Construire ses parsers ANTLR avec Maven - Partie 1/3 - ANTLR
Cet article en 3 volets présente comment intégrer la construction et le test de parsers ANTLR avec Maven. La première partie est consacrée à une présentation rapide d'ANTLR.
Lorsque vous avez besoin de développer un langage maison pour votre projet Java, avec une grammaire capable de le reconnaître, une valeur sûre est ANTLR (ANother Tool for Language Recognition, http://antlr.org), de même que le couple lex + yacc (ou la version GNU flex + bison) est la référence pour le langage C. Pour citer deux exemples, le parser HQL de Hibernate et celui de Groovy sont écrits avec ANTLR. On notera au passage que l'auteur d'ANTLR, en photo sur la page d'accueil du site, a conservé la métaphore animale en passant du monde des bovidés (Bos grunniens et Bison bison) à celui des cervidés (Cervus elaphus) !^[<a id="rev-pnote-201-1" href="#pnote-201-1">1</a>]^
Après une première partie de présentation d'ANTLR, cet article vous proposera de mettre en œuvre l'exécution automatique et fiable d'ANTLR au sein d'un build Maven. Une troisième partie montrera comment on peut écrire et lancer, par le même biais, des tests unitaires sur une grammaire.
A propos d'ANTLR
Malgré des différences importantes dans l'implémentation des langages, ANTLR, comme lex + yacc, est un préprocesseur qui prend en entrée un fichier descriptif de votre grammaire (appelons-le Demo.g) et pond du code source : en l'occurrence deux classes, une pour le lexer (DemoLexer) et une pour le parser (DemoParser). Le code source est par défaut émis en Java, mais ANTLR est aussi capable de générer du C#, du C++, du Ruby, du Brainfuck, ... Dans cet article nous ciblons une plate-forme Java.
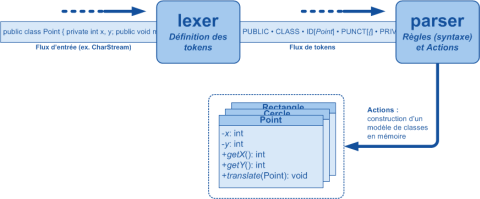
Le lexer (le terme exact est analyseur lexical) découpe le flux de caractères en entrée en tokens, ou éléments syntaxiques de base : une constante numérique, un caractère de ponctuation, un identifiant de variable, ...
Quant au parser, il consomme ce flux de tokens pour reconnaître les constructions syntaxiques du langage (ex. une déclaration de méthode) et agir en conséquence. Ses actions peuvent être l'interprétation immédiate du texte fourni en entrée (ex. exécution de commandes), ou bien la construction d'un arbre syntaxique abstrait (AST) en mémoire^[<a id="rev-pnote-201-2" href="#pnote-201-2">2</a>]^.
Voici un schéma récapitulatif qui illustrerait un fragment de grammaire pour le langage Java :
Une première exécution
Téléchargez la dernière version d'ANTLR sur le site : http://www.java2s.com/Code/JarDownload/antlr/antlr-runtime-3.1.1.jar.zip, et placez le JAR dans un répertoire de votre disque.
Ensuite copiez-coller le code suivant dans un fichier texte que vous nommerez Demo.g, dans le même répertoire :
grammar Demo;
// Les mots-clefs de notre langage
tokens {
PRINT = 'print';
}
// Code Java ajouté en tête du fichier source du lexer
@lexer::header
{
package com.octo.testantlr;
}
// Code Java ajouté en tête du fichier source du parser
@parser::header
{
package com.octo.testantlr;
}
// Règles du parser (les noms commencent par une minuscule)
program
: statement*
;
statement
: PRINT INTEGER ';' // Ex. : print 123;
| PRINT VARIABLE ';' // Ex. : print toto;
| VARIABLE '=' INTEGER ';' // Ex. : toto = 123;
;
// Règles du lexer (les noms commencent par une majuscule ; la convention est de tout mettre en majuscules)
// Nom de variable
VARIABLE
: LETTER (LETTER | DIGIT)*
;
// Constante entière
INTEGER
: DIGIT+
;
// Commentaire -> ignoré
COMMENT
: '//' (~ NL)* NL? { skip(); }
;
// Sauts de ligne (ignorés via la règle WS)
NL
: 'n' | 'r'
;
// Espaces -> ignorés
WS
: (' ' | 't' | NL) { skip(); }
;
fragment LETTER
: 'A'..'Z' | 'a'..'z' | '_'
;
fragment DIGIT
: '0'..'9'
;
Puis, pour générer le lexer et le parser en ligne de commande, depuis le répertoire où est stocké Demo.g :
java -cp antlr-3.1.1.jar org.antlr.Tool -o . Demo.g
Vous aurez alors, dans le répertoire courant (du fait de l'option "-o ."), deux fichiers DemoLexer.java et DemoParser.java -- qui ne sont pas destinés à être lisibles par un être humain ! Il y a même un troisième fichier, Demo.tokens, qui contient la liste et les valeurs de tous les tokens, explicites et implicites, définis par la grammaire. Ce fichier est utilisé lorsqu'on veut partager des tokens entre plusieurs grammaires ; nous n'en avons pas besoin ici.
Une fois un lexer et un parser instanciés dans un projet (opérations non détaillées ici), la méthode DemoParser.program(), dont le nom est celui de la règle "point d'entrée" du parser, reconnaîtra notre mini-langage (aucune action n'étant associée aux règles du parser, en l'état celui-ci ne fait que valider la syntaxe du langage sans effets de bord).
Intégration au build Maven d'un vrai projet
Ce sera l'objet de la partie suivante. Pour l'instant, il faudra vous contenter de copier les fichiers générés dans le répertoire de votre projet, en faisant attention au nom du package (cf. sections @parser::header et @lexer::header de Demo.g), et de les regénérer à la main à chaque fois que vous modifierez la grammaire.
N'hésitez pas aussi à jeter un œil à l'IDE dédié à ANTLR, ANTLRWorks : http://tunnelvisionlabs.com/products/demo/antlrworks. Il vous permet de tester les règles individuelles en mode interactif, d'obtenir une représentation graphique de l'automate du parser, etc. Un plugin Eclipse est aussi disponible ici : http://antlrv3ide.sourceforge.net/, mais je ne l'ai pas encore essayé !
Notes
[1] antler = bois de cerf, en anglais
[2] Pour plus de détails sur les AST, une fonctionnalité très puissante et qui devient vite indispensable, je vous renvoie à la documentation d’ANTLR. Les AST permettent, au lieu d’interpréter au fil de l’eau le flux d’entrée, d’en construire une représentation complète en mémoire pour pouvoir ensuite la parcourir dans n’importe quel sens, la retravailler, l’optimiser, ... Comme cas d'usage, penser par exemple à un compilateur ou au moteur d’optimisation de requêtes d'un SGBD.