : besoins transactionnels, garantie de cohérence (consistency) des données, de normalisation - En consultation : besoins de dénormalisation, de scalabilité
Evidemment, ces “écarts” de besoins varient selon les contextes. Voici quelques éléments illustrant ces différences…
Des IHM orientées tâches, pour guider l’utilisateur
Dans le billet J'ai mal à mon application, ça se soigne ?, nous mentionnons les IHM orientées tâches (Task-based UI) comme pattern d’interface utilisateur pouvant améliorer l’efficience - et la satisfaction - des utilisateurs. L’idée est d’organiser les écrans autour des cas d’utilisation de l’application. En particulier :
- Les différentes actions disponibles sont présentées clairement et nommées explicitement (ex : un bouton “S’inscrire en tant que consommateur” au lieu d’un laconique “OK”) : l’intention est sans équivoque
- Lorsque je veux accomplir une tâche, seules les informations utiles à sa réalisation sont présentées
- Lorsque j’ai besoin d’une information, je veux qu’elle me soit fournie simplement par l’application, sans avoir à croiser moi-même les données fournies par différents écrans
Ces deux derniers points impliquent des besoins d’aggrégation, de croisements, de filtrage de données. D’où un besoin de dénormalisation des données lorsqu’elles sont destinées à la consultation.
Un Domain Model, pour régner sur le Royaume
A contrario, lorsque l'utilisateur demande à exécuter une action (un traitement métier) sur le système, la problématique n’est pas la même. On va manipuler des ensembles de données plus réduits, en vérifiant que les actions demandées respectent les règles (invariants) du système. La complexité métier se trouve de ce côté-ci, et l'on peut - par exemple - utiliser un modèle du domaine pour mieux la gérer, comme le préconise DDD. On aura alors un modèle construit autour d’entités, de Value Objects, d’associations ; ainsi que la notion d’Aggregates pour définir les limites des unités de cohérence. Ici, on privilégie donc la normalisation et l’intégrité des données.
Des volumes de sollicitations différents
Il est fréquent que les fonctionnalités de consultation soient bien plus sollicitées que celles de “traitement”. A titre d’exemple, nous avons mesuré sur une application sur laquelle nous sommes intervenus que 85 % des “actions” invoquées concernaient de la recherche ou de la consultation de données, et que seulement 15% avaient pour but de lancer des “traitements” sur le système.
Au regard de ces différences, pourquoi se contraindre à utiliser le même modèle d’architecture pour ces deux types de besoin ? Le résultat sera invariablement une architecture insatisfaisante pour l’un, l’autre, voire les deux !
Séparons-les !
CQRS propose donc de séparer une architecture applicative en deux parties :
- le Read Side (ou “Query”, “Reporting”) pour la restitution des informations
- le Write Side (ou “Command”, “Business”) pour l’exécution d’actions entraînant le traitement et persistence d’informations
Chacune de ces parties peut être vue comme un Bounded Context au sens DDD, et donc disposer d’un modèle et d’un style architectural adaptés à leur problématique.
Voyons comment nous pouvons opérer cette séparation par étapes successives, en observant à chaque fois les gains obtenus et les coûts associés.
Read Services versus Write Services
L’application la plus élémentaire de CQRS consiste à séparer les services applicatifs de lecture et d’écriture sur le système.
Reprenons notre exemple d'application de vente de légumes en ligne. Notre ConsommateurService sera éclaté de la manière suivante :
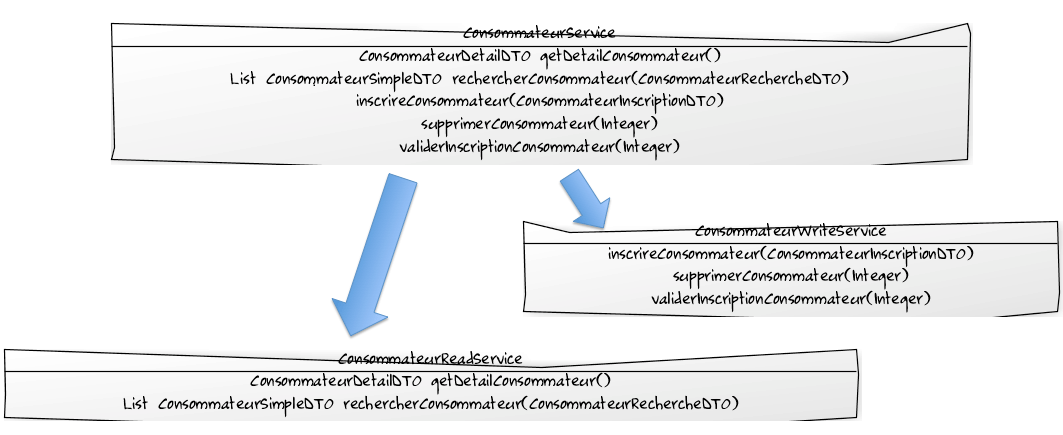
Les méthodes du ConsommateurReadService vont charger un AggregateRoot à partir d’un repository, calculer éventuellement certaines valeurs, puis constituer des DTOs et les renvoyer à l’IHM. Ces DTOs sont “taillés” pour les besoins IHM : typiquement, un champ du DTO correspond à un champ de saisie ou libellé de l’écran. Ils ne comportent pas d’objets du modèle du domaine, mais uniquement des valeurs “simples” (types primitifs, structures de données de base). Ils peuvent par contre contenir des identifiants d’entités, afin que l’IHM puisse les transmettre lors de prochains appels vers la couche de services applicatifs.

{kind=link}
{kind=link}
Le ConsommateurWriteService, pour sa part, dispose de méthodes qui prennent en paramètre des identifiants d’entités ainsi que des valeurs simples (éventuellement un DTO). Ces méthodes ne renvoient rien (void), mais peuvent générer des exceptions.
Quels bénéfices tirons-nous de cette séparation ?
- Suppression du risque d’effets de bord : les méthodes des services Read ne modifient pas l’état du système. Le développeur peut donc les utiliser sans craindre de provoquer des comportements anormaux sur le reste du système.
- Allègement des classes de service : tout simplement, nous avons ici un axe pour découper les classes de service, qui ont parfois tendance à prendre de l’embonpoint. En séparant ces classes en deux selon qu’elles réalisent des opérations de lecture ou d’écriture, on a une manière naturelle et intuitive d’organiser le code de nos services.
- Exposition facilitée au reste du monde : l’API de notre application est rendue réellement indépendante de son implémentation et de sa dynamique interne, grâce à l’utilisation de DTOs et de types “simples”. De plus, la séparation en Read et Write facilite l’exposition des services ; par exemple, via l’implémentation d’un émissaire JSON sur HTTP : les méthodes du Read sont particulièrement adaptées - en termes techniques et sémantiques - pour être exposées en HTTP GET (safe, idempotentes), et le Write en POST.
Mais…
- Couche de mapping fastidieuse : l’utilisation de DTOs comme modèle d’échange pour les services du Read oblige à effectuer du mapping entre les objets du domaine et les DTOs conçus pour l’IHM.
Bilan
Séparer les service applicatifs de Read et de Write, c’est simplement une autre manière de structurer son code. Néanmoins, cette approche demande un certain effort d’adaptation, et induit un léger overhead d'écriture de code. A contrario, les bénéfices peuvent être nombreux, en particulier au niveau de la maintenance du code mais également en vue de l’intégration avec le reste du monde : le simple fait de poser quelques règles élémentaires dans la conception de l’API de notre application permet d’envisager une exposition de services facilitée. Reste le problème du mapping : nous verrons un peu plus bas comment l’attaquer.
Le pattern Commande
Si on voulait faire branché, on dirait que le pattern Commande, c’est un peu du “Feature As An Object” (ou plus précisément du “Action As An Object”).
On a l’habitude de définir une Commande comme un appel de méthode encapsulé dans un objet. Une commande représente une action destinée à être exécutée. Elle porte un nom explicite, formulé à l’impératif ; ses champs contiennent les valeurs des différents paramètres de l’action. Selon la version du pattern, elle peut également contenir une méthode execute() qui va réaliser le traitement associé ; dans d’autres cas, l’exécution de cette action est décorrélée de la description de l’intention, et se trouve implémentée par des CommandHandlers. C’est cette dernière variante que nous décrivons ici.
On peut repartir de notre ConsommateurWriteService, et extraire chacune de ces méthodes pour en faire un couple Commande / CommandHandler.
Les Commandes :


Les Handlers :

Quels bénéfices tirons-nous de ce changement ?
- Meilleure isolation des responsabilités : en isolant chacune des fonctionnalités d’action fournies par l’API de notre application, on obtient des classes qui se conforment d’avantage au principe d’unique responsabilité (Single Responsibility Principle) et dont l’organisation est extrêmement simple. De plus, au niveau d’une application, a-t-on vraiment à gagner à introduire la notion de service ? Ici, une action = une commande, tout simplement.
- Explicitation de l’intention utilisateur : une commande porte un nom unique, formulé à l’impératif. C’est une manière d’expliciter qu’il s’agit de quelque chose que l’utilisateur demande à faire. Ici, pas de méthodes rendues obscures par une signature à rallonge ou par différentes surcharges dont ne sait plus bien pourquoi elles existent… Une commande représente une intention claire et sans équivoque, qui s’accorde particulièrement bien avec une IHM orientée tâches.
- Unité de code plus fine que le service : on a la possibilité de créer autant de CommandHandlers qu’il y a de commandes, et donc de réduire à nouveau la taille de classes que nous écrivons. De plus, deux développeurs travaillant sur deux fonctionnalités différentes auront donc moins de risques de devoir effectuer des merges manuels entre leurs codes.
- Asynchronisme envisageable : l’asynchronisme est un mécanismes pouvant nous aider à réaliser des applications plus réactives, plus fluides vis-à-vis des actions utilisateur. En transformant notre API d’actions en un ensemble de Commandes, on ouvre la voie aux traitements asynchrones : nos Commandes peuvent être placées sur une queue et traitées par les CommandHandlers dès que les ressources nécessaires à leur exécution sont disponibles. Les actions ne sont donc plus bloquantes. Un autre usage intéressant à envisager concerne l’implémentation d’un mode déconnecté : les actions que je réalise en local (et traitées par des CommandHandler locaux) devront bien, à un moment, être réalisées sur le serveur (par les CommandHandler distants). Il me suffit alors d’envoyer les commandes vers le serveur dès que la connexion est récupérée.
Mais…
- Plus de lignes de code : là où vous aviez une ligne pour la déclaration d’une méthode (avec, disons, 3 paramètres) dans une interface, vous vous retrouvez avec une classe de Commande (sorte d’équivalent de l’interface) comportant 3 champs. Et “l’envoi” des commandes par le code client est un peu plus verbeux qu’une invocation de méthode directe. Cependant, ce code est simple à tester.
Bilan
En passant au pattern Commande, notre code gagne encore en expressivité, et est mieux découpé. Le traitement asynchrone de certaines actions demandées par l’utilisateur pourra être mis en oeuvre si le besoin apparaît un jour, sans coût de refactoring prohibitif.
Thin Read Layer
Reste la question du mapping des objets du domaine vers les DTOs qui remonteront jusqu'à la couche de présentation. Finalement, dans le contexte du Read, ne peut-on pas tout bonnement se passer de l'utilisation des objets du domaine ?
Lorsque l’intention est simplement de remonter de l’information, nous n’avons pas besoin des comportements portés par le modèle du domaine. De plus, notre besoin est bien de produire des DTOs prévus pour des cas d’utilisation bien précis, pour lesquels on sait exactement quelles données doivent être remontées. Le problème des stratégies de chargement (lazy loading…) ne se pose donc pas non plus.
Bref, l’utilisation d’objets du domaine et d’un mécanisme tel que l’ORM peuvent paraître ici surdimensionnés ! La solution la plus simple est peut-être d’utiliser ce bon vieux SQL pour aller récupérer les informations qui nous intéressent, et les injecter directement dans nos DTOs.

Bénéfices
- Suppression de l’effort (sans valeur ajoutée) du mapping domaine / DTO : plus besoin de faire appel à des Factories ou autres Assemblers dont le rôle est d’assurer la transformation des objets du domaine en DTO. Ceux-ci sont remplis directement à partir du jeux de données extrait de la base.
- Meilleur contrôle sur les requêtes de lecture en base : les requêtes peuvent être écrites en SQL (ou autre) natif, ce qui permet d’avoir un contrôle total sur leur plan d'exécution et sur la manière de mapper les données.
Mais…
- Perte de certaines facilités : un ORM peut fournir des mécanismes d'optimisation, par exemple un cache de requêtes. En l'absence d'ORM, ils devront donc être implémentés autrement. Noter que s'il est possible de se passer d'ORM pour le Read, ça n'est pas non plus une obligation…
- Coût du refactoring : l'utilisation de deux modèles (read & write) accédant à la même couche de données induit des coûts de refactoring légèrement supérieurs (ex: si l'on renomme une colonne, il faudra mettre à jour le mapping des objets du Write et les requêtes SQL du Read).
Bilan
A l’issue de cette itération, nous avons donc séparé les parties Read et Write d’un système sur les couches de services applicatifs et d’accès aux données.
La partie “Read” résultante, dénommée “Thin Read Layer” dans le monde CQRS, se résume à l’exécution de requêtes SQL et au remplissage de DTOs… On ne peut plus simple !
Conclusion
Nous avons vu que l’on peut envisager la restitution d’informations et l’invocation de commandes comme deux concepts suffisamment structurants pour décider qu’ils représentent des contextes bien différents.
Concrètement, l’implémentation proposée dans cet article permet d'approcher simplement cette nouvelle structuration. Elle supprime les besoins de mapping de DTOs et d'exposition de getters dans les objets du domaine pour les seuls besoins de l'IHM. De plus, dans le prolongement de ce que nous avions entamé avec DDD, nous avons explicité les concepts et l'intention dans différentes parties du système (IHM orientées tâches, commandes).
Néanmoins, le modèle de stockage reste le même pour le Read et le Write. Or, ce modèle normalisé peut s'avérer sous-optimal pour le Read, qui représente l’essentiel des sollicitations du système.
Pour aller plus loin, dans un prochain article, nous verrons comment lever cette limite en profitant des évènements du domaine pour créer un modèle de données spécialisé, optimisé pour la lecture, sans impacter notre modèle spécialisé pour le traitement des actions métier.