Comptoir sur les patterns MLOPs dans le cloud
Le comptoir nous a été présenté par Baptiste Courbe, consultant senior Octo spécialisé dans la création, l'industrialisation, et le maintien en condition opérationnelle de projets de data science et de recherche opérationnelle. Au cours de ses différentes missions, il a été amené à travailler dans ce cadre sur plusieurs cloud providers. Sa présentation visait à synthétiser et clarifier les différentes options et bonnes pratiques que l’on peut mettre en place d’un point de vue MLOps chez ces cloud providers à travers différents patterns.
Qu’est-ce que le MLOps ?
Commençons par regarder comment les différents cloud providers se proposent de définir le MLOps :
”Le MLOps est un ensemble de processus standardisés et de capacités technologiques permettant de construire, de déployer et d'opérationnaliser des systèmes de ML de manière rapide et fiable.”
AWS
“Le MLOps est un processus itératif et répétitif qui permet de faire évoluer les modèles d’IA au fil du temps.”
Azure
“Le MLOps est basé sur les principes et pratiques qui augmentent l’efficacité des workflows. Par exemple l'intégration, la livraison et le déploiement continus.”
Comparaison entre DevOps et MLOps
Avec l’arrivée du ML et des composantes DS une transition s’opère vers le MLOps. Deux nouvelles composantes interviennent : Les modèles et les données. Le MLOps partage le même but que DevOps tout en prenant en considération ces deux facteurs supplémentaires. On recherche donc à créer de la valeur le plus rapidement possible lorsque le code évolue, mais également lors d’évolutions de notre modèle et de nos données.
Pourquoi s'intéresser ici au MLOps dans le cloud ?
- La complexité évolue : Par le passé, la complexité résidait dans la création des modèles par manque de librairies et d'outils. Aujourd’hui, nous avons à disposition des librairies, telle que Scikit-learn, nous permettant de sélectionner et d'entraîner des modèles en quelques lignes de code. Mieux, il est désormais possible d'utiliser des modèles pré entraînés de manière extrêmement simple voir par des appels API, pratique qui se développe notamment avec l’arrivée des LLMs.
- Les environnements cloud évoluent très rapidement : Ils sont très flexibles et facilitent de nombreuses étapes de création, mise en production et maintien en conditions opérationnelles de nos modèles. Mais ils proposent un grand nombre de services parmi lesquels il n’est pas toujours évident de se retrouver.
Nous chercherons ici à vous donner des éléments pour vous aider à identifier les capacités dont vous avez besoin sur vos projets en termes de fonctionnalités et de bonnes pratiques. Donc à vous aider à vous poser les bonnes questions afin de choisir l'architecture en conséquence.
Illustration par des exemples
Pour permettre de plus facilement nous projeter, imaginons que nous sommes coach MLOps dans une entreprise de fabrication de bonbons. Nous présenterons ici trois exemples de projets fictifs et développerons les différentes approches MLOps pertinentes associées à chaque cas d’usage. Nous mettrons en avant les questions à se poser pour prendre les bonnes décisions d’archi en fonction du cas d’usage.
En tant que Coach MLOps, 3 équipes vont faire appel à vos conseils sur leur projet respectif :
- Le responsable de la production souhaite faire une maintenance prédictive à trois semaines sur l’ensemble des machines de la chaîne de production.
- L’équipe achat souhaiterait prévoir des stocks de manière quotidienne afin d'acheter la matière première nécessaire
- Le responsable du packaging veut mettre en place un modèle de reconnaissance d’image dans le but de trier les bonbons de manière automatique sur une chaîne de production
Les différentes équipes ont connaissance de la variété de bonnes pratiques existantes autour du MLOps:
- Historisation des modèles
- Validation des modèles
- Analyse automatique du drift
- Monitoring des performances du modèle
- Réentrainement du modèle
- Collecte des métriques d’utilisation
- …
Notre rôle va être d’éclairer ces équipes sur les pratiques qu’elles vont devoir réellement mettre en place sur leurs projets.
Qu’est-ce qui est pertinent et nécessaire et au contraire qu’est-ce qui est optionnel, voire dispensable ?
# Projet 1 : Maintenance prédictive
Ces trois derniers mois, la chaîne de production a été arrêtée deux fois et la production a dû être mise en pause plus d’une dizaine d’heures. Les équipes sont unanimes, ces pannes auraient pu être prévenues. Cependant, la routine rigoureuse des équipes de maintenance ne leur aurait pas permis de détecter ces failles.
Les data scientists du département proposent alors de mettre en place un modèle leur permettant de prévenir ces défaillances en amont afin de mieux cibler les machines à surveiller. Après quelques échanges avec les équipes de maintenance, ils ont pu établir certains éléments.
Les prédictions devront être faites à trois semaines une seule fois par semaine, c’est le temps nécessaire aux équipes de maintenance pour commander les pièces manquantes et effectuer une opération sans couper la production en cas de détection de défaillance. On note par ailleurs que la prédiction n’est pas critique, si les prédictions ne sont pas disponibles le jour même, il est possible de les fournir le lendemain sans handicaper les équipes.
Les données d’entrée de ce modèle, issues des différents capteurs, ne sont susceptibles d’évoluer qu’en cas de changements majeurs sur la ligne de production. Des changements de ce type n’ont pas lieu plus d’une fois tous les deux ans. Le modèle que l’on mettra en production n’aura donc pas besoin d’être ré-entraîné régulièrement et pourra tourner tel quel pendant de longues périodes.
Ils désirent tout de même garder de la visibilité sur les performances du modèle pour s’assurer de sa fiabilité dans le temps.
Enfin, vous notez par ailleurs que les data scientists chargés de développer et maintenir le modèle ne sont pas très familiers avec les environnements cloud.
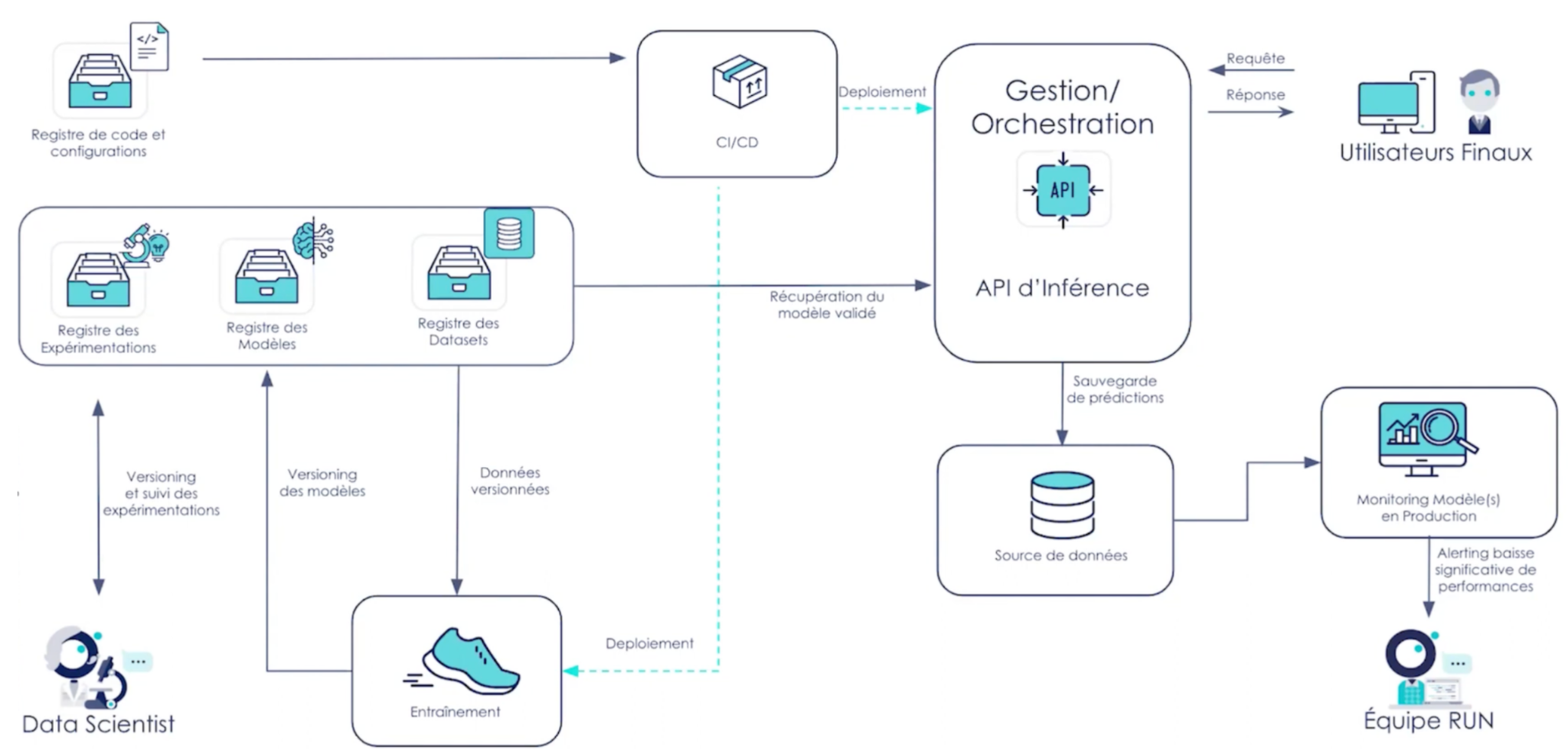
Schéma d’architecture fonctionnelle proposée :
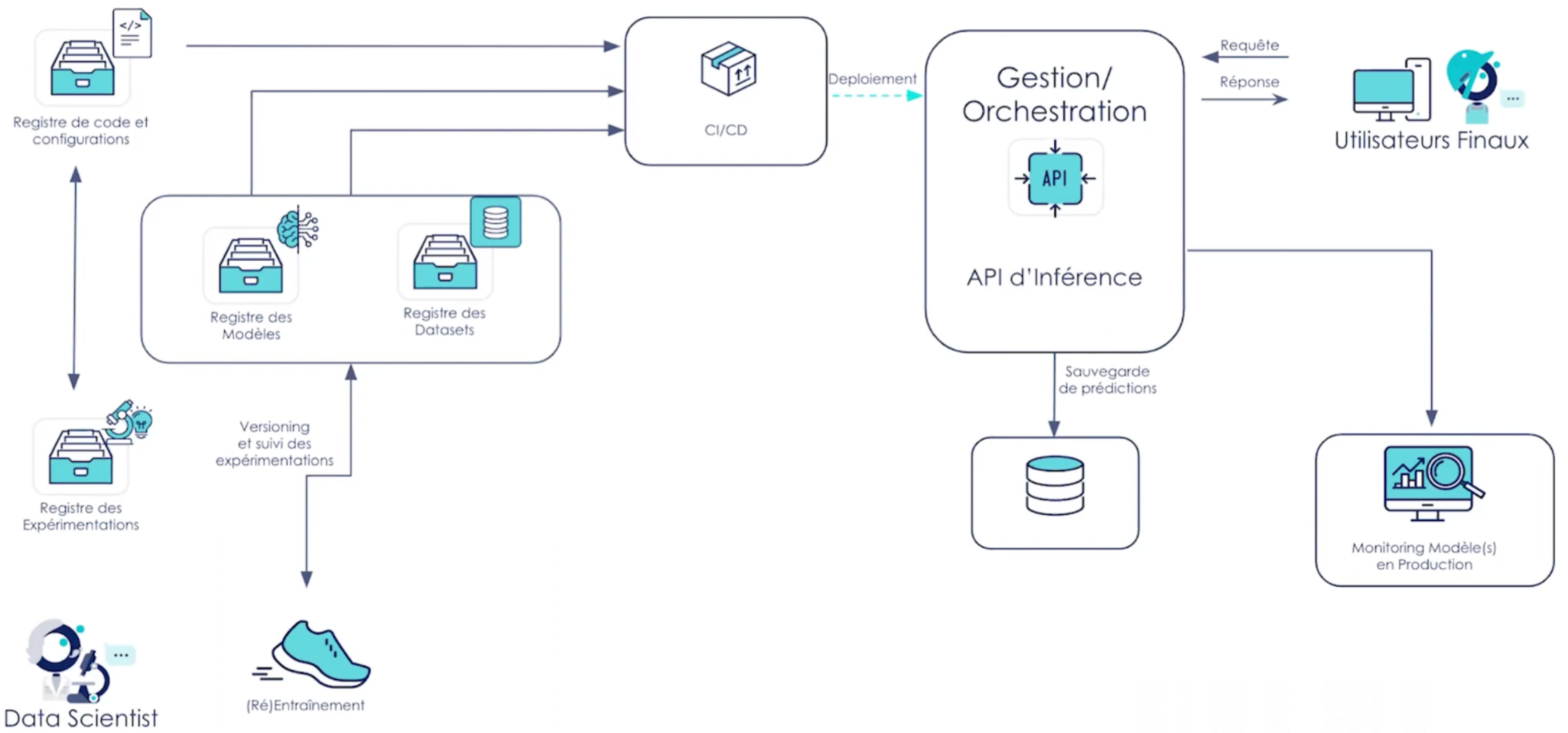
Les décisions qui ont été prises pour construire l’architecture sont les suivantes : L'entraînement et réentrainement du modèle est relativement léger, il peut être effectué localement par les data scientists. Il n’y a pas de nécessité de proposer d’instances clouds pour cette étape. La mise en production se fera par l'upload des modèles et des données dans un object storage simple permettant de conserver une trace des différents modèles mis en production. Le déploiement est fait par le biais d’une chaîne de CI/CD qui récupèrera le modèle souhaité et le mettra en production dans un service d’inférence, ici un point API. On souhaite sauvegarder les prédictions dans une base de données afin d’assurer le monitoring du modèle en permettant la comparaison de ces prédictions avec la ground truth lorsqu’elle sera disponible. Cela pour s’assurer de la pertinence du modèle dans le temps. Un monitoring simple est nécessaire, afin de s’assurer que le modèle fonctionne toujours
Quels services des cloud providers utiliser ici ?
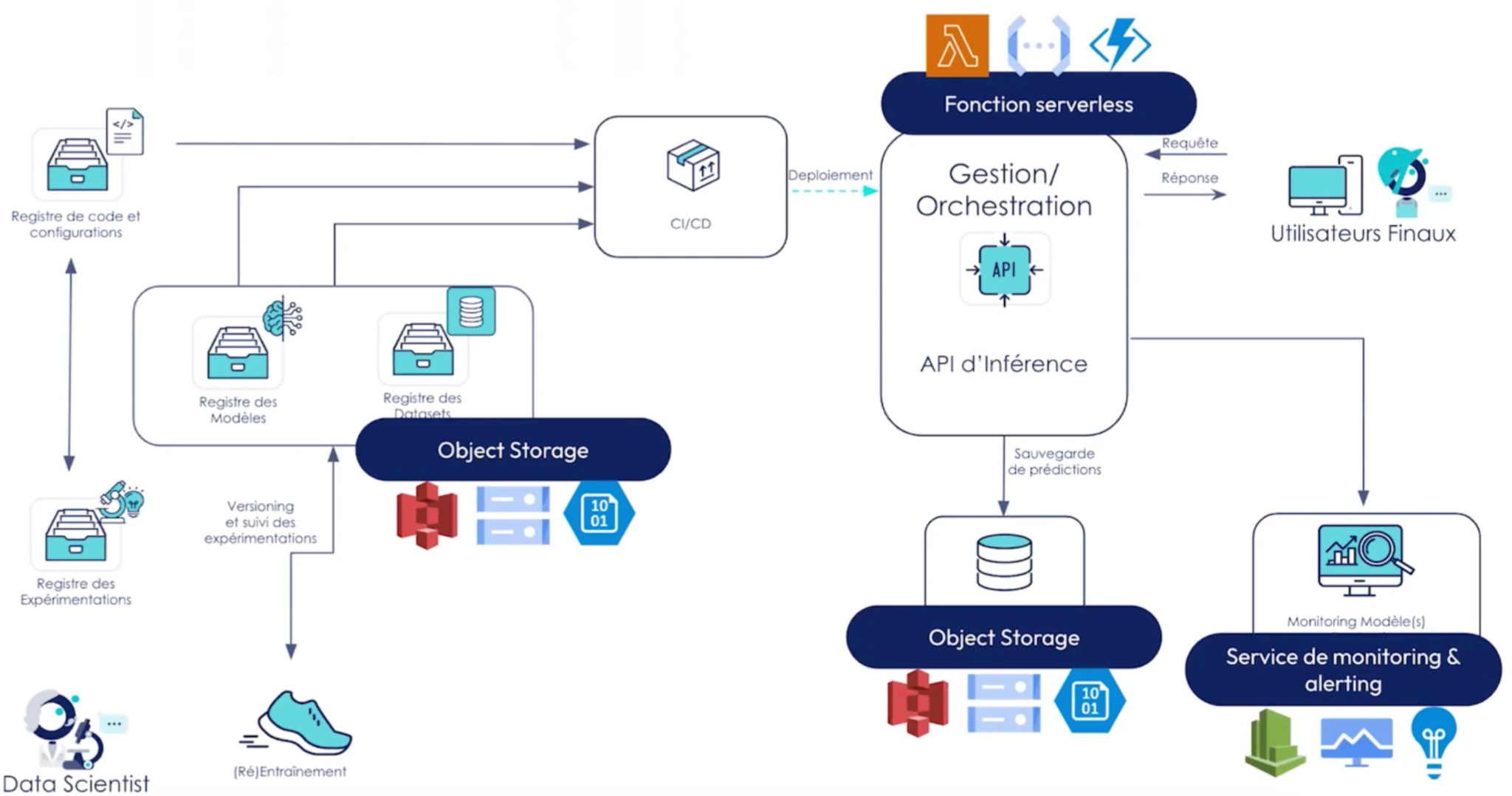
On choisira des services basiques :
- Object storage (Amazone S3, blob storage, Google storage) pour la sauvegarde et l’historisation des modèles et datasets basiques avec timestamp ou n° de version entrés programmatiquement.
- Des fonctions serverless (Lambda functions, Azure functions, Cloud functions) pour l’exposition. On déploie notre code et notre modèle qui seront exposés via une API permettant le déclenchement de ces fonctions.
- Object storage (Amazone S3, Blob storage, Google storage) pour la sauvegarde des prédictions.
- Service de monitoring basiques (AWS Cloudwatch, …). Ces outils proposent automatiquement un ensemble de métriques, les logs des fonctions par exemple auxquels peuvent s'ajouter des métriques personnalisées telles que le nombre d’instances qui ont été utilisées lors d’une prédiction. On pourra également mettre en place facilement de l’alerting par mails par le biais de ces services en fonction de seuils anormaux.
# Projet 2 : Prédiction des stocks
L'équipe d'achat se trouve face à un défi de taille : optimiser ses stocks pour la production quotidienne de bonbons. Consciente des fluctuations de la demande et des contraintes de production, l'équipe décide de recourir à l'analyse prédictive pour anticiper au mieux ses besoins en matières premières. Au cours des réunions initiales, il apparaît clairement que ce projet nécessitera une quantité importante de données d’entrée provenant de sources variées. Les données sur la demande et les stocks sont complexes et volatiles, exigeant un focus particulier sur le feature engineering et de nombreuses expérimentations pour capturer au mieux les nuances du marché. La criticité des prédictions est mise en avant : chaque jour, à 10 heures précises, l'équipe d'achat doit disposer des prévisions actualisées afin de passer commande avant midi. Cela implique une gestion minutieuse des modèles et des infrastructures pour garantir une disponibilité sans faille et une précision optimale. Heureusement, l'équipe de data scientists en charge de ce projet possède une bonne connaissance des outils cloud. Cette expertise leur permettra de déployer et de maintenir efficacement l'ensemble de l'architecture nécessaire à cette tâche exigeante.
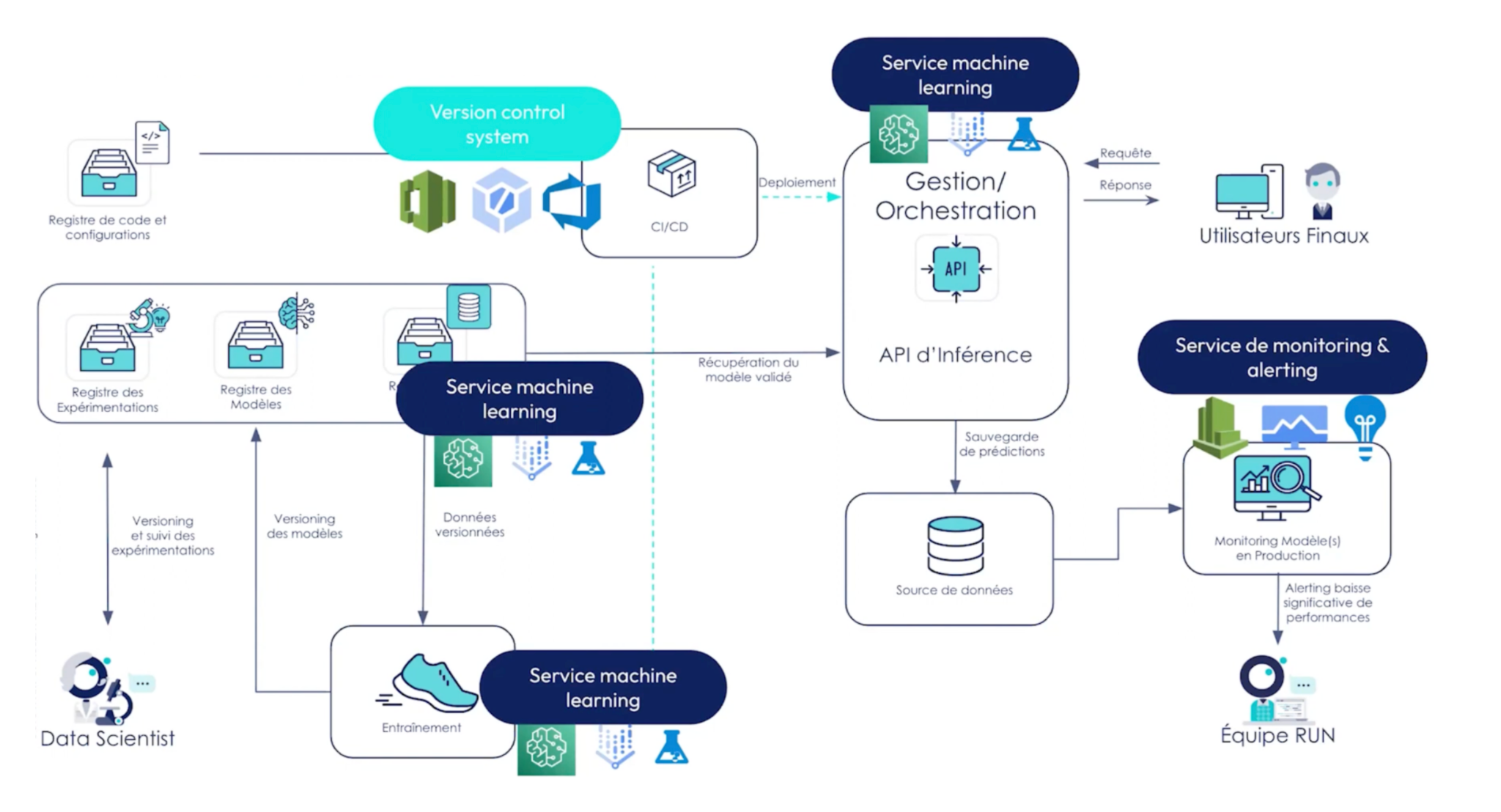
Schéma d’architecture fonctionnelle proposée :
Ici l'entraînement est plus lourd, on va chercher à utiliser les solutions des cloud providers pour plusieurs raisons :
- Le feature engineering complexe sous-entend des sources de données variées et nous chercherons à utiliser des solutions de pipeline.
- Les données sont plus volumineuses. Elles ne peuvent pas être traitées dans des temps raisonnables sur les ordinateurs personnels des équipes.
- On souhaite avoir la possibilité de lancer différents modèles en parallèle afin de les comparer a posteriori.
Les décisions qui ont été prises pour construire l’architecture sont les suivantes : Nous souhaitons également utiliser un model registry plus évolué afin de conserver l’historique des expérimentations avec les hyper paramètres et les performances associées.
L’ajout de versions control system propres aux cloud providers (AWS code commit, Azure DevOps, Cloud Workstation) peut devenir pertinent pour gérer les éléments d’architecture cloud utilisés. Ces outils sont généralement mieux intégrés aux services propriétaires des fournisseurs que les standards proposés par GitHub, GitLab ou autre.
Quels services des cloud providers utiliser ici ?
Nous utilisons ici les services de machine learning des cloud providers tels que : AWS Sagemaker, Vertex AI et Azure ML. Ce sont des boîtes à outils centralisent un grand nombre de fonctionnalitées :
- Pipelining: On peut définir notre traitement de données comme une suite d’étapes, avec des inputs et output qui seront automatiquement versionnés
- Model registry : Versionnement des modèles et datasets automatisés.
- Service d’inférence : Ici nous choisirons de mettre en place un end-point qui utilisera le modèle désiré du model registry.
Si on ne souhaite pas utiliser ces services « boîte à outil » ?
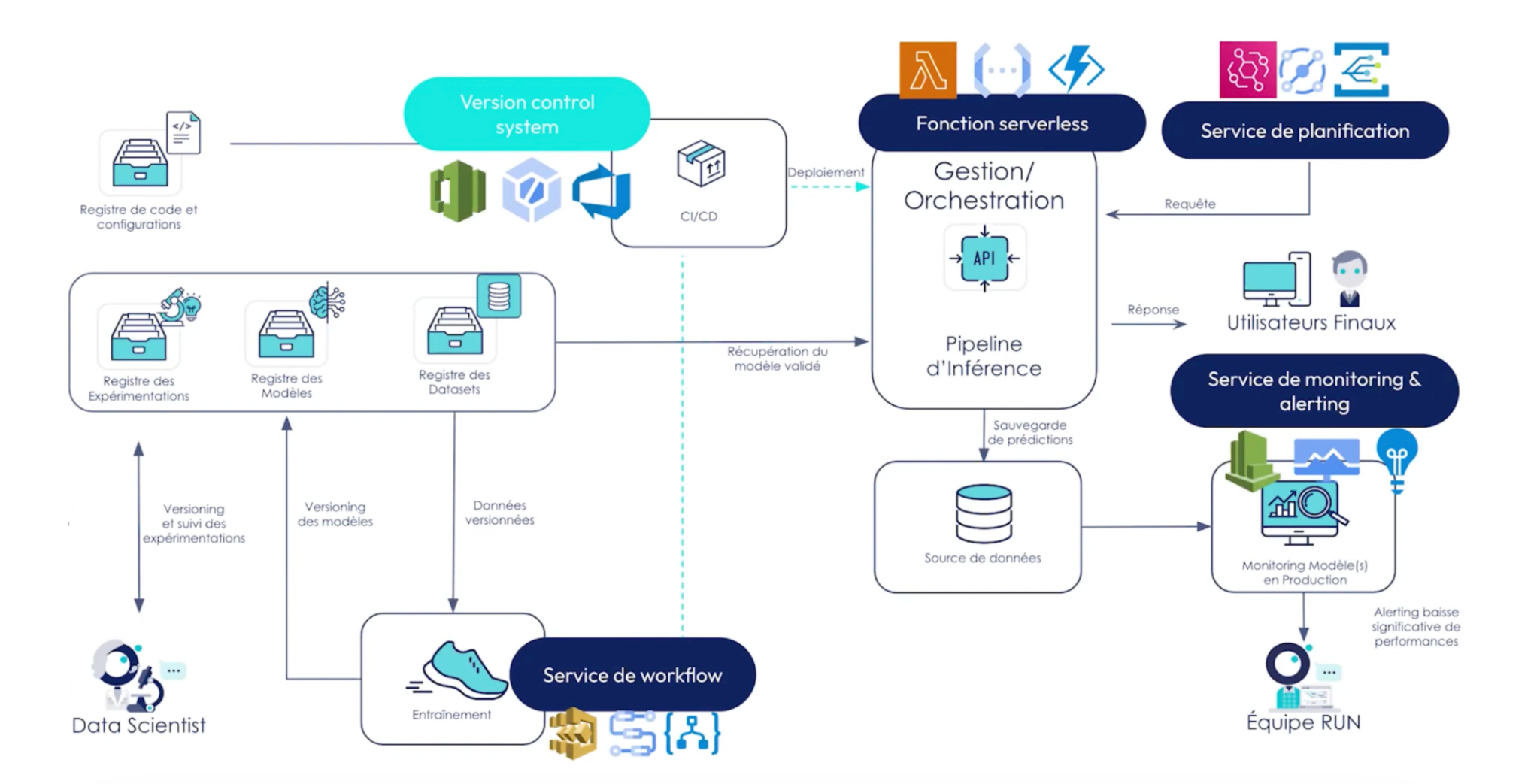
Les outils cités précédemment représentent un certain coût d’entrée. Ils sont très spécifiques aux cloud providers : les mêmes concepts portent des noms différents, n’exposent pas les mêmes API, etc.. Il n’est pas évident de passer de l’un à l’autre.
Il existe des alternatives plus éprouvées et généralistes mais moins dédiées au ML, répondant également à ces problématiques:
- Workflow pour les pipelines: Step Functions AWS, permettent d'enchaîner des taches, sur des fonctions serverless ou des clusters EMR par exemple.
- Les fonctions serverless pour l’exposition des modèles sous forme d’api pour des batchs d’inférence.
- Service de planification (Event bridge) pour le déclenchement des inférences.
# Projet 3 : Classification automatique de bonbons
Depuis quelque temps, l'entreprise de a connu une augmentation conséquente de la demande de ses produits, ce qui a entraîné une augmentation de la production. Cependant, cette croissance s'est accompagnée de nouveaux défis, notamment en termes de tri et de classification des différents types de bonbons.
Pour répondre à ces défis, l'équipe de data scientists a suggéré de mettre en place un système de classification des bonbons par reconnaissance d'images. Ils ont souligné plusieurs exigences spécifiques pour ce projet : Tout d'abord, ils ont besoin d'un accès à des GPU pour l'entraînement et l'inférence des modèles, étant donné la puissance de calcul requise pour du traitement d’images. De plus, de nouveaux types de bonbons sont régulièrement introduits sur le marché, il est crucial que le modèle soit capable de s'adapter à ces évolutions. Cela signifie qu'un mécanisme de réentraînement automatique doit être mis en place pour garantir que le modèle reste pertinent et précis au fil du temps. En outre, avec la hausse de la demande, il est essentiel que le système soit capable de faire face à une sollicitation élevée. Pour assurer la disponibilité des prédictions, un système d'auto-scaling doit être mis en place afin de permettre un passage à l'échelle automatique en fonction de la charge de travail. Enfin, l'équipe de data scientists en question est très à l'aise avec les environnements cloud.
Schéma d’architecture fonctionnelle proposée:
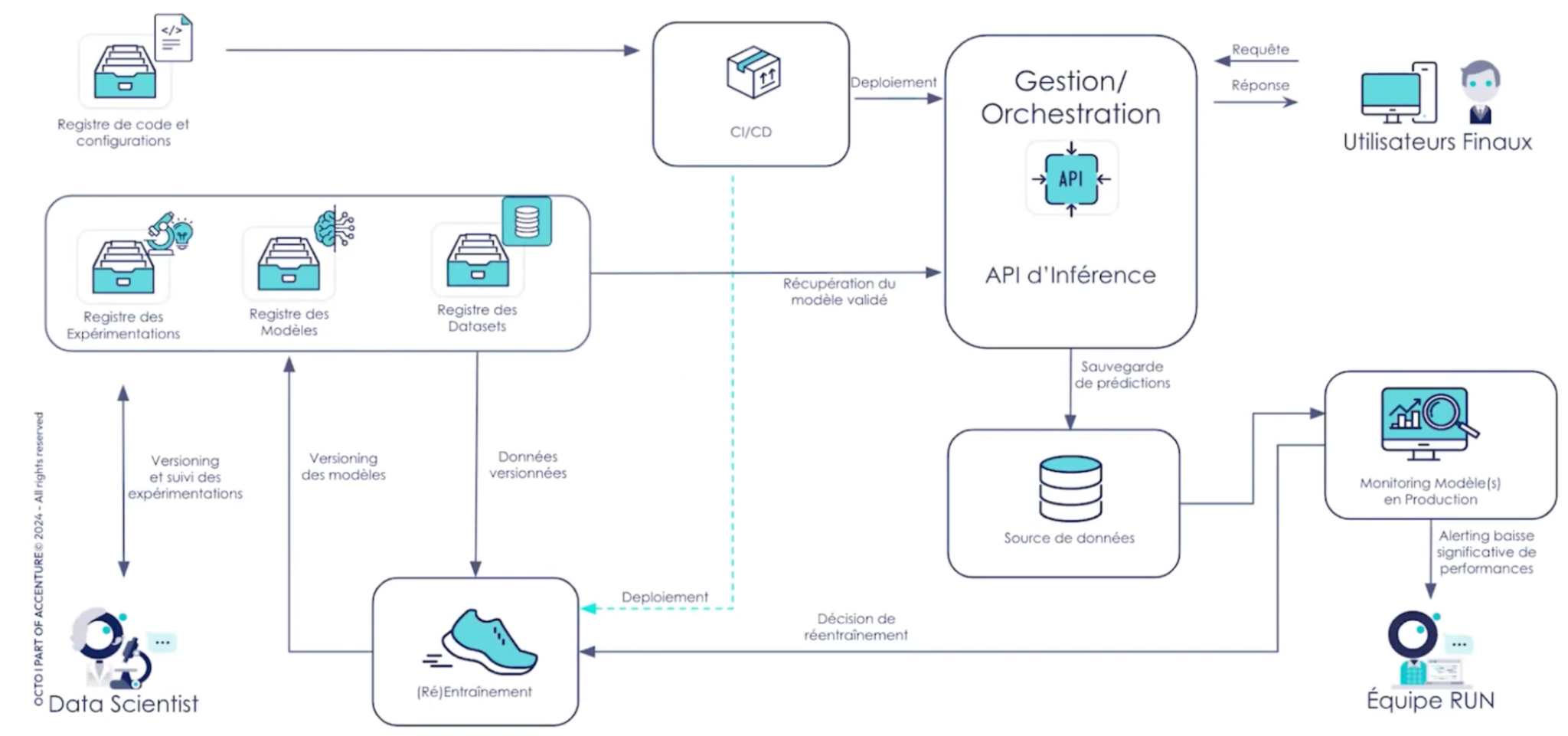
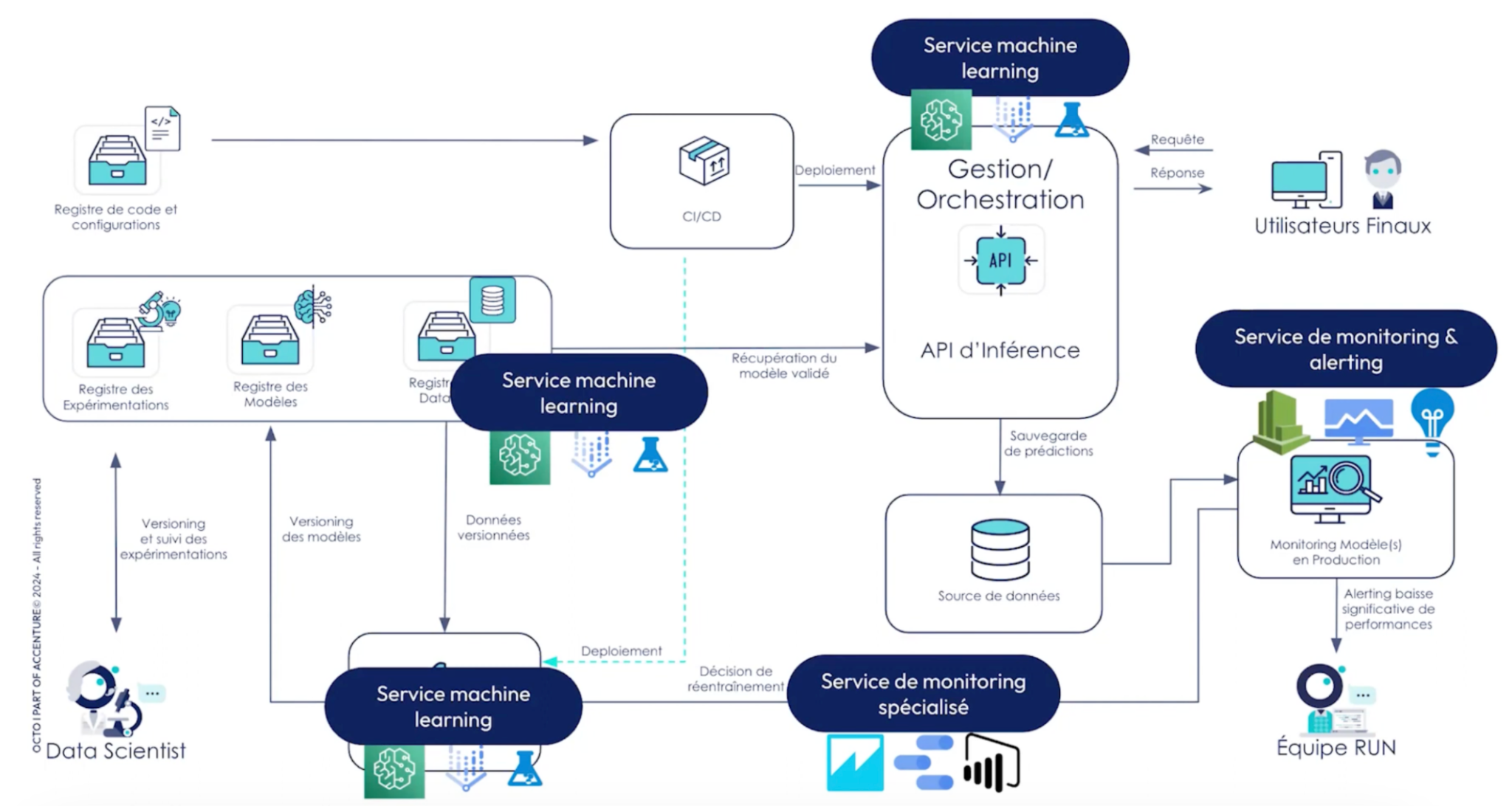
On peut ajouter aux services de monitoring précédents des services supplémentaires des outils de dashboarding (Amazon Quicksight, Power BI) pour visualiser l’évolution de certaines KPI pour automatiser le réentraînement des modèles si un seuil est dépassé. Ce réentraînement peut notamment être accompagné d’étapes de comparaisons entre le nouveau modèle et celui précédemment en production avec une mise en production sous condition de meilleures performances.
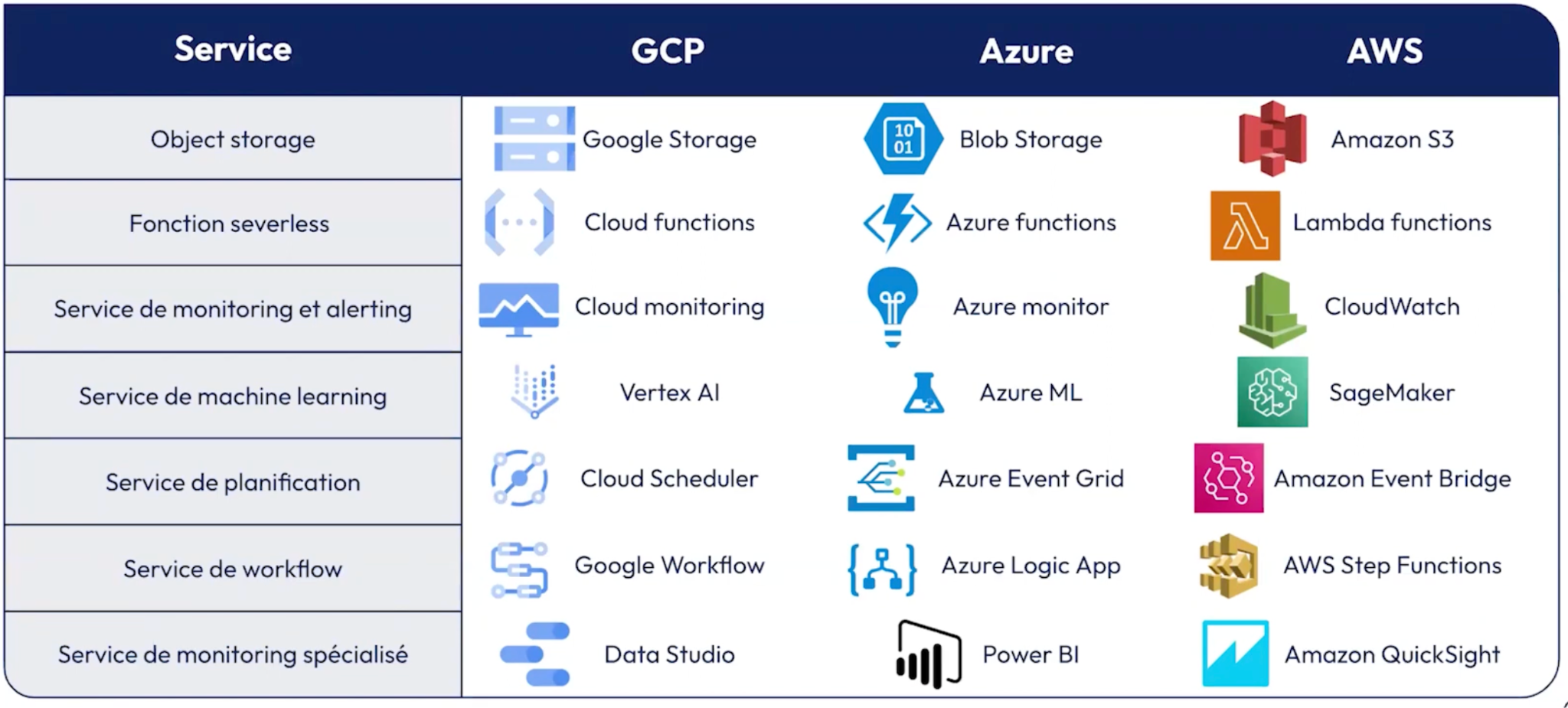
Tableau récapitulatif
Penser au futur
Quelles questions doit-on se poser sur le futur de notre projet lors de la phase de conception ?
Nous avons considéré jusqu’ici la phase de build. Cependant deux phases suivent généralement celle-ci:
- La phase de transfert qui consiste en un échange entre l’équipe de build et l’équipe de run
- La phase de run qui a pour but de maintenir en conditions opérationnelles le projet.
Les équipes de build et de run sont généralement des équipes différentes, avec des compétences différentes. Les services et outils sur lesquels ont été développés le projet doivent donc être facile à prendre en main par les équipes chargées d’assurer le run.C’est donc un point essentiel lors dès lors que vous êtes en phase de build, il sera important de rapidement identifier qui reprendra la suite du projet (taille d’équipe, compétences, etc.) afin de choisir les technologies et services adaptées.
Le build est terminé et ensuite ?
Le projet continue à vivre, les services continuent à facturer. Il faut s’assurer au moment du build que les coûts et l’architecture sont cohérents avec les bénéfices du projet. Si l'on construit une architecture avec tous les services présentés dans le dernier projet tels que des GPU et du réentraînement automatique pour réaliser le projet de maintenance prédictive. Le coût d’exploitation peut rapidement dépasser les bénéfices du projet. On constate donc un problème de design à la base de celui-ci.
Si la maintenance prédictive permet d’éviter en moyenne un défaut de 5000€ par mois générés par les coupures sur la chaîne de production, mais que l'exécution du modèle en coûte plus de 7000€, il est plus judicieux de le désactiver ou de le repenser afin de l'alléger.
Il faut également envisager l’évolutivité de l’architecture et s’assurer de sa modularité au moment du build pour répondre à de potentielles évolutions. On ne souhaite pas être contraint à reconstruire ce projet à la base pour éviter les surcoûts de développement. Sans chercher à développer en amont l’ensemble des futurs besoins potentiels du projet, celui-ci doit être suffisamment modulaire pour pouvoir l’enrichir.
Il faut donc penser à cette phase de run et de maintenance lors du build.
prise de recul
Nous avons pu constater sur les différents exemples trois niveaux de maturité MLOps. Nous avons ici cherché à illustrer une notion introduite par Google des niveaux de maturité d’un projet MLOps.
Niveau 0 : Ensemble de bonnes pratiques minimale sur un projet de ML
- Entrainement, validation et déploiement manuel
- Logging des inférences et monitoring
- Pipeline d’inférence avec intégration automatique de ce dernier
Niveau 1 : Plus d’automatisation des process
- Orchestration de l'entraînement
- Versionning des entrainements
- Tracking des experiences
- Validation automatique des modèles
Niveau 2 : Maximisation de l’automatisation
- Continuous training
- Monitoring (usage et feedback, ground truth)
- Alerting
- Analyse du drift
Il est important de noter que cette pyramide doit être adaptée aux besoins de votre entreprise, tout le monde n’a pas les mêmes besoins en termes de MLOps. Il convient donc de ne choisir que les briques pertinentes pour vous. Cette pyramide a déjà été présentée plus en détail lors d’un précédent comptoire Octo disponible en replay en suivant ce lien: https://www.youtube.com/watch?v=9sdWh6T6t-8
Comment choisir son niveau et son architecture
Le choix du niveau MLOps souhaité et par conséquent de son architecture est basé sur plusieurs axes :
Contraintes liées au modèle
- Complexité
- fréquence de mise à jour
- Boucle de rétroaction et étiquetage
Contraintes opérationnelles
- Criticité opérationnelle du produit et des modèles
- Maîtrise des coûts
Exploitation
- Equipe d’exploitation
- Maintenance et évolutivité
Takeaways
- Niveau d'investissement minimal : L'investissement en termes de temps, de bonnes pratiques, de services doit être en accord avec les besoins du projet.
- Ne pas être jusqu’au-boutiste : Ne pas aller vers le dernier niveau d’automatisation dès le lancement du projet, mais y aller de manière itérative. Éviter de chercher à ajouter des services supplémentaires tant qu’ils ne sont pas nécessaires.
- Penser au run : Garder en tête la phase de run du projet pendant le build, du point de vue des compétences des équipes mais aussi du point de vue des coûts.
- Itérative et Évolutive : Chercher à éviter de se retrouver bloqué et contraint à repenser le projet à la base lors de l’apparition de nouvelles fonctionnalités ou contraintes.