Consistent Hashing ou l’art de distribuer les données

Une belle calligraphie se caractérise entre autre par l’équilibre général du caractère et de la composition. Une expertise qui demande une vie de travail à en croire certaines maitres Zen… A l’instar de la calligraphie, distribuer la donnée entre différentes instances semble également relever de la maitrise de l’équilibre… Si l’on regarde des solutions comme memcached ou Amazon Dynamo, l’idée fondamentale est de pouvoir rajouter ou enlever, pour répondre à des évolutions de charge, dynamiquement (c'est-à-dire sans arrêt de services) des instances.
Cette problématique consiste à répondre aux enjeux suivants :
- La plus simple : comment répartir les objets uniformément entre les différentes instances ?
- La plus drôle : comment faire pour que cette répartition ne soit pas trop sensible à l’ajout ou à la suppression dynamique d’instances ?
Expérience #1 ou comment perdre l’intégralité de votre cache
Le comportement par défaut consiste à rendre chaque instance responsable d’un groupe de données, d’une sous-partie de l’ensemble. Par défaut l’allocation ou plus exactement la localisation d’un objet à un serveur se fait suivant l’algorithme suivant :
server = serverlist[hash(key)%serverlist.length];
Au-delà de la formule mathématique, chaque donnée se voit affectée à une instance particulière. Ainsi avec cet algorithme, la localisation de la donnée à une instance particulière prend en compte le nombre total d’instances. Le client utilise cette même fonction de cache pour déterminer quelle instance de cache il est nécessaire d’interroger pour récupérer la donnée. Autrement dit, si une ou plusieurs instances sont rajoutées ou supprimées, l’ensemble des hashs est modifié et indique des instances qui n’ont pas la donnée. La quasi totalité de votre cache est perdu. Incrédule ? Un exercice intéressant (et que je n’ai pas inventé) permet de tester différentes manières de répartir les objets sur les différentes instances de memcached – test effectué sur un poste simple (un portable 2Go de RAM, 2,5GHz de CPU) :
- Démarrer 10 instances memcached
- Insérer un million d’objets (des chaînes de caractère dans mon exemple) Lire ce même million d’objets et s’assurer qu’aucun élément n’est manquant
- Démarrer une nouvelle et 11° instance et relire ce même million d’objets
Avec l’algorithme de répartition standard, on obtient une distribution parfaitement uniforme
instance curr_items 127.0.0.1:11215 100000 127.0.0.1:11218 100000 127.0.0.1:11213 100000 127.0.0.1:11220 100000 127.0.0.1:11216 100000 127.0.0.1:11214 100000 127.0.0.1:11217 100000 127.0.0.1:11212 100000 127.0.0.1:11211 100000 127.0.0.1:11219 100000
Le million d’objets est inséré en un peu plus de 30 secondes. Suite au démarrage de la 11° instance, et à la lecture des objets (qui devrait donc utiliser le cache), on se rend compte que 909079 objets parmi le million inséré ne sont pas récupérés du cache : 90% du contenu du cache est gêné par l’ajout de cette nouvelle instance. Autant de requêtes qui solliciteront non plus votre cache mais votre base de données. L’ajout de la 11° instance a bien rendu caduque la répartition qui avait été faite au préalable et ainsi anéanti toutes les tentatives d’optimisation que vous aviez réalisées. Et pour ceux (et celles) qui se disent que l’on ne rajoute pas tous les jours des instances, le principe reste valable si une des instances tombe ; et ca, c’est nettement plus probable… Est-ce feature ? Pas vraiment et si on regarde la formule mathématique plus haut, l’on se rend compte que puisque le nombre d’instance disponible a changé, le modulo à également changé et que du coup le serveur nouvellement désigné comme « possédant la donnée » ne la possède en vérité pas (encore).
Expérience #2 ou l’équilibre presque parfait…
Pour lever cette limitation, un autre algorithme de partitionnement des objets est souvent utilisé : l’algorithme de Consistent Hashing
Consistent hashing is a scheme that provides hash table functionality in a way that the addition or removal of one slot does not significantly change the mapping of keys to slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped. By using consistent hashing, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots.
Ces articles expliquent à merveille l’algorithme de Consistent Hashing. En substance, il s’appuie sue les deux principes suivants :
- Données et instances du cache se voient attribuer un numéro qui est le résultat d’une fonction de hash simple mais commune.
- Chaque instance du cache se voit responsable des données qui ont un hash compris entre celui de l’instance responsable et l’instance précédente
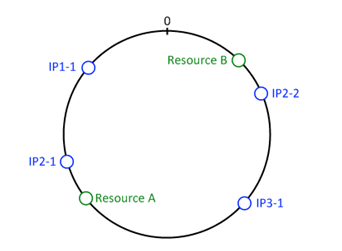
Ainsi, IP2-1 est responsable des ressources ayant un hash compris entre celui de IP3-1 et IP2-1 (donc la ResourceA), etc…Dès lors, si vous ajouter ou supprimer une instance (par exemple IP2-2), seules les données qui étaient sur la zone comprise entre « 0 IP1-1 » et « IP2-2 » seront perturbées…leur hash n’a pas changé mais elles ne seront plus servi par IP2-2 mais par IP3-1, la machine suivante sur le cercle.
Côté Java (et oui j’avais envie de coder un peu…), il existe l’API cliente spymemcached qui permet de s’interfacer avec des instances memcached et fournit en prime une implémentation du Consistent Hashing. Le code suivant insert différentes données dans 10 instances memcached (sur les ports 11211 à 11221)
List< inetsocketaddress > memCachedServers = new ArrayList>< inetsocketaddress >();
for (int port = 11211; port < 11221; port++) {
memCachedServers.add(new InetSocketAddress("localhost", port));
}
try {
ConnectionFactory connectionFactory = new DefaultConnectionFactory(
DefaultConnectionFactory.DEFAULT_OP_QUEUE_LEN,
DefaultConnectionFactory.DEFAULT_READ_BUFFER_SIZE,
HashAlgorithm.KETAMA_HASH) {
public NodeLocator createLocator(List< MemcachedNode > list) {
KetamaNodeLocator locator = new KetamaNodeLocator(list,
HashAlgorithm.KETAMA_HASH);
return locator;
}
};
MemcachedClient client = new MemcachedClient(connectionFactory,memCachedServers);
client.set(key, 3600, value);
Object obj = client.get(key);
En répétant la même expérience que précédemment, on note que la répartition initiale des objets sur les différentes instances est légèrement différente et de prime abord moins uniforme
Instance curr_items 127.0.0.1:11215 104667 127.0.0.1:11218 85582 127.0.0.1:11213 91505 127.0.0.1:11220 101675 127.0.0.1:11216 99267 127.0.0.1:11214 109958 127.0.0.1:11217 97039 127.0.0.1:11212 103810 127.0.0.1:11211 100676 127.0.0.1:11219 105821
En revanche, suite au démarrage de la 11° instance et à la lecture du million d’objets insérés, seule 88138 instances manquent. Autrement dit, cet algorithme permet de limiter la perturbation du cache à moins de 10% !
Le consistent hashing permet donc de répartir des données en assurant un maximum de résilience. On retrouve son utilisation dans des solutions de cache type memcached, des caches de ressources Web ou également des stockages distribués type Dynamo. Autrement dit, à chaque fois que l’on commande un article sur Amazon…