Comment structurer vos équipes et démocratiser l’Intelligence Artificielle au sein de votre organisation
Introduction des auteurs et de l’initiative
Dans le cadre des réflexions d’OCTO Technology sur les grands enjeux du monde de la data, Jean-Baptiste Larraufie consultant OCTO et Ming-Li Gridel Directrice Data science chez DataRobot ont amorcé une discussion sur l’évolution des structures data dans les entreprises.
En tant que conseiller stratégique sur les initiatives data de grands groupes français, OCTO Technology a contribué à diverses et nombreuses missions d'Intelligence Artificielle (IA) et assisté à la structuration d’équipes Data chez nombre d’entreprises de l’hexagone. DataRobot, partenaire d’OCTO, est une entreprise internationale qui offre depuis 10 ans une plateforme de bout en bout dédiée au Machine Learning. DataRobot a suivi l’évolution des stratégies IA aussi bien aux Etats Unis, en Asie, au Moyen Orient ou plus spécifiquement en France. Nos deux compagnies ont vu des schémas se répéter sur les projets data science, avec des échecs à retirer et des bonnes pratiques à garder.
Ces dernières années plusieurs entreprises se sont orientées vers une stratégie d’intelligence artificielle implémentée dans les processus métier et à l'échelle. Stratégie semée d'embûches, quels moyens pour que l’IA tienne ses promesses ?Cet article démarre par un état des lieux des structures data science et identifie quelques facteurs d'échecs potentiels de l'implémentation des IA. Il s’attarde ensuite sur les solutions pour favoriser le bon déroulement d’un projet Machine Learning (ML) jusqu'à la mise en production. Pour finir, il présente une stratégie de passage à l’échelle que l’on constate de plus en plus empruntée : la démocratisation de l’IA.
Chapitre 1 : Le constat
L'Intelligence Artificielle est sur toutes les bouches. L’adoption de cette technologie est en constante augmentation. C’est un phénomène qui s’observe dans toutes les industries mais aussi dans de nombreuses lignes de métiers. L'étude 2021 de McKinsey1 montre que, malgré les problèmes causés par le covid, 56% des entreprises ont adopté l’IA dans au moins une de leurs lignes métier, soit 6 points de plus qu’en 2020.
Historiquement les entreprises pionnières ont lancé leurs initiatives IA par un recrutement massif de data scientists. Depuis ces premiers pas, plusieurs années sont passées, le constat aujourd'hui est que de nombreux projets IA échouent. Ces projets génèrent beaucoup d'expérimentation, de code et demandent du temps… mais n’aboutissent pas toujours à une implémentation métier. La valeur n’est pas au rendez-vous. Il en ressort que 85% des projets IA restent à l'état de prototypes2, ne sont pas adoptés par les métiers puis sont mis de côté. L’enseignement est riche pour les futurs projets. Ce qui coince ce n’est pas le code, pas les mathématiques, pas la technique. C’est l’organisation du projet. Lorsqu’on parle de “Projet IA”, on entend “IA”. Les raisons de ces échecs sont souvent liées à la dimension “Projet”.
L’équipe Analytics d’une assurance a identifié un cas d’usage intéressant pour l’entreprise : score d'appétence client aux produits. L’étude de faisabilité a montré que la donnée était disponible et de qualité. L’équipe a identifié le système où indiquer aux opérationnels l'appétence client. Techniquement le projet a été mené à bien avec une présentation aux agents de terrain à la fin. Cependant il y a eu peu d’adoption des recommandations IA de la part des métiers. Ainsi l’impact mesuré a été très faible. En effet le processus opérationnel n’a pas été modifié pour prendre des actions en fonction des scores. Le projet n’a pas permis à l'assurance d'attirer de nouveaux clients.
Exemple de projet IA non abouti
On observe bien souvent une équipe centralisée de data scientists. Ces derniers se partagent une multitude de sujets métiers et ne disposent pas de connaissances spécifiques du terrain. Ils tentent d’apporter une réponse technique aux problématiques opérationnelles. Dans le pire des cas, seuls face à des données issues de périmètres méconnus, ils échouent avant même la proposition d’une solution viable. Dans le meilleur des cas, les data scientists parviennent à construire une solution théorique, dont le niveau de performance observé pendant l’expérimentation atteint les objectifs initiaux et ravit les sponsors du projet. Seulement, c’est lors de l’étape mise en production et d’implémentation qu’ils font face à de plus grands obstacles.
Structure Data Science en silo
Cette structure data science en silo n’est pas une approche qui a porté ses fruits. Détaillons quelques situations auxquelles elle doit faire face.
- Scénario "Face à la réalité opérationnelle" : les modèles de machine-learning doivent souvent intégrer des processus opérationnels existants, parfois complexes ou critiques et dont les responsables souhaitent préserver le contrôle pour garantir leur bon fonctionnement. Il sera difficile de convaincre ces responsables d’accepter l’aléa des modèles de machine learning s’ils ne sont pas partie intégrante du projet de bout en bout.
- Scénario “Adoption“ : les prédictions produites par les IA peuvent être utilisées par des systèmes pour des actions automatiques. Cependant elles sont souvent partagées à des utilisateurs finaux pour les aider à prendre des décisions éclairées par la donnée. Comment ces utilisateurs adopteront-ils un système qu’on leur impose, avec lequel ils n’ont pas défini les modalités d’un “contrat de confiance” ? La compréhension de leur processus actuel est primordiale pour désigner correctement les processus de demain. Les intégrer en amont du développement et dans l'évaluation du modèle permet de réduire le risque de non-adoption.
- Scénario “Partage des responsabilités” : Pour que le modèle soit opérant en production au sein de l’organisation, le partage des responsabilités est obligatoire : amélioration continue, opérationnalisation et monitoring du modèle pour n’en citer que trois. Les équipes exclues du design du modèle peuvent refuser d’endosser ces responsabilités. Certaines organisations proposent que les IA en production restent à charge des data scientists. Avoir une équipe qui assume l’entière responsabilité d’un nombre croissant de modèles et d’applications d’intelligence artificielle ne permet pas de continuer le développement de nouveaux modèles. On se retrouve alors avec des data scientists débordés et une feuille de route qui n’avance pas.
L'équipe Data science d’un grand groupe financier a développé plusieurs modèles de scores. Pour avancer plus rapidement, ils se sont chargés du déploiement des modèles et ont pris la responsabilité de la maintenance en production à la place des équipes IT. Avec l’augmentation du nombre de modèles implémentés, l'équipe a dû passer davantage de temps sur la maintenance et le rafraîchissement des modèles. La conséquence directe a été le ralentissement puis l'arrêt de la roadmap de développement de nouveaux cas d’usage.
La production bloque le développement
Les nombreux échecs de projets IA invalident l’approche d’une équipe Data science en silo. Il est primordial d’avoir une équipe projet pluridisciplinaire dès la phase de conception afin de prendre en considération les contraintes data science, techniques et métiers.
Chapitre 2 : Orchestration d’une dynamique IA efficace
Alors, quelle est la structure et l'équipe de rêve ? Et comment fait-on travailler ses membres ensemble ? Rien de bien nouveau, et c’est notre conviction chez OCTO et DataRobot, il faut réunir une équipe pluri-disciplinaire entièrement mobilisée dont l'objectif est de façonner un produit utile, utilisable et utilisé.
En s’inspirant notamment de la vision des géants du web3 et plus globalement de “Team Topology”, nous convergeons sur le concept de “squad” soit une équipe pluridisciplinaire, agile et auto-organisée. Quelques principes clés :
- Autonomie et responsabilité collective : l'équipe est collectivement responsable de la livraison et de l'exécution de bout en bout du cas d’usage, des composants et des conseils qu'elle fournit.
- Relations fonctionnelles : les membres de l’équipe ont des relations fonctionnelles. Un membre de l'équipe est généralement désigné comme chef d'escouade.
- Colocation : les membres de l'équipe sont autant que possible installés dans le même bureau afin de favoriser la collaboration et les interactions humaines.
- Agilité et frugalité : les équipes sont composées d'environ 5 à 10 personnes. Les cas d’usage plus importants peuvent être décomposés en fonctionnalités/composants pour éviter une inertie due au nombre.
Présentons d’abord quelques exemples de métiers qui œuvrent de nos jours dans des squads qui délivrent des projets d’IA.

L’équipe idéale à mobiliser pour construire des applications d’Intelligence Artificielle.
Ce carrousel de personnages illustre bien la dimension pluridisciplinaire, essentielle à la réussite de vos projets d’IA. Sans être exhaustive, cette liste de métiers permet de répondre, dans les meilleures conditions, à un grand nombre de cas d’usage en machine learning. À cette liste, on pourrait par exemple ajouter des profils comme les data owners et data stewards, artisans de la bonne gouvernance des données au sein de l'entreprise ou des C-levels, en mesure de prendre les décisions facilitant l’atteinte des objectifs ou de calibrer l’investissement de l’équipe relativement aux bénéfices envisagés pour l’entreprise.
La mobilisation de ces expertises n’est pas uniforme sur toute la durée du projet, certaines d’entre elles sont bien plus ponctuelles par exemple. La représentation ci-après donne un aperçu de la typologie de squad à impliquer en fonction de la phase du projet. Pour simplifier, nous n’avons illustré sur le schéma que deux phases.
- phase d’initialisation : quelques semaines de cadrage et rapide prototypage par une équipe réduite mais représentative pour évaluer du potentiel de l’initiative. Un conseil : si l'initiative doit finalement échouer, autant le savoir rapidement et ne pas consommer trop de temps et d'énergie. Nous préconisons ainsi de suivre une approche de type fail fast 4.
- phase de développement : elle se déroule en plusieurs cycles d’itérations de développement du produit en mode agile. Tant que la backlog du projet vit, c’est que celui-ci suscite suffisamment d'intérêt pour continuer d’investir et des cycles de développements sont relancés.
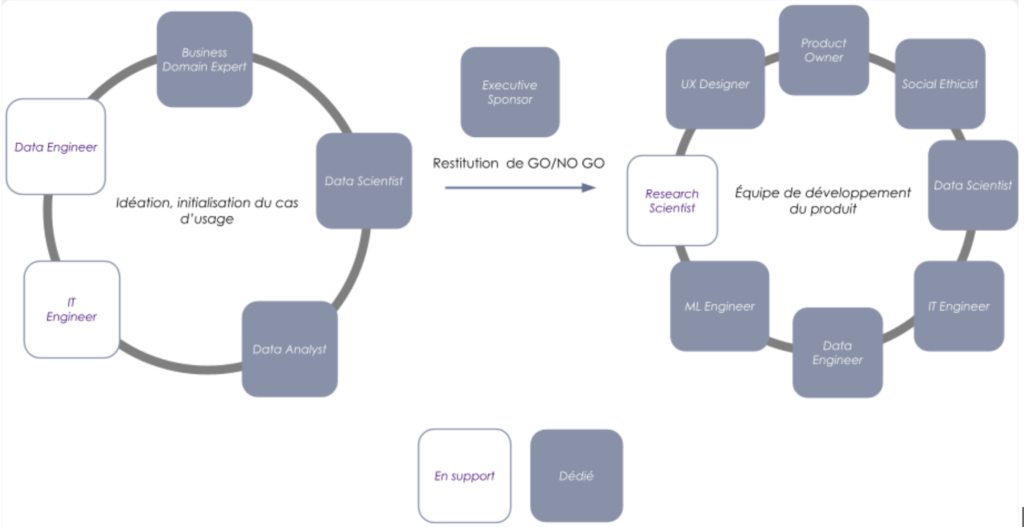
On remarque une mobilisation évolutive de la phase d'idéation au développement de l’application d’intelligence artificielle. Pour conclure l’illustration de cette squad, présentons certaines des interactions qui justifient la pluridisciplinarité requise sur les projets d’intelligence artificielle.
Quelles interactions entre Business Domain Expert, Data-Analyst et Data-Scientist
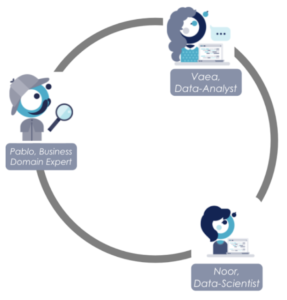
En qualité de représentant des utilisateurs finaux, Pablo aiguille Noor sur les hypothèses d’ordre métier à considérer pour la construction d’un modèle fidèle à la réalité. Grâce à l’expertise métier et ses connaissances des process business de Pablo, il est plus évident pour Noor d’appliquer des pré-traitements efficaces (filtrage de données par périmètre par exemple), de créer de nouvelles données riches en signal (“feature engineering”, ndlr) ou de construire des posts-traitements permettant aux utilisateurs finaux d’activer les prédictions sous forme de décisions.
Grâce à des solutions de visualisation par exemple, Vaea cherche à confirmer ou infirmer les hypothèses d’ordre métier formulées par Pablo sur les données. Elle apporte aussi une aide précieuse à Noor afin de valoriser les premiers résultats des modèles dans un format compréhensible par les utilisateurs finaux, grâce en partie au conseil du Pablo sur les enjeux et contraintes de ces derniers.
Quelles interactions entre Data-Engineer, Data-Scientist et ML Engineer
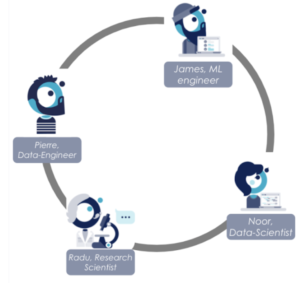
Pierre et Noor sont indissociables et coopèrent pour maximiser le volume de données (internes et externes à l’organisation) à disposition des modèles de data science. Pierre se confronte aussi aux enjeux de contrôle de qualité des données, de fréquence de distribution, de rafraîchissements des données et de diversité des structures de données à pré-traiter selon les pré-requis que Noor lui formule.
Noor livre à James le code packagé du modèle pour qu’il puisse être industrialisé sur une infrastructure robuste et exposé au travers d’une application utilisable. Noor travaille également de concert avec James pour implémenter l’évaluation de la performance du système en production et les mécaniques de réentraînement.
Pierre et James coopèrent essentiellement sur les aspects de monitoring de la dérive des données d’inférence, de capture des sources de non-déterminisme, de mise à disposition des données futures au système et de diffusion des prédictions aux applications ou base de données consommatrices.
Enfin, Radu se tient informé des travaux de recherches en intelligence artificielle et profite des initiatives Data pour les confronter à l’état de l’art. Avec Noor notamment, ils travaillent sur des sujets comme l’interprétabilité ou de nouvelles formes d’apprentissage des modèles (ex: federated learning)
Avec des équipes de cette diversité et de ce niveau d’expertise, les chances de mener des projets d’intelligence artificielle en production et de façon durable augmentent mécaniquement. En contrepartie, il faudra investir du temps et de l’argent pour constituer de telles squads composées de profils bénéficiant d’une position privilégiée sur le marché. De façon générale, les candidats talentueux se montrent exigeants aussi bien sur la qualité de l’opportunité (challenge techniques, agilité, environnement innovant) que sur le plan de la rémunération. Enfin, il faudra s'assurer que les compétences et connaissances se partagent au sein de l'équipe data pour pallier au risque d’attrition.
Favoriser l’expérimentation et stimuler l’intelligence collective autour des sujets d’IA, en la démocratisant dans l’organisation, est une des solutions possibles pour compenser le manque de ressources expertes. Pour rendre cette technologie populaire au sein de l’organisation, il faut à minima :
- Une communauté de data scientists capable de vulgariser leur expertise
- Des outils pour pratiquer la data science de façon collaborative
- Une gouvernance autour des initiatives de data science et leur passage à l’échelle
- Un parcours formation allant de la découverte des fondamentaux à un niveau avancé en data science
La question de la gouvernance ayant été abordée par le prisme des compétences précédemment, nous pouvons dès à présent nous intéresser à celle de l’outillage. La constitution d’une offre logicielle interne pour équiper les collaborateurs qui souhaitent mener des projets orientés “data” revient souvent dans les entreprises. Elle s’accompagne aussi souvent de la traditionnelle question du “make or buy” qui reste un vaste débat et pour lequel nous sommes convaincus qu’il n’existe pas de réponse évidente ou décontextualisée. La solution réside en partie dans sa capacité à répondre aux questions les plus structurantes, autour de sujets comme l’indépendance, les priorités technologiques, le niveau de spécificité des besoins ou les contraintes temporelles et budgétaires. Ci-après, quelques exemples de questions à se poser. Quel est le risque d’être dépendant d’un éditeur de logiciels ? Quelle est ma stratégie de sortie ? Ai-je les compétences en interne pour construire et maintenir ce code ? Quels sont les processus en place pour assurer le transfert de connaissances au fil du temps ?
À l’échelle des cas d’usage, des éléments clés de réponse au “make vs buy” résultent du mode d’utilisation souhaité de l’intelligence artificielle. Ci-après, un exemple de catégorisation pouvant être utilisée pour formuler un premier avis.
- Le modèle fait partie de la catégorie des “modèles communs” pour laquelle nous avons déjà beaucoup de recul scientifique et de nombreux retours d’expérience utilisateurs (exemple : modèle de classification d’images, modèle de détection d’anomalie) : l’option buy peut s’avérer judicieuse pour économiser du temps, bénéficier de performances prédictives optimales et profiter d’accélérateurs en tout genre.
- Le produit contient au moins une fonctionnalité basée sur du machine learning (exemple : l’algorithme de recommandation sur la plateforme Youtube) : favoriser le make lorsqu’il est impossible de déployer et d’exposer simplement, c’est à dire sans trop de contraintes d’architecture, le modèle construit au travers d’une plateforme buy de data-science.
- “Le modèle, c’est le produit” : make et buy se présentent comme deux alternatives pour vérifier en premier lieu que le modèle est faisable. Dans un second temps, il suffit de constituer une squad pluri-disciplinaire pour “designer” le produit qui conviendra aux utilisateurs, qu’il soit make or buy.
Dans la suite de l’article, nous explorerons les atouts qu’apporte un outillage orienté plateforme IA, comme DataRobot par exemple, les impacts qu’elle engendre sur l’organisation décrite ci-dessus et son influence sur la vélocité des projets d’intelligence artificielle.
Chapitre 3 : Comment passer à l'échelle avec une plateforme IA
Notre squad ML permet maintenant de mener des projets de bout en bout et éviter les affres de l’éternel prototype. Cependant certaines entreprises orientent leur stratégie vers de l’Intelligence Artificielle à l'échelle. Cela se traduit par des systèmes IA dans chaque ligne de métier et en volume croissant. Notre squad ML se retrouve donc face à une montagne de projets et n’a pas les ressources pour enclencher la prochaine vitesse.Une solution pour accélérer la roadmap IA est la démocratisation.
La démocratisation consiste à “mettre un bien à la portée de tous”. Transposée au domaine de l’intelligence artificielle, la démocratisation vise à rendre plus accessible des outils numériques qui requièrent par nature des compétences de programmation.
La démocratisation présente de nombreux avantages. Elle permet aux data analysts et “Business Domain Expert” d’intervenir sur les parties plus techniques. Ceux-ci pourront construire les modèles IA de façon quasi autonome. Gartner les nomme les Citizen Data scientists5. Ces profils sont souvent plus proches du terrain et amènent une combinaison équilibrée entre la data science et les exigences métiers. Les équipes IT et Data engineers peuvent aussi prendre les responsabilités de mise en production et du monitoring avec une plateforme de démocratisation MLOps. Pour les organisations plus modestes, embaucher une squad ML complète est trop coûteux. La démocratisation permet d’entamer une stratégie IA sans avoir à payer un fort coût d’entrée. Enfin en ouvrant l’accès aux compétences techniques, on augmente l’équipe capable de livrer des projets IA. Le backlog de projets se fait moins pesant. Concrètement, les citizen data scientists travaillent sur les projets IA plus communs, tandis que les profils plus experts en data science se concentrent sur les problématiques complexes.
Les data scientists n’en restent pas moins un pilier de la stratégie IA. Ils mettent un cadre autour des projets tenus par des citizen data scientists. Leur rôle sur de tels projets peut être de se positionner en mentor ou en superviseur des modèles avant la mise en production.
Observons les effets de la démocratisation sur notre squad ML. Maintenant que nous pouvons “augmenter” l’expertise de certains, un même personae peut désormais couvrir plusieurs rôles.
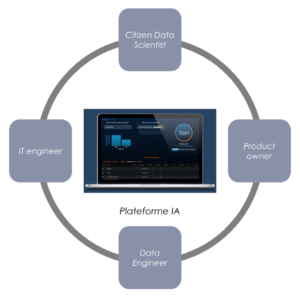
Il est facile d’observer qu’équipée d’une plateforme de démocratisation, notre squad a réduit en nombre. D’abord, apparaît le rôle de citizen data scientist qui combine les expertises de business domain expert, data analyst et data scientist, comme introduit plus haut.. Grâce à des fonctionnalités de détection ou prévention des biais intégrées à la plateforme, il/elle endosse également le rôle de Social Ethicist. En résumé, le citizen data scientist formalise les enjeux métiers, explore et analyse les données en vue de laisser la plateforme construire des modèles pertinents et performants (“AutoML”, nldr).
En plus de ses activités décrites en seconde section, le/la data engineer peut se substituer au ML engineer en industrialisant les modèles nativement depuis la plateforme. Il/elle se concentre également sur la mise en place du monitoring (dérive des données, performance au cours du temps, modèles challenger) et le déploiement du modèle pour les systèmes consommateurs des prédictions.
Quant à l’IT engineer, il/elle reste partie intégrante de la squad pour garantir les accès à la plateforme de démocratisation, fournir les infrastructures et assurer le monitoring technique. Le product owner reste présent pour garantir la cohérence entre le produit de ML packagé dans la plateforme et le besoin plus global des utilisateurs finaux.
Enfin, le rôle de research scientist est couvert par la plateforme, proportionnellement à la complétude de sa bibliothèque de modèles. Plus la plateforme est mature en terme de machine learning automatisé, moins la mobilisation de data scientists sera nécessaire. En revanche, si la plateforme de démocratisation est ouverte à l’open source, s’appuyer sur des data scientists au sein de la squad pour améliorer le feature engineering ou l’hyper-paramétrage du modèle, sera bénéfique sur la bonne construction des modèles.
La démocratisation de l’IA ne se fait cependant pas en un claquement de doigts. Elle requiert souvent la mise en place d’une plateforme spécialisée. Cette plateforme se doit d’avoir les ingrédients nécessaires pour nos Citizen Data scientists. Pour permettre le passage à l'échelle, c'est à dire la capacité d'avoir plusieurs dizaines, voire centaines de cas d'usage en production, il est recommandé de s’équiper d’une plateforme ayant notamment fonctionnalités suivantes :
- Intéractions des utilisateurs avec la plateforme rendues possibles aussi bien avec du code qu’avec l’interface
- Collaboration facilitée entre les profils expert, citizen data scientist et métier pour se partager les données, modèles, applications et autres artefacts du projet
- Data science didactique i.e. guide les utilisateurs de façon intuitive tout le long du projet
- Garde-fou pour éviter aux citizen data scientists les écueils tragiques du Machine Learning (target leakage, problème de qualité de la data, utilisation du mauvais algorithme, détection des bias...)
- Machine Learning de bout en bout avec des modules de préparation de données, développement de modèles, MLOps et consommation des IA
- Standardisations des projets pour faciliter les échanges entre collaborateurs et le transfert de projets
- Pas de “vendor Lock In” i.e. possibilité d’extraire les modèles construits sur la plateforme et fournir une flexibilité sur les environnements de développement et de déploiement
Une conséquence immédiate est de voir fleurir des îlots de citizen data scientists au sein des lignes de métiers, tous collaborant sur un même espace.
Cette plateforme de démocratisation passe nécessairement par de l’automatisation des tâches data science afin de rendre le processus accessible aux citizen data scientists. Ceci apporte encore un énième avantage aux organisations : la vélocité des projets. En effet, en s’éloignant du tout manuel on accélère la livraison des projets. Cela apporte aussi de la valeur chez les data scientists expérimentés qui utilisent la plateforme. Les différentes expériences menées par des clients DataRobot ont montré une efficacité en moyenne multipliée par 3 sur le temps de projets. Les accélérations se font à tous les niveaux, mais pour les experts data science on l’observe tout particulièrement sur la documentation, l’interprétabilité des modèles, le déploiement, le monitoring en temps réel, le ré-entraînement et la communication facilitée avec les métiers.
Pour les entreprises ayant déjà entamé leur initiative IA et ne pouvant pas recruter massivement des data scientists, les plateformes IA permettent de passer à l’échelle. Pour les plus petites structures ou nouvelles start-ups, elles permettent aussi de démarrer leur stratégie data science à moindre coût. Et ceci par le biais de la démocratisation et de l'accélération de l’ensemble du cycle projet.
Conclusion
Finalement, dans cet article nous avons constaté la difficulté à implémenter des IA et passer à l’échelle. Nous avons exposé notre point de vue sur l’influence d’une plateforme d’Intelligence Artificielle sur l’organisation et sur les équipes délivrant des modèles de machine learning. En acquérant une plateforme les entreprises qui comptent de nombreux experts métiers, un patrimoine de données, des processus à optimiser, une ambition de démocratiser la culture data, mais peu d’expérience en développement logiciel et pas assez de compétences en data science pourront plus facilement concrétiser de premières initiatives, et passer rapidement à l’échelle.
Nous ne prétendons pas apporter une solution unique dans la mesure où de nombreux paramètres, comme la taille et maturité de l’entreprise, ou les convictions technologiques conditionnent la stratégie à adopter. Pour l’illustrer, on pourrait tout à fait envisager des scénarios plus hybrides qui mixent des squads outillées d’une plateforme et des squads qui développent des produits “from scratch” selon d’autres standards d’architectures. Dans ce cas précis, l’usine de développement de cas d’usage pourrait démultiplier les initiatives, en élargissant la communauté impliquées dans les projets.
Ces plateformes permettent d’augmenter les processus d’intelligence artificielle industrialisées, standardisées, maintenables et accessibles au plus grand nombre de collaborateurs. La démocratisation permet aussi à des profils non-experts de se révéler sur des projets d’intelligence artificielle, à l’instar d’Oyak Cement6, large industriel en cimenterie et grand consommateur d'énergie qui a pu enclencher sa transition vers des énergies alternatives, réduire son empreinte carbone et économiser $39 millions en se reposant sur une équipe de Citizen Data scientists7.
Sources
[1] Adoption de IA, rapport 2021 de McKinsey : https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2021
[2] “85% des projets IA vont échouer” - Gartner : https://www.gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
[3] Introduction de la Squad ML par Google : https://towardsdatascience.com/how-to-hire-a-machine-learning-team-b8055fff57f?gi=4e6768a6bd14
[4] Article de blog Octo sur le concept du “Fail Fast”
https://blog.octo.com/injonction-paradoxale-fail-fast-mais-sans-droit-a-lerreur/
[5] Gartner definit la notion de Citizen Data Scientist : https://www.gartner.com/smarterwithgartner/how-to-use-citizen-data-scientists-to-maximize-your-da-strategy
[6] Présentation de l’initiative IA de Oyak Cement :
https://www.youtube.com/watch?v=awly_QnXtE0&ab_channel=DataRobot
[7] Article de blog octo sur le métier de Citizen Data Scientist : https://www.octo.academy/nous-connaitre/actualites/543/jean-baptiste-larraufie-formation-citizen-data-science/