Répondre aux défis architecturaux : Gestion des dépendances et circuit breaker
L'évolution des besoins (réductions des coûts et du time to market, concept d'ATAWAD (AnyTime, AnyWhere, AnyDevice)...) a mis en avant certaines architectures (architecture applicative cloud ready, architecture microservices, architecture distribuée…).
Cela a engendré de nouvelles problématiques, en particulier l’augmentation du nombre de dépendances et donc potentiellement soumise au réseau.
C’est à ce moment qu'apparaissent à nouveau les “Illusions de l'informatique distribuée” :
- Le réseau est fiable.
- Le temps de latence est nul.
- La bande passante est infinie.
- Le réseau est sûr.
- La topologie du réseau ne change pas.
- Il y a un et un seul administrateur réseau.
- Le coût de transport est nul.
- Le réseau est homogène.
Et ces illusions ne prennent pas en compte la partie dépendance et leurs lots de problèmes (crash, temps de réponse lent, réponse non conforme…).
Pour répondre à ces défis, la philosophie de design for failure (les traitements applicatifs doivent, dès leur conception, prévoir le cas où les composants qu’ils appellent pourraient tomber en erreur) a pris encore plus d’importance.
Et donc nous sommes passés de « prévenir toutes les défaillances » à « les défaillances font partie du jeu ».
Parmi toutes les solutions composant le design for failure, nous allons nous pencher sur le design pattern “Circuit Breaker” popularisé par Michael Nygard dans le livre “Release It!”.
Mais avant cela, faisons un tour rapide sur d’autres solutions permettant de gérer des problèmes de dépendances.
Et pourquoi ne pas utiliser la solution XXX à la place ?
Le problème que nous voulons résoudre est la gestion des dépendances (externe ou interne) qui peuvent (et le seront tôt ou tard) défaillantes lors de l’exécution de notre application.
Par exemple lorsqu’une application appelle le service de paiement, que faire lorsque celui-ci n’est pas accessible ?
Comme pour toutes les difficultés, plusieurs solutions sont possibles. En voici quelques-unes.
Migration dans le cloud avec du lift and shift (aussi appelé fork and lift)
Une solution simple est de se dire qu’il suffit de prendre son application telle quelle et de la mettre sur le cloud sans faire de modification (technique du lift and shift). Cela permet de tirer parti de tous les avantages de son fournisseur de cloud :
- Utilisation de services en haute disponibilité (par exemple AWS RDS PostgreSQL qui met à dispo un serveur de base de données en haute disponibilité d’un simple clic)
- Utilisation d’une infrastructure moderne
Malheureusement cela n’est pas suffisant, car même les fournisseurs de Cloud les plus connus peuvent avoir des problèmes et provoquer des indisponibilités comme Google en 2013.
De plus si le problème est applicatif (ne supporte pas la charge, crash, envoi de réponse non conforme…), la migration dans le cloud n’apporte aucune solution à notre problème.
Dernières précisions :
- Certaines applications ne pourront pas profiter de cette solution, car elles ne pourront jamais être migrées sur le cloud, car
- Ne respectant pas les bonnes pratiques de développement (IP en dur dans le code…)
- Nécessitant du hardware trop particulier.
- Le passage dans le cloud, pour en tirer vraiment parti et éviter l’effet big bang, demande aussi un changement de culture.
- Le cloud ne rattrapera pas les architectures s'appuyant sur l'infrastructure (VMware Fault Tolerance...) et les exploitants qui compensaient à des coûts prohibitifs le manque de prise en compte de la résilience dès la conception.
Utilisation de répartiteur de charge (Load balancers)
Solution plus évoluée que la précédente, mais qui peut demander beaucoup de modifications du code source de notre application (ajout de health check, passage en stateless pour vraiment en tirer profit…) : le répartiteur de charge.
C’est un composant réseau ou applicatif qui répartit les requêtes sur différentes instances de façon à équilibrer la charge.
Par exemple, AWS ELB d’Amazon et HAProxy.
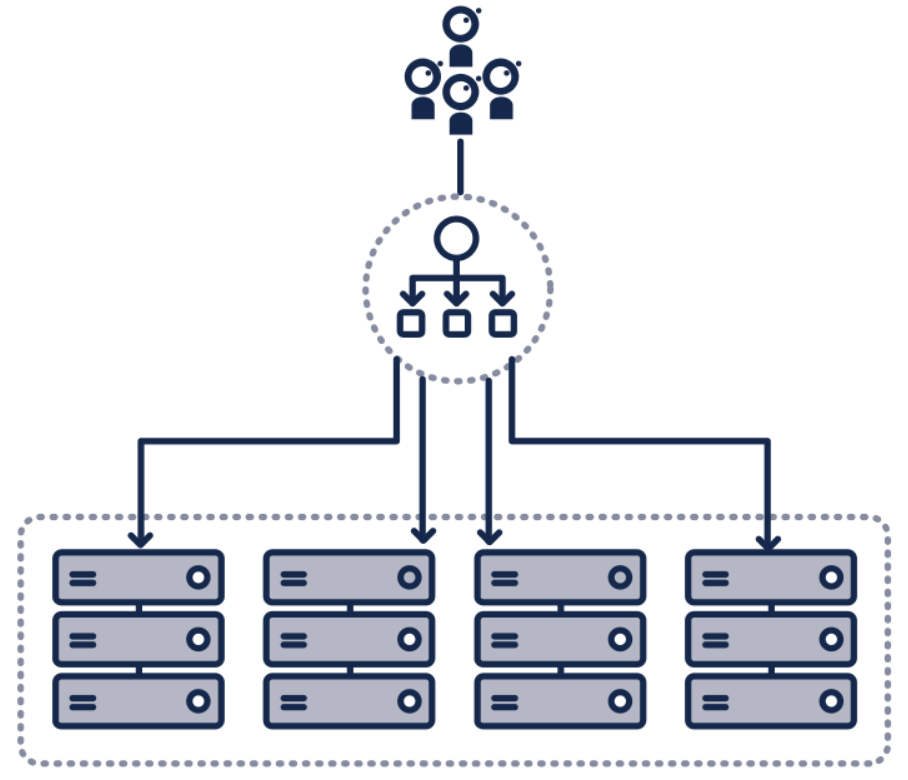
Dans notre cas (gérer les dépendances et réseaux défaillants), le répartiteur de charge va :
- Sortir du cluster les instances défaillantes ou mettant trop de temps pour répondre
- Répartir au mieux la charge
Encore une fois, cela ne sera pas suffisant dans notre cas pour différentes raisons :
- Impossibilité d’ajout de répartiteur de charge dans certains cas (service externe, protocole non supporté, stockage des données…)
- Complexification de l’architecture (plus de composants/serveur/…) et donc de l’exploitation et du diagnostic des problèmes de production
- Complexité de trouver la bonne configuration pour les lignes de vie (health check)
Design pattern : Timeout
Autre solution possible, qui par contre va surement demander des modifications du code source de l’application : le design pattern timeout.
Il permet de ne pas attendre indéfiniment une réponse en positionnant un temps d’attente maximal.

Le problème de ce pattern est qu’il n’est “pas très intelligent”, car si le service appelé est hors service, le service appelant va quand même faire l’appel. Ce qui implique :
- L’erreur n'arrivera qu'après le temps d’attente maximum (contraire au fail fast)
- Consommation de ressource (connexion, mémoire…) inutile, car nous aurons une erreur à la fin
Design pattern : Retry Pattern
Dernier design pattern présenté, le Retry Pattern demandera des modifications de code.
Il consiste à envoyer à nouveau la requête qui a échoué. Et donc si le service appelé “tombe en marche”, cela sera transparent pour l’utilisateur au prix d'une latence significative.
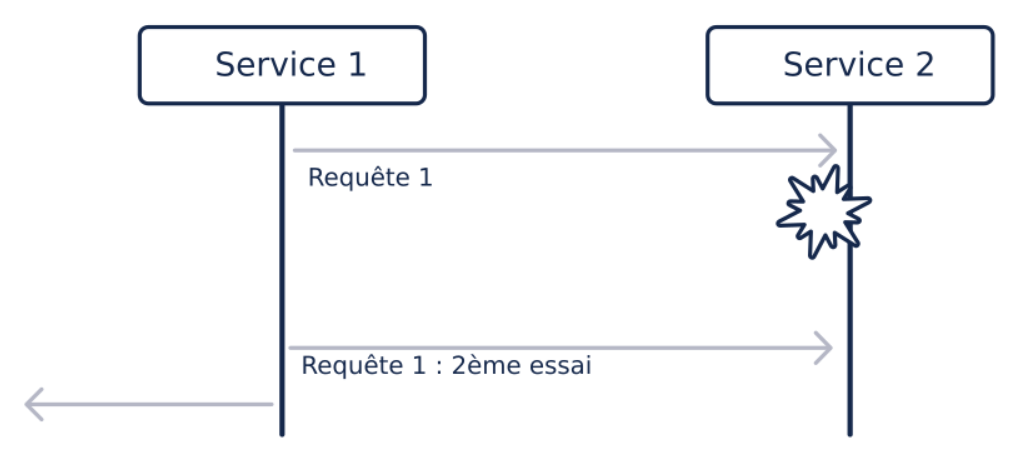
Par contre, si le service appelé reste hors service, l’application risque une surcharge en multipliant les requêtes.
Ainsi, ce pattern n’est à utiliser que dans le cas particulier où nous savons, par expérience (mais dont la cause n’a pas encore été corrigée, car la solution est impossible/trop chère/inconnue), que l'interruption de service est temporaire et courte.
Mais le plus important est que les requêtes sur lesquelles on veut appliquer le pattern doivent être idempotentes, car sinon il y a un risque de corruption des données ou de comportement non prévu.
Par exemple, supposons que notre application permet d’accélérer ou de ralentir une voiture à l’aide de deux boutons.
Lors de l’appui sur le bouton d’accélération, nous envoyons l’ordre d’accélérer de 5km/h. Pour une raison quelconque, la requête n’arrive pas tout de suite et donc notre pattern envoie un deuxième ordre d’accélérer de 5km/h. Résultat au lieu d’accélérer de 5km/h nous accélérons de 10km/h
La bonne solution aurait été d’envoyer l’ordre idempotent : passe à 110km/h. Dans ce cas peu importe le nombre d’ordres reçus.
Si l’utilisation de requête idempotente n’est pas possible, il faudra utiliser un autre pattern nommé Exactly-once Delivery qui peut être compliqué à mettre en place.
Nous pourrions encore parler longtemps de pattern, mais il est temps de passer à l’essentiel de cet article : le design pattern “circuit breaker”.
Pour avoir une idée des autres patterns (Bulkhead, Event sourcing, Feature Flipping, Pets versus Cattle...), nous vous laissons lire notre livre blanc “Cloud Ready Apps”.
Conclusion
Nous venons de voir quelques solutions pour résoudre la gestion des dépendances (externe ou interne) qui peuvent (et le seront tôt ou tard) défaillantes lors de l’exécution de notre application.
Lors de la prochaine partie, nous discuterons du pattern circuit breaker.