Cold start / Warm start with AWS Lambda
The serverless brings many benefits for the deployment of web applications such as autoscaling, availability and having a very fine granularity on costs (billing per 100ms for AWS lambda). And of course the absence of server management (installations, patches,...). This article makes an inventory of the cold and warm start call metrics with AWS Lambda with different code implementations.
Serverless is an ambiguous term that implies that there are no more servers: this is not the case! The term adapted could have been server[management]less but it would have been less attractive from a marketing point of view.
In reality Serverless encompasses 2 different and overlapping notions:- It is used to describe applications that incorporate many third-party services to manage backend logic and state management. These services are also known as Backend as a Service.
- It can also designate applications where server logic is coded by developers but, unlike traditional architectures, is executed in a stateless, ephemeral container which entirely managed by a third party.
Cold start / warm call with AWS Lambda
To understand what cold start is and how it impacts FaaS code, you need to start by looking at how Function as a Service works. This article will focus on AWS Lambda. Chris Munns' talk at AWS re:invent 2017 gives a good introduction to this topic.
Here are the main steps to execute a Lambda. First, you have to create and configure the Lambda: at this step, the code and configuration to execute a Lambda are simply stored somewhere on s3. Then, during the execution of the lambda, a container is mounted with the resources defined by the configuration and the code to be executed is loaded into memory. What we call “cold start” is the time spent to do this task of Lambda initialization.
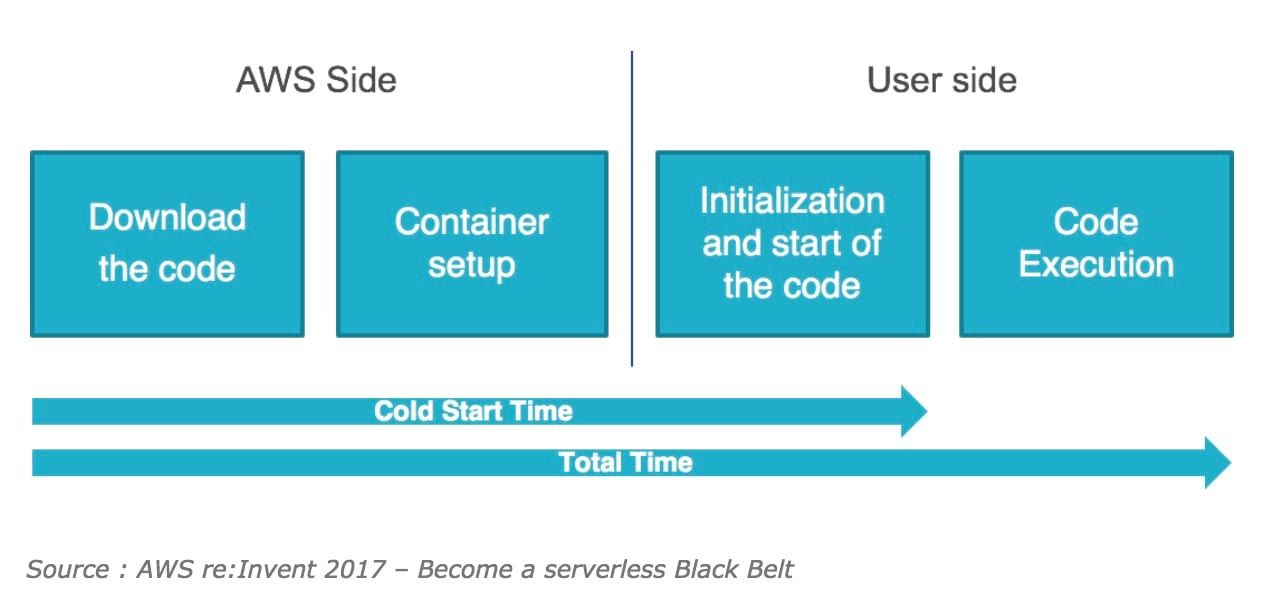
This diagram shows that part of the cold start process is managed by AWS (code loading, container creation). Because of that, the possibilities for a user to optimize the cold start are a bit limited.
The initialization time of a Lambda represents a significant part of the total time. After a cold start, the Lambda will remain instantiated for a while (5 minutes) allowing any other call not to have to wait for this initialization to be done each time. Calls made during this period are called "warm call", which means that the code is loaded into memory and ready to be executed when the Lambda is called one or several times.

Cold start execution has a direct impact on the code execution time of an application. Is this impact significant? Are there ways to minimize it?
Impact of cold start on a basic code
To get an idea of what is the impact of a cold start on the execution time, we did a comparison with 2 really simple Lambdas just returning a "Hello world": one written in Java, the other in NodeJS. The memory resources allocated for each Lambda were 128MB. Here are the results of this test:
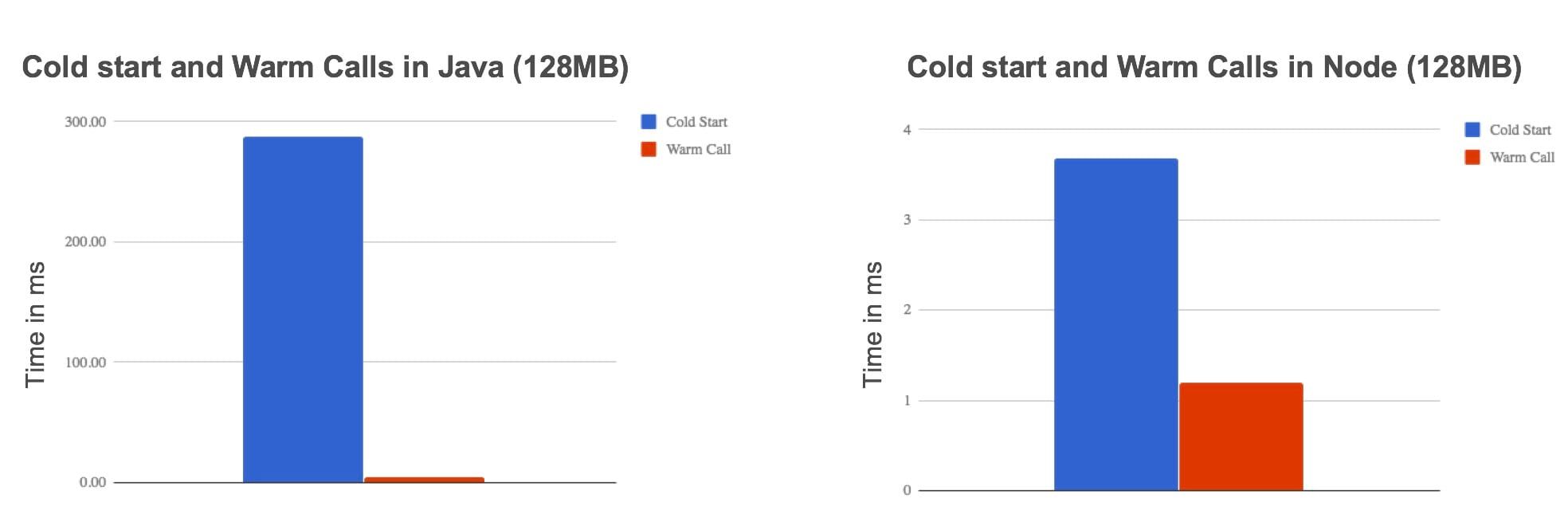
Here are some observations:- First, in both technologies, the cold start increases the execution time of the Lambda.
- Note also that the language used has an impact on the execution time during a cold start. Generally, Java and C# are slower to initialize that Go, Python or Node.
The container mounting part is optimized by AWS and does not appear on these graphs, which suggests that Java is much slower than Node to run a "Hello world". The Java code to be executed is contained in a fat jar, this means that some time is consumed browsing the code in the jar and loading the JVM.
On the other hand, as Yan Cui demonstrated in his article Comparing AWS Lambda Performance, the poor performance of Java and C# languages during the cold start should be readjusted with their good performance during warm calls.
In addition, the size of the resources allocated to the Lambda has also an impact on the execution time. A Lambda could have different memory configuration that can vary from 128 to 3008 MB. On top of that, CPU resources are also to the choice of memory resources, for example, a 256MB Lambda will have 2 times more CPU than a 128MB Lambda. In a very synthetic way, by increasing resources, the execution time should decrease, but this is not so easy to check. In the simple example of the code returning a "hello world", this is true for Java code but it is less obvious for Node code for which there is almost no gain between 512MB and 1024MB.
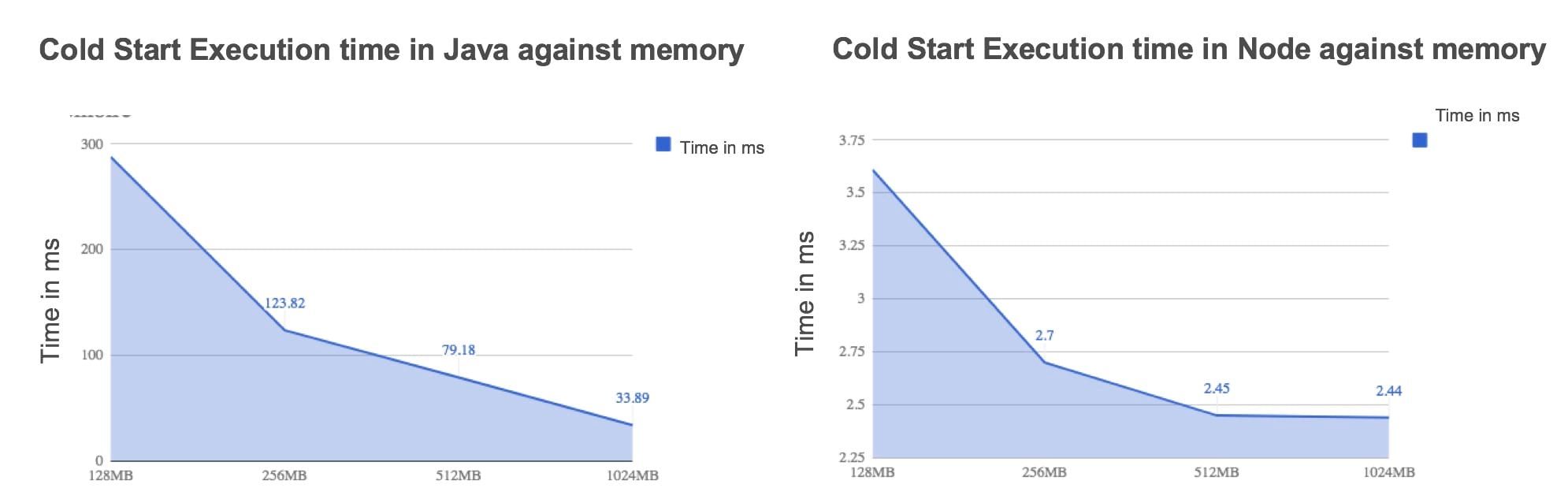
To finish, costs also increase according to resources, which requires a study of the price/time/quality ratio of the service. AWS has put online a tool to estimate the cost of Lambda calls for you to be able to choose the good configuration according to your needs.
Impact of cold start on an application
Measuring a "hello world" code allowed us to get some metrics about the execution time and give us quick wins to try to optimize it. But let’s dig a bit more in this part, running our tests against a more elaborate code.
The code used to make these new measurements is an application that takes in an HTTP request and then reads a database to return the read data from this database in response. The code is available here. Here is a diagram to visualize the application components and their interactions:

This code has been implemented in two different languages: Java and Node, and with different frameworks: springboot, springcloudfunction, express, vanilla (no framework).
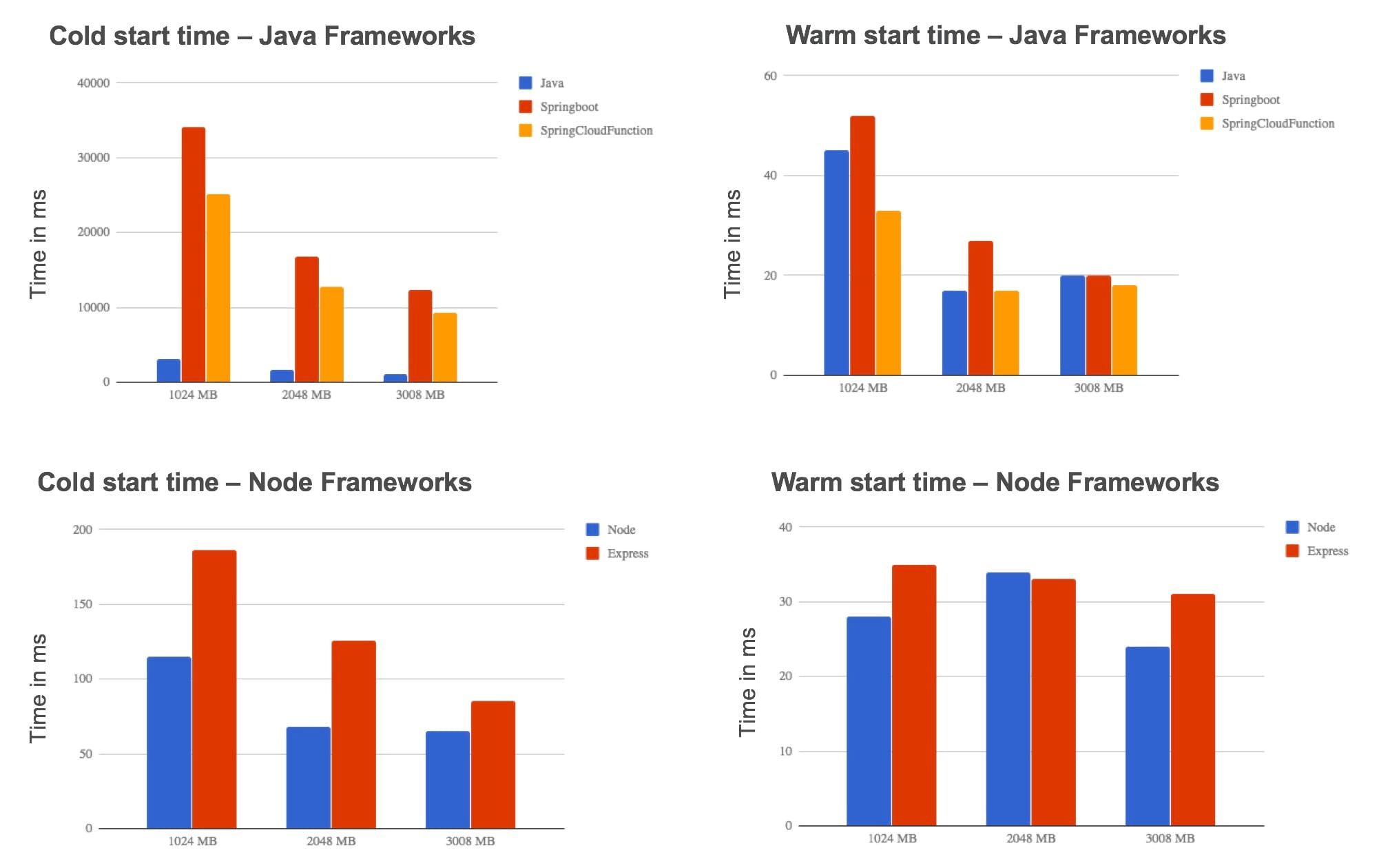
What are the takeaways from those tests?
Adding a framework to structure the code deployed in the Lambda increases the execution time. You can notice a small negative effect using interpreted languages like javascript: 120 ms for Node against 180 ms for Express. For languages like Java, this is another story. The cold start has more impact on Java code and this has repercussions on the use of a framework until it is very penalizing for the user with cold start times greater than 10 seconds. The comparison between different frameworks shows that using a serverless oriented framework like spring cloud function allows reducing the execution time compared to a web framework like springboot.
About warm calls behaviour, the use of a framework has only a non-significant impact on execution time. Measurements show that on average a warm call is executed in 30 milliseconds with small variations of about 10 milliseconds.
Switching from a simple code to a web application results in a significant increase in execution time. The question that may arise is where does this time go? Here are some additional measures to provide answers.

By measuring the initialization time of SpringContext during a cold start and during a warm call, it appears that in the case where SpringContext is started and executed in an already initialized Lambda, the framework starts faster. It is therefore not the framework itself that penalizes the cold start, but rather the initialization of the JVM that is linked to the size of the jar deployed in the Lambda. This also explains the low impact of express in the case of a javascript application.
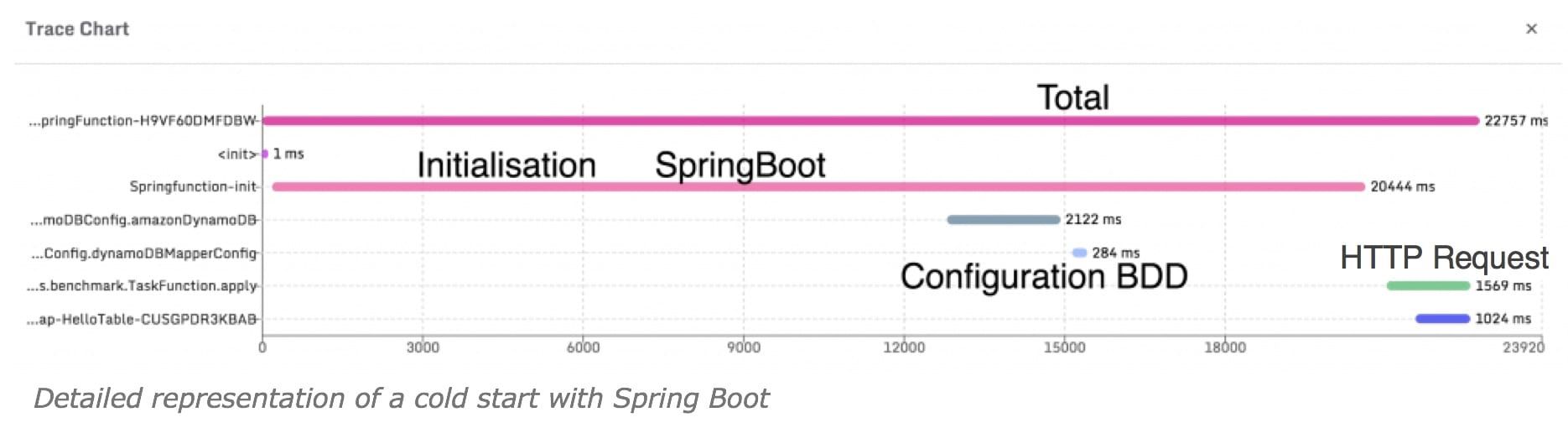
Even if Spring is not slow to run, adding libraries (spring-boot-starter-web, spring-data-dynamo, etc.) makes everything longer to initialize. A possible optimization would be to clean the dependencies to keep only the essential, which is not so easy to do for a developer using spring boot.
After viewing those metrics, a conclusion can be done: cold start should be avoided in an application intended for users, especially when the application is developed in a language such as Java.
Is there a way to keep warm your lambdas
Cold start is a drawback of implementing a serverless application since it induces a waiting time with the first call for the user. A workaround has therefore been implemented in serverless applications to prevent users from suffering too much from cold start, this technique can be called "keep warm" (or "keep alive" depending on the articles). The cold start is due to the fact that the Lambda has a fixed life of 5 minutes, which means that beyond 5 minutes the Lambda is no longer lit. Therefore, after 5 minutes the Lambda must be initialized again.
The principle is simple, try to prevent the Lambda from being unloaded. For that, we could set up a cron which invokes this Lambda at regular intervals so that it remains used from the AWS perspective.
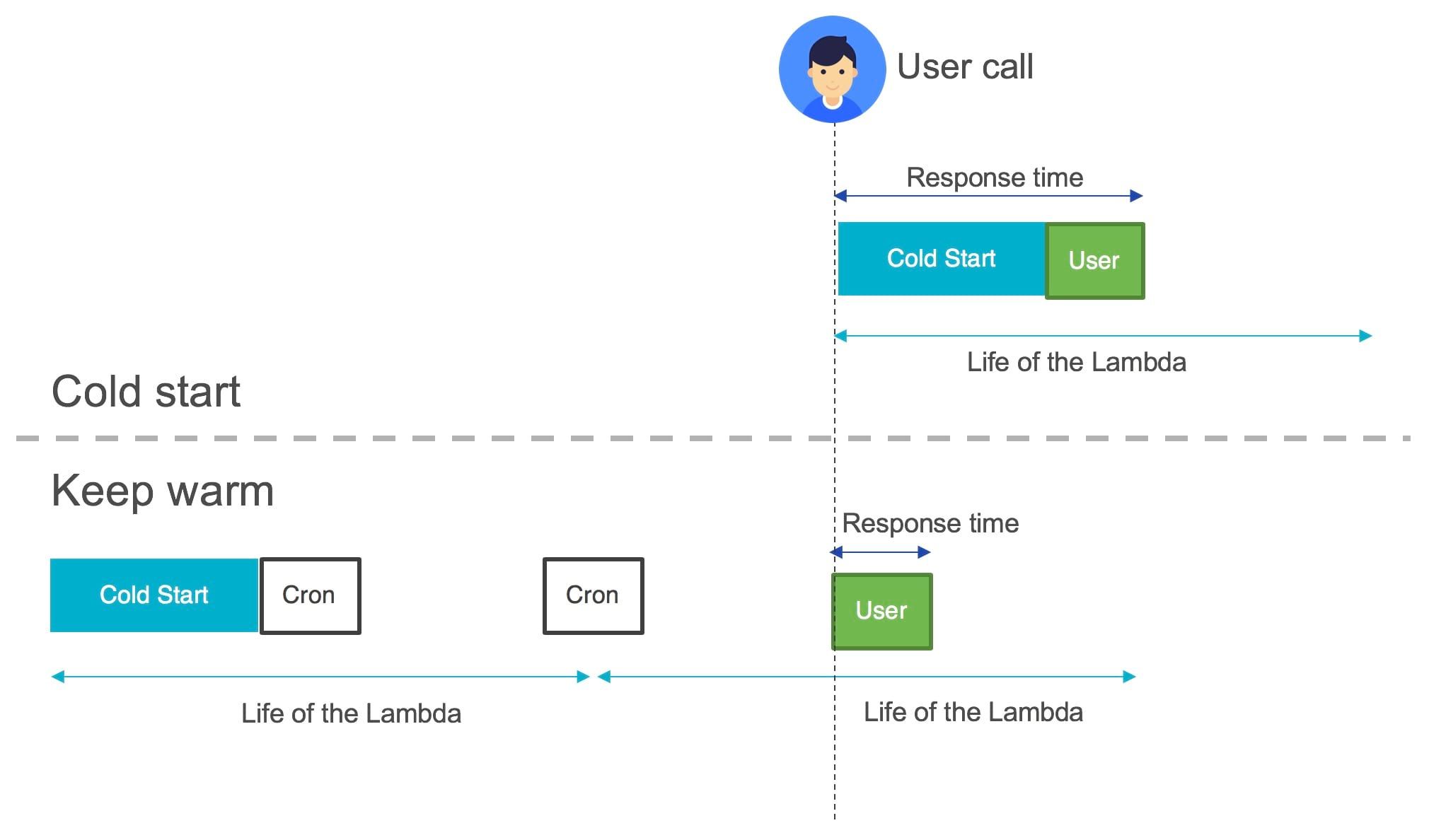
This keep warm technique seems to answer the cold start problem, but some limitations linked to AWS Lambda must be taken into account. The first is that the Lambda will be reset every 4 hours even while doing keep warm. The second is that AWS autoscaling must be taken into account.
Keep-warm and concurrent calls
One of the advantages of developing serverless applications is its automatic autoscaling feature. This means that in case of concurrent calls, the load will be spread over several Lambdas instances. But each new Lambda initialized corresponds to a longer waiting time for the user because of the cold start. Here is a simple example that illustrates the case of concurrent calls (this example does not represent the actual operation of Lambdas autoscaling, but serves to understand its behaviour).
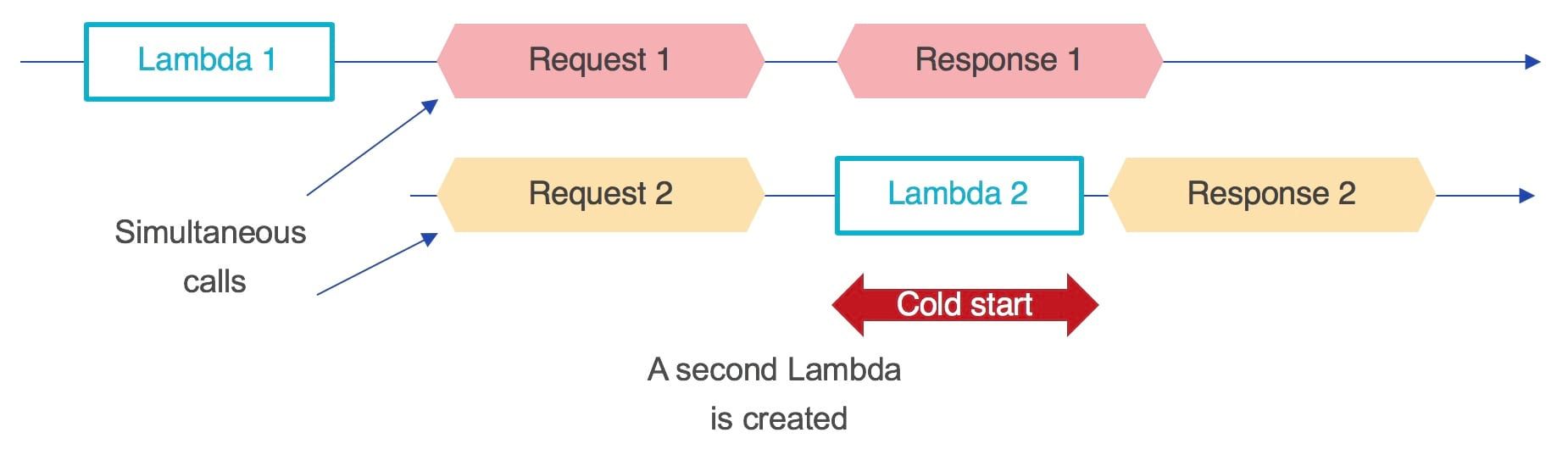
One way to avoid cold starts in case of concurrent calls is to create a pool of Lambdas that are kept warm to be able to handle concurrent calls without the need to have a wait for a new instance of the Lambda to be created. The same example as above with a pool of Lambdas and keep warm gives a predictive response time.
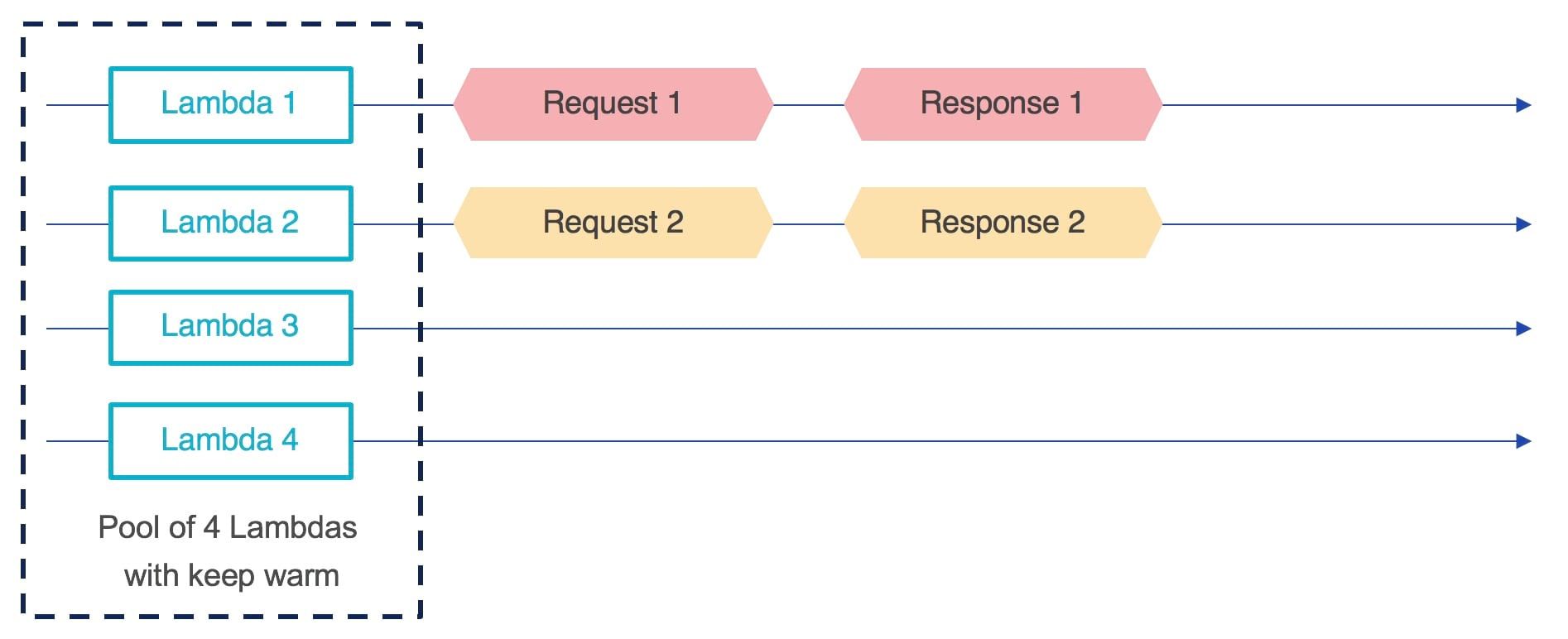
Making pools of Lambdas instances (1 lambda deployed several times) with keep warm mechanism allows to decrease the probabilities for a user to undergo a cold start during concurrent calls. But this technique has a disadvantage, if there are no or few concurrent calls, Lambdas are kept on while they do not perform any treatment. It is necessary to determine the optimal number of Lambda per pool in order not to keep Lambdas on unnecessarily. In addition, this at a cost, keep warm consisting of making calls on a Lambda at regular intervals, each call will be charged. In the case of a pool, the costs are multiplied by the number of Lambdas that constitute it.
But it stays negligible comparing to the price of other infrastructures such as EC2 or Fargate containers. The following graph shows that for a small application (with less than 5 million requests per month) the use of Lambda remains advantageous. Don’t forget that pool of Lambda is not a feature provided by an AWS, you will need to put in place some tricks to be able to try to keep a pool warm without really knowing how many instances are deployed.
Serverless frameworks and monitoring tools
The keep warm mechanism appeared as a bypass to keep Lambdas on by triggering events with another Lambda. This requires creating another Lambda that will be in charge of making these calls or creating a CloudWatch event for each Lambda to keep on. Since the beginning of this technique, the frameworks and tools around the serverless have proposed their own way to implement keep warm so that it requires little configuration and code to write to set it up.
For example, thundra.io which is a monitoring tool for AWS Lambda allows to have metrics and tracing on deployed Lambdas. It also has a keep warm feature to limit the number of cold start in a serverless web application. Thundra is not the only tool/framework that allows implementing keep warm, it also exists with serverless and Zappa. As described in this article, keep warm is not intended to avoid all cold starts but to minimize its impact in the case of a web serverless application. Thundra's approach to keep-warm requires playing on 2 parameters that are: the number of Lambda in the Lambda pool in keep-warm and the time lapse between calls to keep the functions on. But as said previously, you have no way to control very precisely the number of deployed instances of your Lambda, you just try to keep several instances warm without a good control on how they are really deployed.
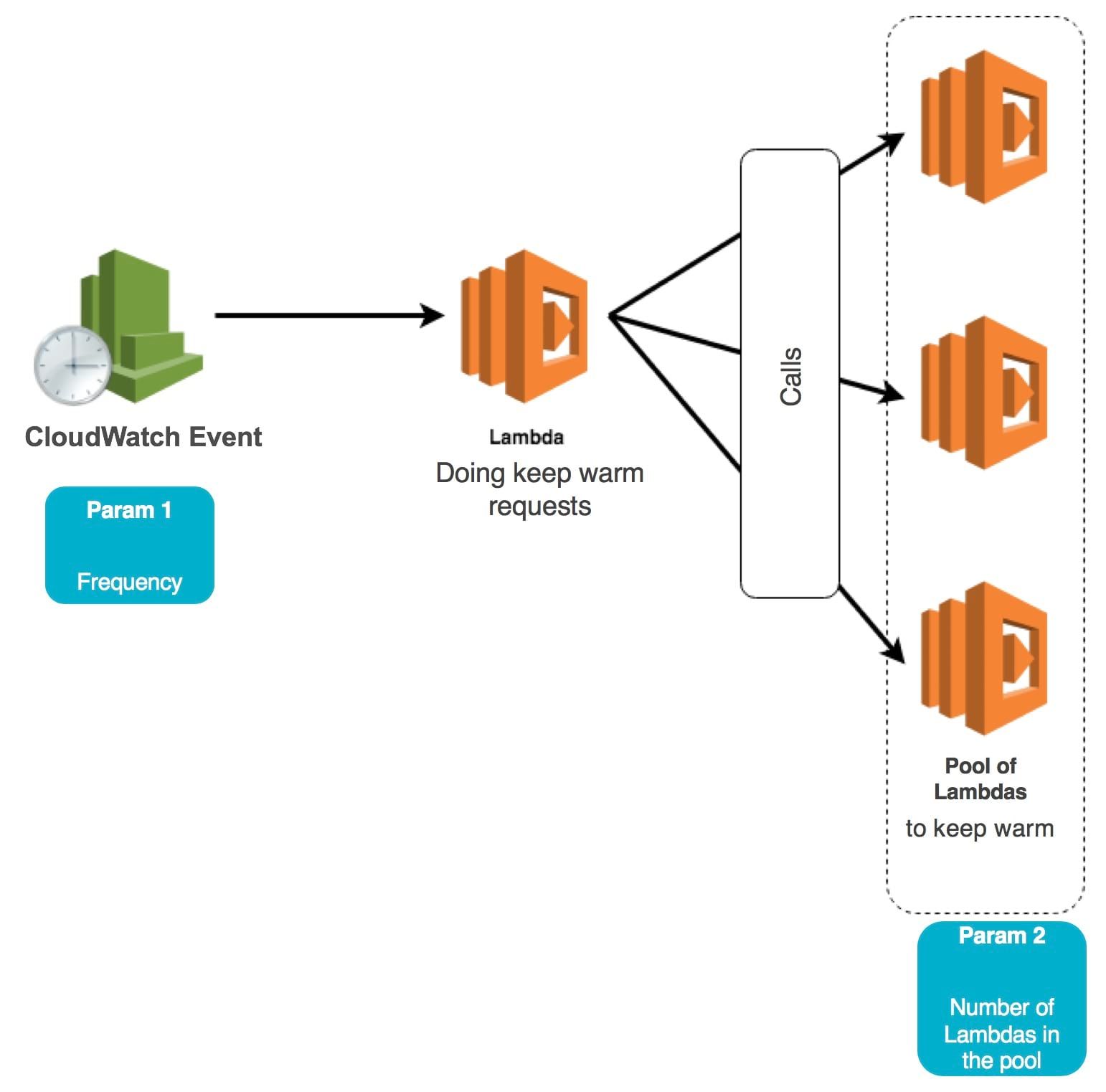
By default, Thundra will try to create a pool of 8 Lambdas and send an event every 5 minutes to try to keep the pool warm.
To create a lambda pool and make sure to keep them on, the Lambda in charge of keeping warm must make calls to the target Lambdas. The Lambda code in the pool must handle keep warm requests differently. In this case, the code triggers a sleep so that the Lambda appears busy and the next request is sent to another lambda in the pool. By retrieving the id of each Lambda, it is possible to ensure that all Lambdas in the pool are kept on.
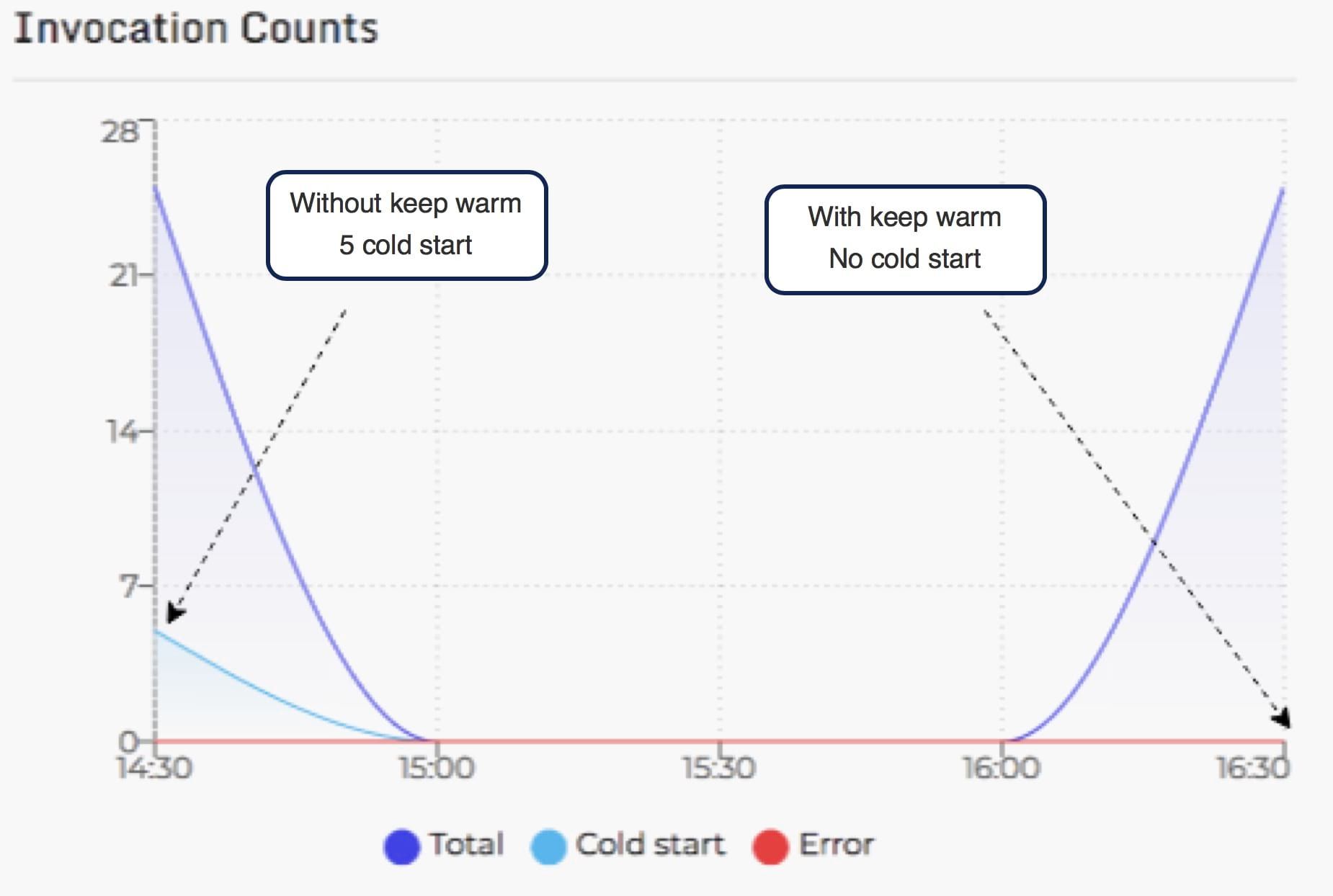
With this configuration, on 5 concurrent calls of 5 requests, Thundra records 5 cold starts while with keep-warm the Lambdas do not suffer it.
Here are the details of the invocations with and without cold start using this technique and Thundra tool.
Finally, cold-start has an important impact on serverless applications for users. Cold-start can be minimized thanks to the keep warm technique but it still requires efforts from developers to optimize this technique. The tools increasingly integrate the implementation of keep-warm in an automated way.
By writing this blog post, those solutions are more workaround than a real solution. Nothing is really mature around pools of lambdas. On the other hand, the ecosystem is growing very fast, there are new tools every day or so to help you working with Lambda. So we could expect more sustainable solutions in a very soon future.
To conclude, and as a personal note, if you need a fixed size of instances of lambda as we just described, it might be more interesting to take a look at other runtimes especially if you already have many users. If you use Kubernetes for example (managed by cloud providers or not), you will be able to fine-tune the autoscaling mechanism to have a minimum/maximum of containers of a same deployed code, configure your CPU and memory resources...
References: Articles:
- https://martinfowler.com/articles/serverless.html
- https://read.iopipe.com/understanding-aws-lambda-coldstarts-49350662ab9e
- https://theburningmonk.com/2017/06/aws-lambda-compare-coldstart-time-with-different-languages-memory-and-code-sizes/
- https://medium.com/thundra/dealing-with-cold-starts-in-aws-lambda-a5e3aa8f532
- https://read.acloud.guru/comparing-aws-lambda-performance-when-using-node-js-java-c-or-python-281bef2c740f
- https://blog.symphonia.io/the-occasional-chaos-of-aws-lambda-runtime-performance-880773620a7e
Videos: