Comment gérer des grosses données en toute simplicité ? - Compte-rendu du talk de Faustine Massin à la Duck Conf 2022

Faustine Massin est consultante chez OCTO Technology, dans une équipe spécialisée dans la conception et le développement d’applications data-intensives. Elle nous présente un retour d'expérience sur le développement d'une plateforme de traces pour l'Éducation Routière et le Permis de Conduire.
Le cas d'usage étudié porte sur les besoins spécifiques de réquisition judiciaire et de lutte contre la fraude.
Elle présente la démarche qui a été suivie pour dessiner et mettre en place un système capable d'adresser les principaux enjeux métier.
Parmi les différents enjeux, on se concentre ici sur le triptyque :
- scalabilité
- fiabilité
- maintenabilité
Contexte : Remonter le temps lors d'un audit
Connaître l'état actuel n'est pas toujours suffisant. On a parfois besoin de retracer le chemin qui nous y a amené.
C'est le cas ici lors des audits et réquisitions judiciaires, pour lesquels chaque action effectuée sur un dossier doit pouvoir être retracée.
Chaque consultation, création, modification ou suppression d'information d'un conducteur doit être journalisée et centralisée.
Cette pile des événements passés doit être immuable.
On prévoit un volume de 300 millions d'événements par an, soit près d'un million par jour.
Les traces doivent être conservées dans le temps et le système doit être hautement disponible pour garantir de ne pas perdre de traces, sans pénaliser les systèmes en dépendances.
On peut qualifier cette plateforme de data-intensive et on tiendra comptes par la suite de ce contexte particulier à chaque étage de cette plateforme :
- collecte
- stockage
- exposition
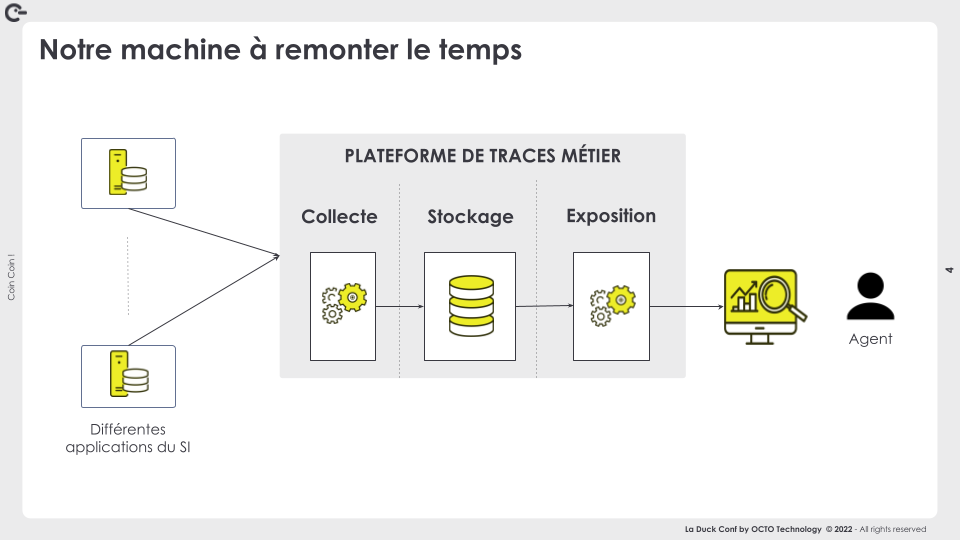
Collecte
Avec un million d'événements journaliers, la tentation est grande de dégainer l'artillerie lourde.
Chaque application du SI est un producteur de messages. Ces traces sont publiées au moment où le système client effectue une opération métier. La sollicitation peut donc varier en fonction de l’activité des utilisateurs. Certaines fonctions métier tiennent compte de la bonne livraison de la trace pour être jugées “valides”.
Un broker de messages devrait nous permettre de gérer un tel débit en faisant office de tampon.Le consommateur dépile les messages à son rythme pour insérer les événements en base.
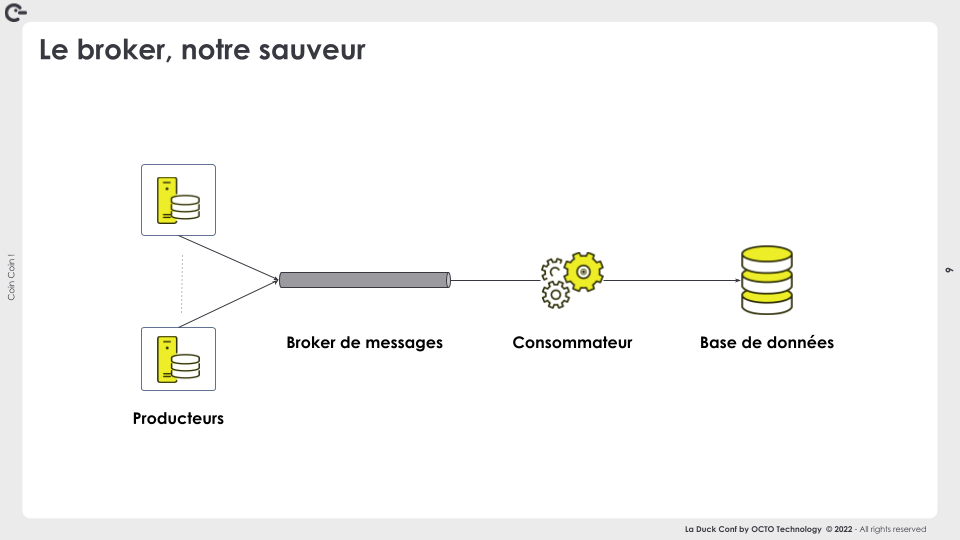
Ce premier niveau nous permet de découpler les besoins de disponibilité entre service de collecte des messages et système de base de données.
Reste cependant à faire le choix de la technologie de notre file de messages.
Une première tentation serait d’utiliser un broker non transactionnel comme Kafka pour leur forte capacité de scalabilité et leur gestion de grandes volumétries.
Avant d’aller plus loin, Faustine nous met en garde contre le “Shiny object syndrome”, qui revient à décider par effet de mode plus que par capacité à répondre à un besoin donné.
Faustine nous présente alors une liste des critères sur lesquels elle s’est basé pour le choix de la file de messages, entre broker transactionnels (type ActiveMQ ou RabbitMQ) en non-transactionnels (type Kafka, Pulsar).
| Scalabilité | - Les brokers non-transactionnels sont plus performants <br>toutefois les broker transactionnels répondent aux exigences de notre cas d’usage (en terme de volumétrie et débit) <br>- Tampon : mise en attente les messages pour éviter d’en perdre si la base n’est pas disponible <br>- Moyen de backpressure pour éviter d’impacter les performances des applications productrices |
| Fiabilité | - On ne peut pas perdre de message et on doit garantir l’intégrité des données transmises <br>- Avantage pour le broker transactionnel : avec la configuration par défaut - Garantie de ne perdre aucun message et de traiter une seule fois chaque message <br>- Tolérance aux pannes : persistance des messages sur disque et redondance du broker |
| Maintenabilité | - Broker transactionnel relativement plus facile à implémenter et administrer au vue des compétences et de la taille de notre équipe d’exploitation <br>- Atout pour aller vite en production <br>et éviter de mettre en place une usine à gaz ! |
Le tout mis dans la balance, on fait le choix d’un broker transactionnel : ActiveMQ
Stockage
Les traces collectées doivent maintenant être stockées dans un système durable qui a lui aussi des challenges particuliers.
A l’initialisation, des traces déjà existantes dans un ancien système doivent être reprises. C'est-à-dire qu’à T0, près de 437 millions de traces sont insérées en base, sans passer par le processus de collecte.
Par la suite, on veut se préparer à recevoir 300 millions de traces par an.
Comme avec le broker de message, on se trouve dans une situation où on voit souvent une orientation vers des technologies “big data” à ce stade.
Notre système de stockage sera soumis au fil du temps à un besoin de scalabilité lié à la forte accumulation des traces dans le système. Il devra supporter ce volume croissant sans pénaliser le bon fonctionnement quotidien.
Dans notre cas, nous avons déjà des bases PostgreSQL présentes dans le SI. On est sur une infrastructure sans services managés et déployer et administrer une nouvelle technologie représente une charge conséquente.
La démarche consiste ici à évaluer si la technologie déjà maîtrisée est suffisante pour supporter notre cas d’usage de piste d’audit. Cette évaluation est une preuve par l’exemple, en soumettant le système PostgreSQL aux charges initiales attendues et aux sollicitations en lecture/écriture attendue.
Ce test en condition initiale reste cependant incomplet sans adresser l’incertitude du maintien de son bon comportement avec l'accroissement des volumes gérés.
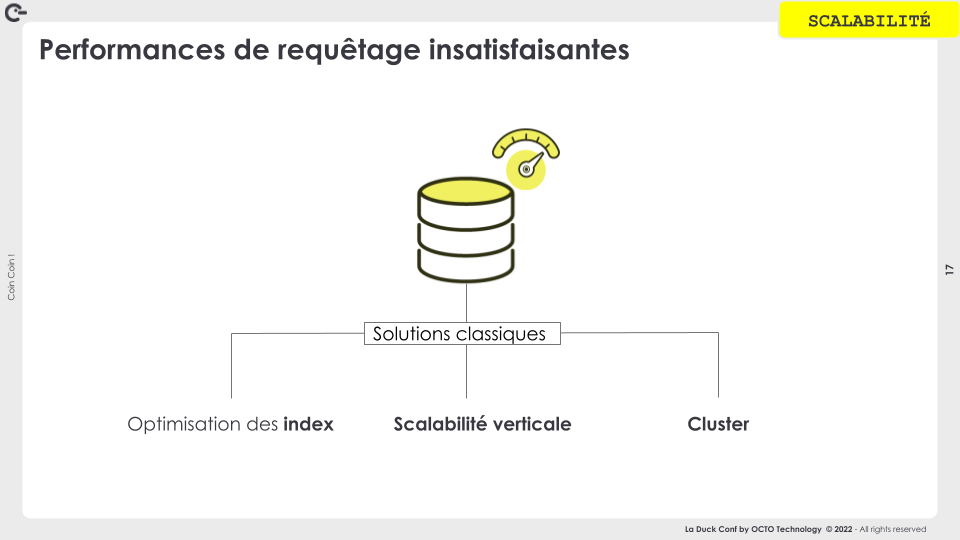
Dans le cas le plus courant, les ajustements de performances passent par de l’optimisation d’indexes, de la scalabilité verticale (ajout de puissance aux machines) ou de la mise en cluster avec des réplicats en lecture pour distribuer la charge de lecture.
Recours au partitionnement
Dans le cas d’une forte rétention (potentiellement toute la durée de vie des conducteurs) l’accumulation de 300 millions de traces par an va conduire à une table énorme et dont l’administration peut devenir problématique après quelques années.
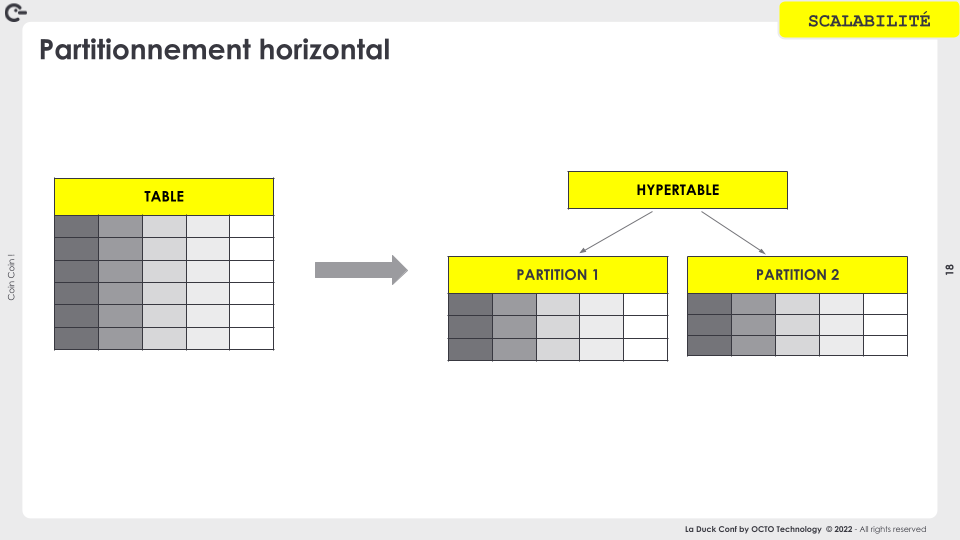
Pour pallier ce manque structurant, Faustine nous présente la capacité de partitionnement de la base, qui permet de maîtriser la taille des objets gérés par la base en la sectionnant par années.
Par principe, cette stratégie semble efficace, mais c’est à condition de pouvoir choisir des critères de partitionnement (ou clé de partitionnement) qui sont à la fois pertinents pour le problème métier (besoin de requêtage) et efficaces pour une distribution équitables des partitions.
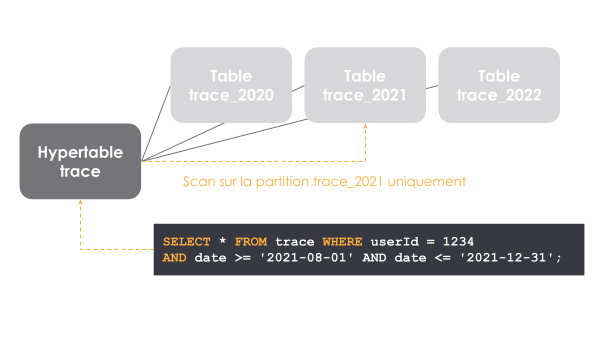
Dans notre cas de piste d’audit, un axe évident pour assurer une répartition équitable est celui du temps.
Avec une partition par année, on s’attend à avoir un volume constant d’environ 300 millions de traces par partitions.
La maîtrise de la taille n’est pas le seul critère. Le principe du partitionnement, pour qu’il reste bénéfique, est d’obtenir des partitions indépendantes. Dans l'idéal, une requête ne devrait solliciter qu’une partition.
Le comportement des utilisateurs sur le système est donc crucial pour déterminer la validité de notre stratégie de partitionnement.
On parle de Design By Query : c’est-à-dire le fait de segmenter en fonction du pattern d’accès aux données.
Le prérequis est donc de bien s’appuyer sur le métier pour comprendre à quelles sollicitations devra répondre le système. L’aide du métier est encore une fois indispensable.
Dans notre cas d’usage, on va requêter les traces, selon différents axes, par plage de dates. On a donc de bonnes chances de solliciter une unique partition (voir 2) dans le cas nominal où la recherche se fait sur une plage plus petite que l’année.
Une indexation pertinente reste indispensable
En combinaison du partitionnement, on continue d’avoir recours à l’indexation. Chaque partition portera alors ses index locaux.
Les index sont définis sur la table parent et hérités par les tables filles. Les opérations d’administration des index ne se complexifient donc pas à mesure que le nombre de partition augmente, il suffit d’administrer l’hypertable.
Cette pause d’index permet (comme souvent) une amélioration significative des performances. Les requêtes sur notre cas d’usage sont 245 fois plus rapides après la pause d’index.
Mise en haute disponibilité
Afin de garantir la meilleure fiabilité du système, on veut qu’il tolère la perte d’une machine avec une interruption minimale du service.
La base est mise en cluster avec un leader qui réplique de manière asynchrone ses données sur le follower.
Ce mécanisme de réplication est implémenté par Postgres, sans avoir recours à des outils tierces. En revanche, on s’appuie sur Patroni pour la promotion automatique du nouveau leader.
La redondance gérée nativement par PostgreSQL et la capacité de Patroni à promouvoir un nouveau leader permet à notre système de stockage de rester hautement disponible.
Notre système de stockage est scalable dans le temps, adapté aux requêtes attendues, hautement disponible. Bref, il est techniquement viable.
Mais que va-t-il contenir dans 10 ans ? Comment lutter contre l’entropie ? Comment ne pas en faire un dépotoir d’informations ?
Sans un questionnement en continu sur la pertinence de conserver telle ou telle information, on risque de tomber dans le réflexe de tout garder “au cas où”.
Ce manque d’hygiène peut induire des coûts de stockage, de requêtage, d’administration non nécessaires. Le RGPD est une contrainte mais aussi un levier utile pour motiver ce questionnement en continu et bien justifier que la conservation sert les besoins de traitements.
Pour correctement identifier les traces pertinentes, on collabore avec les métiers.
A la fois les métiers des applications clientes, qui sont fournisseurs de données à la plateforme, et le métier des auditeurs, qui sont les principaux utilisateurs de la plateforme.
Exposition
Les données collectées et stockées ne portent pas de valeur en elles-mêmes. Elles sont utilisées par des agents de lutte contre la fraude ou pour répondre à des réquisitions judiciaires, il faut donc exposer ses données aux utilisateurs.
Les informations remontées doivent être utilisables, comparables les unes aux autres, peu importe leur provenance.
Plutôt que de gérer des ETL pour harmoniser des données hétérogènes, on repousse les contraintes de gouvernance de la donnée au frontières du système.
Dans notre cas de figure, Faustine nous présente un format pivot qui a été défini comme agnostiques des spécificités métier, et chaque application productrice a la responsabilité de publier ses traces sous ce format pivot.
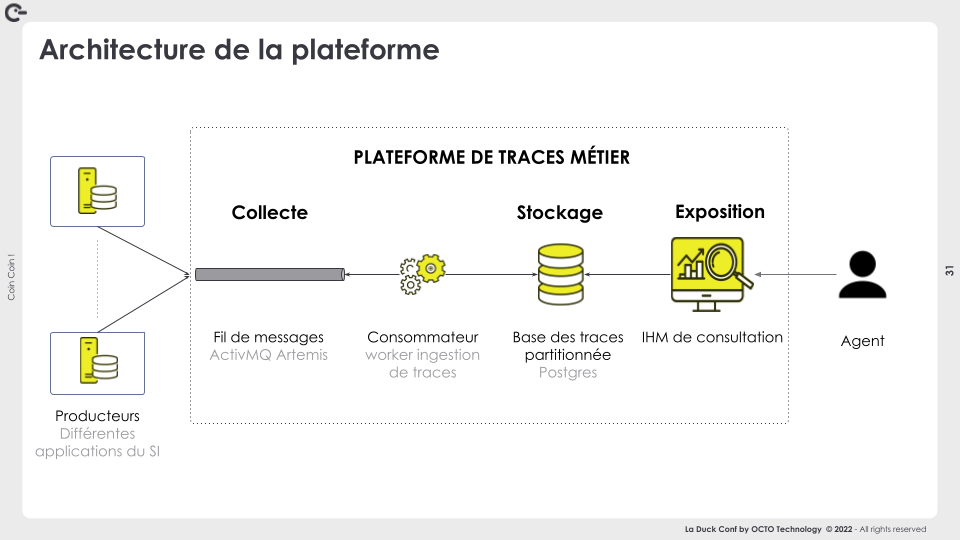
In fine, notre plateforme est implémentée comme suit :
- Un broker de message transactionnelle dans lequel plusieurs client déposent des traces dans un format commun et unique
- des consommateurs sans traitements métier, qui se contentent de dépiler les traces et les insérer en base de données
- un cluster PostgreSQL partitionné par année et hautement disponible
- une interface de consultation qui permet à des agents de requêter les traces selon des schéma d’accès connus et pris en compte dès la conception
Et ensuite ?
Au-delà de la conception, cette plateforme aura une vie en production, qu’on espère longue et heureuse.
Elle a été conçue et implémentée avec pragmatisme, en tenant compte de nos meilleures connaissances à date sur ses enjeux.
Faustine nous met en garde vis-à-vis du besoin de contrôle. Un mauvais réflexe qui nous conduit parfois à chercher des solutions à des “problèmes que l’on a pas encore rencontré”.
Il est important ici ”d’accepter et piloter l’incertitude”.
Les limites du système doivent être identifiées.
Les incertitudes résiduelles doivent être le résultat d’un choix éclairé plutôt qu’un constat d’ignorance. En particulier, nous devons prendre en charge l’évaluation du risque et des impacts de ces choix. C’est la cas ici pour les volumes à stocker, qui dépendent des évolutions fonctionnelles qui pourraient émerger.
Cela implique d’avoir une vision factuelle de la plateforme.
Elle devra donc :
- être correctement testée dans les conditions d’utilisation attendue
- et suffisamment observable pour détecter une variation de ces conditions
Il s’agit de trouver un équilibre entre “ne pas traiter des problèmes qui n’existent pas” et garder la capacité d’anticiper et de répondre à des problèmes futurs.
Take Away
- Réutiliser dès que possible
- Faire simple ...
- ... mais pas simpliste : le système initial est capable de supporter des besoins en production dès le départ