Concaténation, Compression, Cache
Quand on cherche à optimiser les performances de son site web, il y a trois éléments essentiels à faire avant toute chose. Trois méthodes très simples à mettre en place et qui apportent un retour direct et flagrant sur la vitesse de chargement.
Ces trois méthodes sont la concaténation, la compression et le cache. Nous avons déjà abordés ceux-ci lors d'une présentation aux HumanTalks de septembre 2014, mais nous allons les détailler dans la suite de cet article.
1. Concaténation
Le principe de la concaténation est de regrouper plusieurs fichiers de même type en un seul, afin de se retrouver avec moins de fichiers finaux à télécharger. Les fichiers qui profitent le plus de ce système sont les fichiers CSS et JavaScript.
La nature même du téléchargement d'assets fait que notre navigateur doit payer certains coûts, en millisecondes, à chaque nouvel élément téléchargé. Ces coûts sont de diverses natures :
TCP Slow Start
TCP, le protocole de connexion qu'utilise HTTP, possède un mécanisme de slow-start qui lui permet de calculer la vitesse optimale de transmission de l'information. Pour parvenir à ce résultat, il doit effectuer plusieurs aller-retours entre le client et le serveur, en envoyant de plus en plus en plus de données, pour calculer la vitesse maximale possible d'émission/réception.
Si on envoie une multitude de petits fichiers, la transmission n'a jamais le temps d'atteindre sa vitesse optimale et doit recommencer ses aller-retours pour le prochain fichier. En groupant les fichiers en un fichier de plus grande taille, le coût de calcul n'est payé qu'une seule fois et le reste du fichier peut se télécharger à la vitesse maximum.
À noter que maintenir les connexions à votre serveur en Keep-Alive permet de réutiliser une connexion d'un asset vers le suivant et donc de ne payer le coût de calcul qu'une fois. Malheureusement, activer le Keep-Alive sur un serveur Apache risque aussi de limiter le nombre de connexions parallèle que votre serveur peut maintenir.
SSL
De la même manière, si votre serveur utilise une connexion sécurisée, il y a un échange de clés entre le client et le serveur qui s'effectue pour vérifier que les deux sont bien qui ils annoncent être. Ici encore, le coût de cet échange est payé sur chaque asset téléchargé. Mettre les fichiers en commun permet donc de ne payer le coût de cet échange qu'une seule fois.
Connexions parallèles
Finalement, il y a une dernière limite, purement du coté du navigateur cette fois-ci : le nombre de connexions parallèles. La norme HTTP indique qu'un navigateur devrait ouvrir un maximum de 2 connexions parallèles vers un même serveur. Techniquement, les navigateurs récents ont augmenté cette limite à une valeur entre 8 et 12 car 2 était beaucoup trop restrictif.
Cela signifie c'est que si vous demandez à votre page web de télécharger 5 feuilles de style, 5 scripts et 10 images, le navigateur ne va lancer le téléchargement que des 12 premiers éléments. Il commencera le téléchargement du 13e uniquement une fois qu'un des 12 premiers sera arrivé, et ainsi de suite. Ici encore, la concaténation vous permet de laisser plus de canaux disponibles pour télécharger les autres assets de votre page.
Les fichiers CSS et Javascript se concatènent très bien. Il suffit simplement de créer un fichier final qui contient le contenu mis bout-à-bout de tous les fichiers initiaux. Votre processus de build devrait pouvoir s'en charger sans problème, mais une solution simple peut s'écrire en quelques lignes :
cat ./src/*.css > ./dist/styles.css
cat ./js/*.js > ./dist/scripts.js
À noter que la concaténation d'images (CSS Sprites) est aussi possible, mais nous ne l'aborderons pas dans cet article.
2. Compression
Maintenant que nous avons réduit le nombre de fichiers, notre deuxième tâche va être de rendre ces fichiers plus légers, afin qu'ils se téléchargent plus rapidement.
Pour cela, il existe une formule magique formidable nommée Gzip qui permet de réduire de 66% en moyenne le poids des assets textuels.
La bonne nouvelle c'est que la majorité des assets que nous utilisons dans la création d'un site web sont du texte. Les briques principales comme le HTML, le CSS et le Javascript bien sur, mais aussi les formats classiques de retour de votre API : XML et JSON. Et beaucoup d'autres formats qui ne sont en fait que du XML déguisé : flux RSS, webfonts, SVG.
Gzip, et c'est assez rare pour le souligner, est parfaitement interprété par tous les serveurs et tous les navigateurs du marché (jusque IE5.5, c'est dire). Il n'y a donc aucune raison de ne pas l'utiliser.
Si un navigateur supporte le Gzip, il enverra un header Accept-Encoding: gzipau serveur. Si le serveur décèle ce header dans la requête, il compressera le fichier à la volée avant de le retourner au client, en y ajoutant le header Content-Encoding: gzip, et le client le décompressera à la réception.
L'avantage est donc d'avoir un fichier de taille réduite qui transite sur le réseau, avec en contrepartie le serveur et le client qui s'occupent respectivement de la compression/décompression. Sur n'importe quelle machine issue des 10 dernières années, l'overhead de la compression/décompression en gzip est absolument négligeable. Par contre, le fait d'avoir un fichier bien plus léger qui transite sur le réseau permet des gains très importants.
Les librairies de compression Gzip sont disponibles sur tous les serveurs du marché, il suffit généralement simplement de les activer en leur indiquant les types de fichiers qui doivent être compressées. Vous trouverez ci-dessous quelques exemples sur les serveurs les plus connus :
Apache
<IfModule mod_deflate.c>
<IfModule mod_filter.c>
AddOutputFilterByType DEFLATE "application/javascript" "application/json" \
"text/css" "text/html" "text/xml" [...]
</IfModule>
</IfModule>
Lighttpd
server.modules += ( "mod_compress" )
compress.filetype = ("application/javascript", "application/json", \
"text/css", "text/html", "text/xml", [...] )
Nginx
gzip on;
gzip_comp_level 6;
gzip_types application/javascript application/json text/css text/html text/xml
[...];
S'il y a bien une optimisation de performance qui nécessite peu de travail à mettre en place et qui améliore grandement les performances de chargement, c'est bien le Gzip. Cela ne nécessite aucun changement sur les fichiers servis, uniquement une activation de config sur le serveur.
Minification
Pour aller plus loin, vous pouvez aussi investir sur la minification de vos assets. HTML, CSS et Javascript sont encore une fois les meilleurs candidats pour la minification.
La minification est un procédé qui va ré-écrire le code de vos assets dans une version qui utilise moins de caractères, et qui donc pèsera moins lourd sur le réseau. D'une manière générale cela va surtout supprimer les commentaires et les sauts de ligne, mais des minificateurs plus spécialisés pourront renommer les variables de vos Javascript en des valeurs plus courtes, regrouper vos sélecteurs CSS ou supprimer les attributs redondants de vos pages HTML.
L'ajout d'un processus de minification est plus complexe que l'activation du Gzip, et les gains sont aussi moins importants. C'est pourquoi nous vous conseillons de toujours commencer par la compression Gzip.
3. Cache
À présent que nous avons réussi à limiter le nombre de fichiers et à faire baisser leur poids, la prochaine étape est de les télécharger le moins souvent possible.
L'idée principale ici est qu'il est inutile de faire télécharger à votre visiteur un contenu qu'il a déjà téléchargé et possède donc en local sur son poste.
Nous allons commencer par expliquer comment fonctionne le cache HTTP car c'est un domaine qui est généralement mal compris des développeurs. Il y a en fait deux principes fondamentaux à comprendre dans le cache HTTP : la fraicheur, et la validation.
Fraicheur
On peut voir la fraicheur d'un asset comme une date limite de consommation. Lorsque l'on télécharge un élément depuis le serveur, celui-ci nous l'envoie accompagné d'un header indiquant jusqu'à quelle date cet élément est encore frais.
Si jamais le client à besoin à nouveau du même élément, il commence par vérifier la fraicheur de celui qu'il a en cache. S'il est encore frais, il ne fait pas de requête au serveur, et utilise directement celui qu'il a sur son disque. On ne peut pas faire plus rapide, car il n'y a alors absolument aucune connexion réseau impliquée.
Par contre, si jamais la date de fraicheur est dépassée, alors le navigateur va lancer une nouvelle requête au serveur pour récupérer la nouvelle version.
En HTTP 1.0, le serveur retourne un header Expires avec la date limite de fraicheur. Par exemple : Expires: Thu, 04 May 2014 20:00:00 GMT. Dans cet exemple, si jamais le navigateur demande à nouveau le même asset avant le 4 Mai 2014 à 20h, alors il le lira depuis son cache, sinon il interrogera le serveur.
Cette notation a un défaut majeur dans le fait que les dates sont fixées de manière absolue. Cela signifie que le cache de tous les clients perdra sa fraicheur en même temps. Et vous aurez donc potentiellement tous les clients qui feront une nouvelle requête vers votre serveur en même temps pour se mettre à jour, ce qui peut générer un très fort pic de charge à cet instant.
Pour limiter cela et donner plus de flexibilité dans la gestion de la fraicheur, en HTTP 1.1, un nouveau header à été introduit : Cache-Control. Celui-ci accepte plusieurs arguments qui permettent de gérer plus finement la manière de mettre en cache, et celui qui nous intéresse ici est max-age qui permet de définir une durée relative de fraicheur, en secondes.
Votre serveur peut donc répondre Cache-Control: max-age=3600 pour indiquer que l'asset est encore frais pendant 1h (3600 secondes). En faisant ainsi vous pouvez espacer les appels sur une plus longue période.
Validation
La deuxième composante du cache est la validation. Imaginons que notre asset ait terminé sa période de fraicheur, nous allons donc récupérer une nouvelle version de celui-ci sur le serveur. Mais il est possible que l'asset n'ait pas réellement changé sur le serveur depuis la dernière fois. Il serait alors inutile de retélécharger quelque chose que nous avons déjà dans notre cache.
Le principe de validation permet au serveur de gérer cela. Soit l'asset du client est identique à l'asset du serveur, dans ce cas le client peut garder sa version locale. Soit les deux sont différents et dans ce cas le client doit mettre à jour son cache avec la version distante.
Lorsque le client a récupéré l'asset pour la première fois, le serveur lui a répondu avec un header Last-Modified, par exemple Last-Modified: Mon, 04 May 2014 02:28:12 GMT. La prochaine fois que le client fera une requête pour récupérer cet asset, il renverra la date dans son header If-Modified-Since, par exemple If-Modified-Since: Mon, 04 May 2014 02:28:12 GMT.
Le serveur compare alors la date envoyée et celle qu'il possède de son coté. Si les deux correspondent, alors il renverra un 304 Not Modified pour indiquer au client que le contenu n'a pas changé. Celui-ci continuera alors d'utiliser sa version locale. Ainsi, on évite de transmettre du contenu inutile sur le réseau.
Par contre si le serveur voit que le fichier qu'il possède est plus récent que la date envoyée, il répondra avec un 200 OK et le nouveau contenu. Ainsi, le client utilise désormais la dernière version.
En faisant ainsi, on évite donc de télécharger un contenu qu'on possède déjà.
Dans les deux cas, le serveur renvoie de nouvelles informations de fraicheur.
Comme pour la fraicheur, il existe deux couples de headers pour communiquer des informations de validation au serveur. En plus de Last-Modified / If-Modified-Since qui utilisent une date de modification, il est possible d'utiliser des ETags.
Un ETag est un hash qui identifie de manière unique chaque fichier. Si le fichier change, alors son ETag change aussi. Par exemple, le serveur retourne au client lors du premier appel un header ETag: "3e86-410-3596fbbc", et lorsque le client fait à nouveau appel à la même ressource, il envoie un header If-None-Match : "3e86-410-3596fbbc". Le serveur va comparer les deux ETags et retourner un 304 Not Modified s'ils sont identiques ou un 200 OK avec le nouveau contenu s'ils sont différents.
Last-Modified et ETag possèdent des comportements très similaires, mais nous vous conseillons d'utiliser Last-Modified en priorité.
En effet, la spec HTTP indique que si un serveur retourne un Last-Modified et un ETag, alors le navigateur doit prendre en priorité le Last-Modified. De plus, la majorité des serveurs génèrent l'ETag à partir de l'inode du fichier, de manière à ce que celui-ci soit modifié au moindre changement.
Malheureusement, ceci pose des soucis pour peu que vous ayez des serveurs redondés derrière un load-balancer où chaque serveur possède son propre filesystem et donc ses propres inodes. Deux fichiers identiques, sur deux serveurs différents auront des inodes différents et par conséquent des ETag différents. Votre système de validation ne fonctionnera plus dès lors que votre client sera redirigé vers un autre frontal.
À noter que ce problème n'apparait pas sous nginx, qui ne prends pas en compte l'inode dans la génération de son ETag. Sous Apache, l'option FileEtag MTime Size permet de le désactiver, ainsi que etag.use-inode = "disable" sous lighttpd.
Récapitulatif
À la lumière de ces explications, nous pouvons donc retracer le parcours classique du téléchargement d'un asset mis en cache. 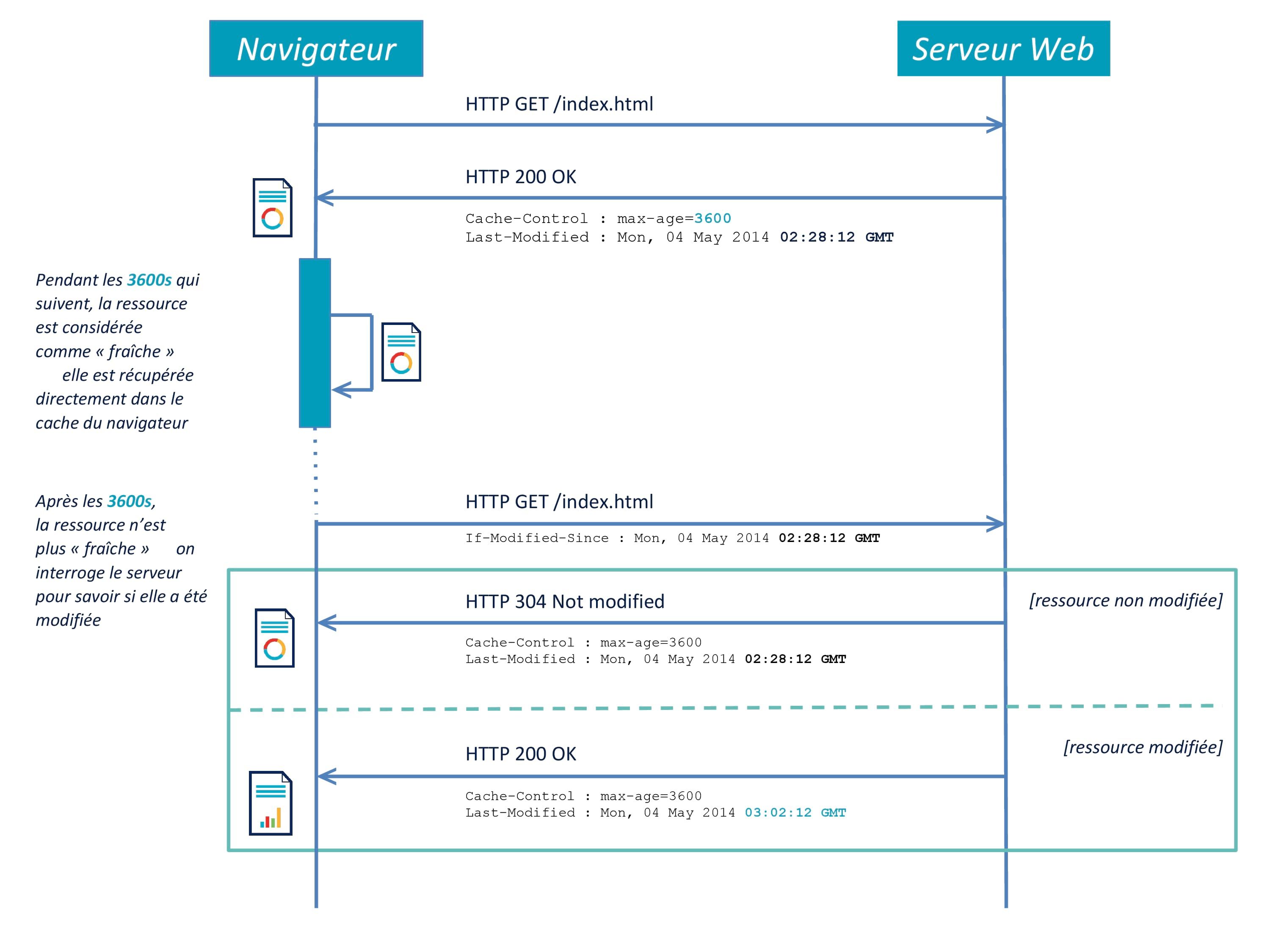
- Le client effectue une première requête pour récupérer un asset. Il récupère son
Cache-Control: max-agepour la fraicheur et sonLast-Modifiedpour la validation. - S'il demande à nouveau le même asset alors que celui-ci est encore frais, il le prends directement depuis son disque local.
- S'il le demande au dela de sa date de fraicheur, il fait un appel au serveur en envoyant son
If-Modified-Since. - Si le fichier sur le serveur possède la même date de modification que celle envoyée, il retourne un
304 Not Modified. - Si le fichier sur le serveur a été modifié, il retourne un
200 OKavec le nouveau contenu. - Dans tous les cas, le serveur retourne un
Cache-Controlet unLast-Modified.
Invalidation du cache
Mais le cache est un animal capricieux, et nous savons tous que :
Il y a deux choses complexes en informatique : invalider le cache et nommer les choses.
Et effectivement, invalider le cache de nos clients quand nous avons besoin de faire une mise à jour est extrêmement difficile. C'est en fait tellement difficile que nous n'allons pas le faire du tout.
Comme le navigateur met en cache chaque URL, si nous souhaitons modifier un contenu, il nous suffit de modifier son URL. Et les URL, c'est quelque chose que nous avons en quantité illimitée. Il nous suffit de modifier le nom d'un fichier pour générer une nouvelle URL. On peut ajouter un numero de version, un timestamp ou un hash à notre nom de fichier original pour lui générer une nouvelle URL.
Par exemple : style-c9b5fd6520f5ab77dd823b1b2c81ff9c461b1374.css au lieu de style.css.
En mettant un cache très long sur ces assets (1 an est le maximum officiel de la spec), c'est comme si on les gardait en cache indéfiniment. Il nous suffit juste de mettre un cache plus court sur le fichier qui les référence (généralement le fichier HTML).
Ainsi, si on pousse en production une modification sur une feuille de style ou dans un script, il nous suffit de modifier les références à ces fichiers dans nos sources HTML pour que les clients téléchargent les nouveaux contenus. Le cache sur les fichiers HTML est beaucoup plus court, de manière à ce que les changements introduits par notre mise en production soient rapidement répércutées sur nos clients.
Les anciens contenus seront encore en cache chez nos clients mais cela n'a pas d'importance, nous ne les requêterons plus jamais et les éléments non-utilisés du cache des clients se vident régulièrement.
La technique est en fait très proche des Etag vus précédement à la différence qu'ici nous sommes maîtres de la génération du nom unique de fichier et du moment où nous souhaitons invalider le cache de nos clients.
Au final, nous utilisons un mélange de ces deux techniques pour gérer un cache optimal.
Les éléments dont l'URL est significative, comme les pages HTML ou les retours d'une API définiront une fraicheur faible (de quelques minutes à quelques heures, en fonction de la fréquence moyenne de mise à jour). Ceci permet de s'assurer que le client aura rapidement la nouvelle version quand celle-ci est déployée, tout en limitant la charge sur le serveur et la quantité d'information transitant sur le réseau.
Pour les éléments dont l'URL n'est pas significative, comme les feuilles de styles, les scripts, les polices de caractère ou les images, on utilisera une fraicheur maximum d'un an. Ceci permettra au client de garder indéfiniment la ressource dans son cache sans avoir besoin d'interroger à nouveau le serveur. On générera par contre une URL différente en fonction d'un hash du contenu à chaque fois que le contenu vient à changer. On prendra bien garde à modifier les références à ces fichiers dans les pages HTML.
Conclusion
Nous avons donc vu comment trois points très simples permettent de diminuer grandement le nombre de total de fichiers à télécharger, les rendre plus légers, et les télécharger moins souvent.
La concaténation automatique des fichiers doit être intégrée dans votre processus de build, afin de garder un environnement de développement clair. La compression en gzip ne nécessite que quelques modifications sur vos serveurs. La mise en place d'une stratégie de cache optimale par contre nécessite à la fois des modifications sur le processus de build et sur la configuration des serveurs.
Toutes ces modifications sont relativement peu couteuses à mettre en place et ne dépendent aucunement ni de la technologie utilisée pour le front-end, ni de celle utilisée pour le back-end. Elles peuvent être mise en place quelle que soit votre stack technique. Il n'y a donc plus aucune raison pour ne pas les déployer dès aujourd'hui.