Classification d’images : les réseaux de neurones convolutifs en toute simplicité
Vous souhaitez créer une IA capable de classifier des images ?
- Qu’elle reconnaisse Pikachu sur Pokemon Go ?
- Qu’elle automatise des opérations répétitives comme le tri de légumes ?
- Voire qu’elle réalise des tâches expertes comme un diagnostic de la rétinopathie diabétique ?
Les réseaux de neurones convolutifs sont l’outil de choix dans la besace du Data Scientist pour ce type de problèmes. Ce sont des algorithmes phares du Deep Learning, objets d’intenses recherches… dont la richesse peut impressionner.
Il est pourtant possible de créer très simplement des modèles performants : avec peu d'images, peu de capacités de calcul et sans maîtrise des arcanes algorithmiques. Toute l’astuce consiste à réutiliser des réseaux pré-entraînés sur d’autres problèmes, par des techniques de transfer learning. La librairie open-source Keras permet de coder cela en quelques lignes, avec une API claire et de haut niveau.
Ce guide prend pour exemple la récente compétition Kaggle StateFarm, une excellente arène pour développer vos capacités de dresseurs d’algorithmes. Nous introduisons deux techniques de transfer learning qui donnent d’excellents résultats. Puis nous traversons ensemble les couches techniques mises en oeuvre, pour déjouer les embûches théoriques et pratiques que vous pourriez rencontrer.
1 - La compétition Kaggle StateFarm
La distraction des conducteurs au volant est une cause majeure d’accidents de la route. Le groupe d’assurance américain StateFarm vise à améliorer son offre, en testant si une simple caméra permet de détecter les conducteurs distraits. Il propose une compétition Kaggle dont l’objectif est de classifier automatiquement des images de conducteurs, en 10 catégories de comportement telles que « conduite prudente », « téléphone avec la main droite » ou bien « maquillage ».

Ces images ont été annotées lors de leur acquisition. Kaggle fournit les annotations d’une partie des images (jeu d'entraînement) et les garde secrètes pour le reste (jeu de test). Notre rôle est d’entraîner un modèle de machine learning sur le jeu d’entraînement, puis d’utiliser ce modèle pour prédire les comportements sur les images de test. Ces prédictions sont alors soumises à Kaggle pour l’évaluation de la performance du modèle.
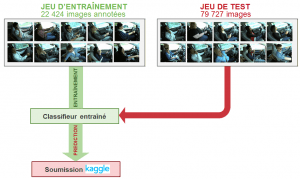
Grâce aux modèles présentés dans cet article, nous atteignons des précisions de 99% en validation croisée sur le jeu d'entraînement, et un logloss* de 0.37 sur le leaderboard Kaggle.
* La précision est un score binaire d’adéquation entre une catégorie prédite et la réalité. Le logloss prend en compte l'incertitude sur les prédictions, décrite par une distribution de probabilité sur les catégories. C’est le score utilisé dans cette compétition Kaggle.
2 - Quelques explications sur les CNN
L’architecture d'un CNN comporte 2 parties
Les réseaux de neurones convolutifs sont à ce jour les modèles les plus performants pour classer des images. Désignés par l’acronyme CNN, de l’anglais Convolutional Neural Network, ils comportent deux parties bien distinctes. En entrée, une image est fournie sous la forme d’une matrice de pixels. Elle a 2 dimensions pour une image en niveaux de gris. La couleur est représentée par une troisième dimension, de profondeur 3 pour représenter les couleurs fondamentales [Rouge, Vert, Bleu].
La première partie d’un CNN est la partie convolutive à proprement parler. Elle fonctionne comme un extracteur de caractéristiques des images. Une image est passée à travers une succession de filtres, ou noyaux de convolution, créant de nouvelles images appelées cartes de convolutions. Certains filtres intermédiaires réduisent la résolution de l’image par une opération de maximum local. Au final, les cartes de convolutions sont mises à plat et concaténées en un vecteur de caractéristiques, appelé code CNN.
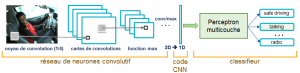
Ce code CNN en sortie de la partie convolutive est ensuite branché en entrée d’une deuxième partie, constituée de couches entièrement connectées (perceptron multicouche). Le rôle de cette partie est de combiner les caractéristiques du code CNN pour classer l’image.
La sortie est une dernière couche comportant un neurone par catégorie. Les valeurs numériques obtenues sont généralement normalisées entre 0 et 1, de somme 1, pour produire une distribution de probabilité sur les catégories.
L’entraînement d’un nouveau CNN est difficile
Créer un nouveau réseau de neurones convolutif est coûteux en terme d’expertise, de matériel et de quantité de données annotées nécessaires.
Il s’agit d’abord de fixer l’architecture du réseau, c’est-à-dire le nombre de couches, leurs tailles et les opérations matricielles qui les connectent. L’entraînement consiste alors à optimiser les coefficients du réseau pour minimiser l’erreur de classification en sortie. Cet entraînement peut prendre plusieurs semaines pour les meilleurs CNN, avec de nombreux GPU travaillant sur des centaines de milliers d’images annotées.
Des équipes de recherche se spécialisent dans l’amélioration des CNN. Elles publient leurs innovations techniques, ainsi que le détail des réseaux entraînés sur des bases de données de références. Le challenge ImageNet (ILSVRC) fournit par exemple 1.2 millions d’images classées en 1000 catégories. Ces CNN entraînés sont disponibles nativement dans la librairie Keras, ou sont regroupés dans des dépôts github pour d’autres librairies (par exemple ModelZoo pour Caffe).
3 - Transfert learning : Adapter des CNN pré-entraînés
Pour des usages pratiques, il est possible d’exploiter la puissance des CNN sans être un expert du domaine, avec du matériel accessible et une quantité raisonnable de données annotées. Toute la complexité de création de CNN peut être évitée en adaptant des réseaux pré-entraînés disponibles publiquement. Ces techniques sont appelées transfert learning, car on exploite la connaissance acquise sur un problème de classification général pour l’appliquer de nouveau à un problème particulier.
Les expériences présentées dans cet article ont été réalisées en partant du classique VGG-16. La “connaissance” sur la classification d’images contenue dans un tel réseau peut-être exploitée de deux façons :
- comme un extracteur automatique de caractéristiques des images, matérialisé par le code CNN,
- comme une initialisation du modèle, qui est ensuite ré-entraîné plus finement (Fine Tuning) pour traiter le nouveau problème de classification.
La première méthode fournit simplement un très bon modèle. Nous classifions correctement 98% des images de conducteurs. Le fine tuning demande un investissement un peu plus important, et permet d’améliorer la performance finale : 99% de précision sur notre problème.
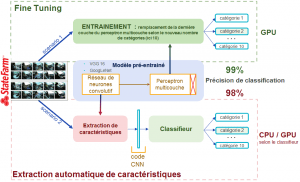
Extraction automatique de caractéristiques
L’extraction automatique de caractéristiques exploite uniquement la partie convolutive d’un réseau pré-entraîné. Elle l’utilise comme extracteur de caractéristiques des images, pour alimenter le classifieur de votre choix.
En pratique, le VGG 16 est tronqué pour ne garder que la partie convolutive. Cette partie est dite gelée, pour exprimer l’absence d'entraînement. Ce réseau prend en entrée une image au bon format* et produit en sortie le code CNN. Chaque image du dataset est ainsi transformée en un vecteur de caractéristiques, qui est utilisé pour entraîner un nouveau classifieur. Nous avons choisi comme classifieur la librairie de gradient boosting XGBoost. Cette librairie est un excellent choix par défaut : tuning léger, parallélisation efficace, API pratique et performance remarquable. Elle intervient dans les solutions gagnantes de la majorité des compétitions Kaggle.
* Il n'est pas nécessaire de remettre à l'échelle les images si l'on n'utilise que la partie convolutive d'un CNN : les noyaux de convolutions sont définies indépendamment de la taille des images. Attention en revanche à l’ordre des canaux de couleurs RGB.
Cette méthode présente de nombreux intérêts pratiques.
- Tout d’abord, l’image est transformée en un vecteur de petite dimension, qui extrait des caractéristiques (features) généralement très pertinentes. Cela réduit la dimension du problème, en remplacement de méthodes de traitement d’images classiques mais sophistiquées. À noter que cela fonctionne d’autant mieux si l’on travaille sur un problème “proche” du problème initial sur lequel le réseau a été entraîné. Lorsque le problème est très similaire, par exemple pour de la classification d’objets sur des images centrées, il possible de réduire encore la dimension du problème en conservant une partie du perceptron multicouche de VGG 16.
- De plus, le data scientist a la liberté d’employer le classifieur final de son choix, en fonction de son expérience ou des contraintes de production. L’utilisation de librairies comme XGBoost permet d’obtenir d’excellentes performances en peu de temps.
- Enfin, l’extraction de caractéristiques n’étant réalisée qu’une fois par image, elle peut être effectuée rapidement sur CPU. Les librairies de machine learning sont généralement séquentielles et tournent également sur CPU. Cette méthode permet donc d’exploiter la puissance des CNN sans investir dans des GPU.
Fine Tuning
Le Fine Tuning consiste à se servir d’un modèle pré-entraîné comme initialisation pour l’entraînement sur un nouveau problème. L'intérêt est double : on utilise une architecture optimisée avec soin par des spécialistes, et l’on profite des capacités d’extraction de caractéristiques apprises sur un jeu de données de qualité. Le Fine Tuning sur des images consiste en quelques sortes à prendre un système visuel déjà bien entraîné sur une tâche de classification pour le raffiner sur une tâche similaire.
La seule modification nécessaire du réseau consiste à adapter la dernière couche. Notre problème comporte 10 catégories, tandis que l'entraînement initial du VGG 16 s’est fait sur 1000 catégories. Il faut donc remplacer la 16ème (dernière) couche de VGG 16 par une couche à 10 neurones. Cela peut fortement modifier les ratios de tailles entre couches successives, qui correspondent à des réductions de dimension de l’information. Il est envisageable d’ajouter une couche intermédiaire avant la sortie, ou de modifier la taille des couches préalables.
Pour l’entraînement, il est possible de geler les couches initiales du réseau de neurones, et de n’adapter que les couches finales pour le nouveau problème de classification. Geler toutes les couches convolutives correspond à la première méthode présentée, avec comme classifieur final un perceptron multicouche pré-initialisé. Les principes généraux d’entraînement des CNN présentés en fin d’article s’appliquent au Fine Tuning. Cependant, un point spécifique est l’utilisation de taux d’apprentissage faibles*, de l’ordre de 10^-3.
* Le réseau pré-entraîné possède déjà des coefficients optimisés avec soin sur un grand jeu de données. Il s’agit de les modifier faiblement à chaque itération, pour s’adapter en douceur au nouveau problème, sans écraser agressivement la connaissance déjà acquise.
4 - Compléments sur la pile technique employée
Dans les paragraphes suivants, nous parcourons et expliquons la pile technique mise en oeuvre pour utiliser les réseaux de neurones convolutifs. Du matériel aux astuces d’algorithmie, en passant par les librairies nécessaires à chaque niveau.
Le GPU
De l’anglais Graphics Processing Units, les GPU sont les processeurs adaptés pour entraîner des réseaux de neurones. Initialement développés pour les opérations graphiques, NVIDIA a lancé en 2007 des GPU destinés à des calculs plus génériques. Ces GPU accélèrent les portions de code intensives en calculs parallélisables, les portions séquentielles restantes étant traitées par les CPU. Les réseaux de neurones nécessitent de nombreuses opération matricielles, qui sont accélérées d’un facteur dix lorsqu’elles sont distribuées sur les milliers de cœurs de GPU.
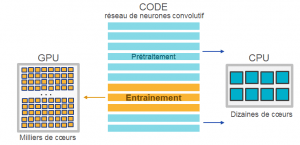
Lors de la compétition Kaggle, nous avons utilisé la carte graphique de NVIDIA GeForce GTX Titan Black. Elle se situe dans le milieu de gamme des GPU et possède 2880 coeurs. Une autre possibilité est d’utiliser des GPU loués à l’heure dans le cloud, par exemple sur Amazon Web Service. Une équation économique rapide montre que l’achat de la carte GPU citée est amortie au-delà de 70 fois 24h d’entraînements avec AWS. Avant de trop se préoccuper des GPU, nous vous recommandons d’expérimenter la première technique de transfert learning présentée. Elle ne nécessite pas de réentraîner de réseaux, et vous pourrez utiliser des algorithmes standards de machine learning fonctionnants sur CPU.
Les librairies Deep Learning
L’écosystème Deep Learning comprend de nombreuses librairies.

La première couche bas niveau est celle permettant d’utiliser une carte graphique. Ces GPU sont généralement de marque NVIDIA, qui domine le marché. On utilise alors sa librairie CUDA dédiée, éprouvée par la communauté. À celle-là s’ajoute la librairie CuDNN qui accélère les procédures des réseaux de neurones.
Au-dessus se situent les librairies de Deep Learning. Ces librairies permettent de définir le graphe symbolique d’opérations décrivant le réseau de neurones, et rendent transparente la parallélisation. TensorFlow a été initiée par Google et propose aussi des algorithmes en dehors du Deep Learning. Torch est utilisé par Facebook et Twitter et se distingue par son environnement en langage Lua. Theano, considéré comme le grand-père des librairies Deep Learning, est un wrappeur Python proposant un environnement de machine learning. Il permet la création de librairies haut niveau telles que Lasagne et Keras.
Keras est une librairie de haut niveau, permettant de manipuler des réseaux de neurones en quelques lignes de code. Elle est accompagnée d’une documentation et de tutoriels de grandes qualités. Initialement développée au-dessus de Theano, le backend TensorFlow est désormais supporté et utilisé par défaut. Étant une librairie de haut niveau, la limitation de Keras est qu’elle ne permet pas d’innover sur les détails d’entraînement des réseaux de neurones.
Que vous soyez débutant à la recherche d'une API simple ou un expert qui souhaite prototyper rapidement des expériences, Keras est un excellent choix !
Entraînement des CNN, quelques principes
L’entraînement d’un CNN consiste alors à optimiser les coefficients du réseau, à partir d’une initialisation aléatoire, pour minimiser l’erreur de classification en sortie. Les deux parties des CNN sont entraînées simultanément : on apprend à la fois les coefficients des noyaux de convolutions pour extraire des caractéristiques pertinentes, et la bonne combinaison de ces caractéristiques.
En pratique, les coefficients du réseaux sont modifiés de façon à corriger les erreurs de classification rencontrées, selon une méthode de descente de gradient. Ces gradients sont rétropropagés dans le réseau depuis la couche de sortie, d’où le nom rétropropagation du gradient (backpropagation en anglais) donné aux algorithmes d’entraînement des réseaux de neurones.
L'entraînement par batch consiste à rétropropager l’erreur de classification par groupes d’images. Cette méthode est plus rapide qu’en calculant l’erreur sur tout le jeu d’entraînement à chaque itération. Elle est plus stable qu’en travaillant image par image, car les gradients d’erreurs ont moins de variance. À noter qu’un nombre trop important d’images par batch peut engendrer des problèmes de mémoire lors de l’exécution du code.
La compréhension fine des algorithmes de backpropagation n’est pas nécessaire pour un utilisateur final. Ils diffèrent essentiellement par leur politique concernant la vitesse d’apprentissage, c’est-à-dire l’amplitude de modification des coefficients à chaque itération. Cet article d’Andrew Karpathy propose par défaut Adadelta, peu sensible au choix de la vitesse d’apprentissage initial, ou SGD with Momentum.
Enfin, sans tenter un catalogue exhaustif des astuces d’entraînement, le principe de Batch Normalization pourra vous être utile en Fine Tuning. Cette technique peut améliorer fortement la convergence lors de l’entraînement. Elle consiste à normaliser en moyenne et en variance les sorties des couches du réseau. Dans Keras, il suffit d’ajouter des couches de Batch Normalization intermédiaires pour l’appliquer.
5 - Conclusion
Vous voilà maintenant en mesure de repérer un Pikachu distrait au volant d’une pokemobile !

A travers la compétition Kaggle StateFarm, les réseaux de neurones convolutifs démontrent à nouveau leurs performances. L’utilisation de réseaux pré-entraînés aboutit à de très bons résultats : rapides en s’en servant comme extracteur de caractéristiques d’images, meilleurs en les réentraînant spécifiquement (Fine Tuning). L’extraction de caractéristiques constitue une excellente approche initiale, avec un très bon compromis performance - complexité - coût.
À la source des CNN pré-entraînés se trouve des jeux d’images publics. Google Research vient de publier Open Images Dataset, comprenant 9 millions d’images annotées dans 6000 catégories. C’est respectivement 7,5 et 6 fois plus que ImageNet : les prochains CNN de références, entraînés sur Open Images Dataset, promettent d’être encore plus performants et généralistes.
Les perspectives pour aller plus loin sont multiples. Il est parfois avantageux de pré-traiter les images, en les recadrant ou en normalisant leurs histogrammes de couleur. On peut également compléter les modèles par des approches classiques de création de features, spécifiques au problème en jeu. Enfin, si l’on dispose de temps, de GPU et de données conséquentes, l'entraînement de bout en bout de CNN offre des perspectives d’améliorations. Cela vous fera progresser dans la compréhension des CNN et vous stimulera pour leur trouver de nouveaux usages.
Références
- Le blog d’Andrej Karpathy est l’une des meilleures sources pour comprendre les réseaux de neurones : convolutional-networks, transfert-learning.
- La documentation de Keras est une mine d’or pour utiliser pratiquement les réseaux de neurones. Cet article de blog en particulier propose des codes détaillés pour mettre en oeuvre les méthodes de Transfert Learning présentées ici.
- Pour l’histoire, l’article précurseur dans la classification d’images, initialement de digits, par Kunihiko Fukushima : Neocognitron, A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. In Biol, Cybernetics, 1980.
ANNEXE
Combien d’images d'entraînement pour une bonne performance ?
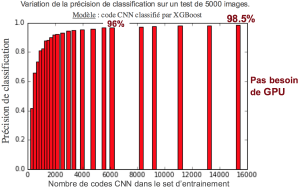
Le jeu d’entraînement fourni par Kaggle comporte ~22500 images, annotées dans 10 catégories. Dans l'expérience suivante, on entraîne un classifieur XGBoost à partir des codes CNN de VGG 16 sur des échantillons d’entraînement de taille croissante. On observe que la précision augmente très rapidement ! À partir de 1000 images, soit 100 par catégorie, nous obtenons des performances de classification de 90%. On atteint une précision de 96% avec 6000 images, et finalement 98,5% avec l’ensembles des données d’entraînement (moins celles utilisées pour cross-valider). Il est donc possible d’entraîner un classifieur performant avec peu d’images.
À noter qu’il est possible de mettre en oeuvre des techniques d’augmentation du jeu d’entraînement s’il est vraiment trop réduit. Il s’agit de créer des variations d’une même image par de légères transformations : rotation, translation, etc.
Création de features spécifiques
Une erreur fréquente de nos modèles concerne les catégories Safe Driving et Talking : des conducteurs prudents regardant à droite sont confondus avec des conducteurs discutant avec le passager. Une observation des images indique que la présence d’un sourire sur le visage du conducteur plaide en la faveur de la catégorie Talking. Une piste d’amélioration du modèle serait de lui fournir cette information, par exemple en utilisant au préalable un module de reconnaissance d’émotions. A titre de comparaison, une autre compétition Kaggle sur la classification d'espèces de baleines a été remportée grâce à un ciblage d’une zone discriminante chez la baleine.
Ces features spécifiques peuvent être concaténées au code CNN si l’on utilise un classifieur comme XGBoost. Si l’on utilise un CNN complet (Fine Tuning), il est possible d’utiliser une technique de stacking pour combiner ces features aux sorties du CNN.
