Big data : quelques mythes
Chez mon coiffeur, posé sur la table basse, un de ces magazines masculins branchés avec un mannequin en couverture, et la promesse d’apprendre comment éviter les 10 erreurs classiques lorsqu'on porte une cravate. J’ouvre par hasard la page 34 : “La révolution Big Data”.

Le sujet continue de prendre de l’ampleur, et en particulier auprès du grand public, ce qui a pour effet d’agacer beaucoup de monde. Chaque succès trouve sa critique…
On peut légitimement se demander comment le public parvient à comprendre le Big Data. Entre les journalistes simplificateurs, les aigris agacés par l’utilisation du terme et les vendeurs qui promettent des miracles, pas facile de s’y retrouver. Je vais essayer dans cet article de démonter quelques mythes et de redéfinir le terme.
Big Data = Big Brother
Ce cliché est un véritable ennemi public. Non, je ne travaille pas à la NSA et non je ne fais pas l’utilisation frauduleuse de vos données personnelles!
Quest-ce que Big Data?
- Un phénomène culturel et technologique à l’origine d’une accumulation exponentielle des données dans nos systèmes d’informations. Nous partageons, communiquons et produisons de la donnée de plus en plus, tout le temps et partout.
- Une amélioration des infrastructures, des technologies et des méthodes statistiques pour analyser massivement ces données.
- Le constat qu’au vu de la quantité de données produites, la masse cérébrale humaine mondiale ne sera pas en mesure de tout analyser. D’où l’importance de la Datascience, du machine learning et de l’Intelligence Artificielle pour transformer de façon automatisée cet océan de données en informations, ou mieux, en savoirs.
Les phénomènes n’ont pas d’inclination morale. Pas plus que les outils ou les technologies. L’analyse de données a toujours existé. La constitution de fichiers de renseignements aussi. Les applications du Big Data concernent avant tout l’amélioration des services de santé, l’optimisation et la réduction de la consommation d’énergie (smart metering, smart city), l’amélioration de notre expérience utilisateur, le partage de la connaissance humaine, la lutte contre la fraude bancaire, l’open data et l’idée de transparence…
Big Data = Hadoop

Oui, Hadoop et son écosystème forment un acteur majeur et un outil incroyablement riche. Cependant, son utilité et son rôle sont souvent mal compris. Hadoop ne remplace pas le Datawarehouse. Hadoop n’est pas originalement prévu pour réaliser du reqûetage intéractif mais du traitement batch massif et hyper performant. Hadoop n’est pas destiné à servir du reporting à des utilisateurs finaux en dessous de la milliseconde. Hadoop n’est pas fait pour le traitement de flux en temps réel.
C’est pour cette raison que des distributions telles qu’Hortonworks se sont enrichies avec de nombreux autres projets comme HBase, Solr, Storm. Pour comprendre Hadoop il faut s’intéresser aux patterns d’utilisation et d’accès de la donnée. De quoi avons nous besoin?
- Faire des scans complets de ma donnée pour calculer des agrégations, des indicateurs → Map Reduce, Hive, Pig
- Stocker de grandes quantités de données dans un format permettant de requêter un objet spécifique instantanément → Hbase
- Traiter des données en flux avec des latences minimes et de grand volumes→ Storm
- Analyser ou indexer des documents texte → Solr, ElasticSearch
- Entraîner des modèles prédictifs par apprentissage → Mahout, H20
En fait cet écosystème tire sa puissance dans sa capacité à atomiser et distribuer sur plusieurs machines ce que les bases de données traditionnelles essaient de faire seules :
- Indexation
- Transactionnalité
- Latence faible / requêtage intéractif
- Full scan / Calculs d’agrégations
- Multi-tenancy
Il ne faut pas voir Hadoop comme une solution miracle, mais comme un assemblage complexe de solutions hétérogènes adressant des use cases et patterns d’accès variés :
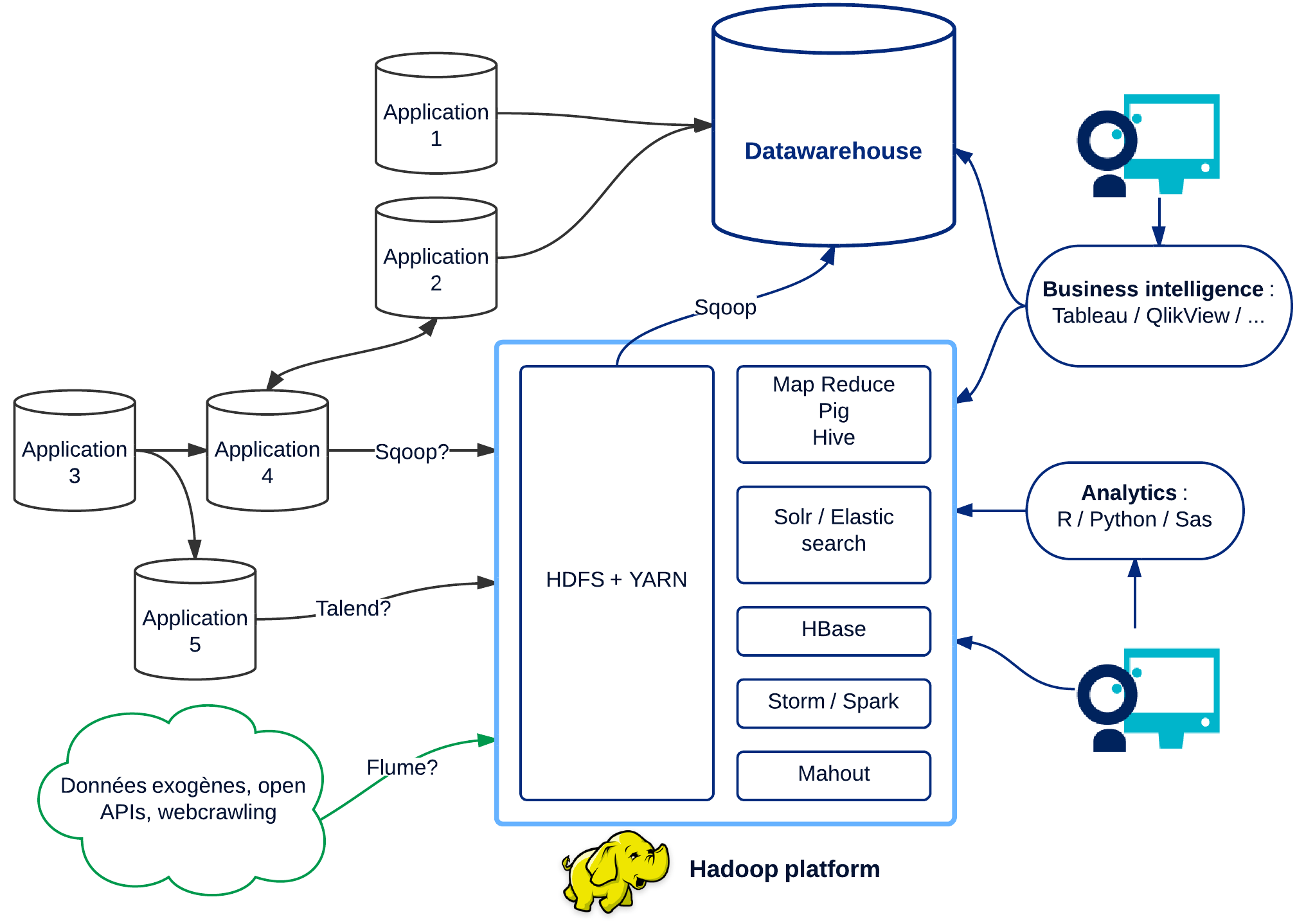
Enfin, Big Data ne concerne pas uniquement le traitement massif de données, mais leur exploitation au travers de méthodes statistiques sophistiquées, et en particulier grâce au machine learning! Il faut bien avouer qu’Hadoop manque encore de maturité à ce sujet tant au niveau de Mahout, qu’au niveau des connecteurs à R ou Python qui ne permettent pas réellement de distribuer les algorithmes. D’ailleurs en dessous du Téra, voire plus, on peut s’en tirer avec un peu de bonne volonté sans Hadoop grâce à postgres SQL et Python Pandas! On parle même de “small data”…
Big Data = Grands Volumes de données
Non! Nous venons bien de voir la complexité du problème à traiter avec les patterns d’accès.
Big Data = Volume, Vélocité, Variété?
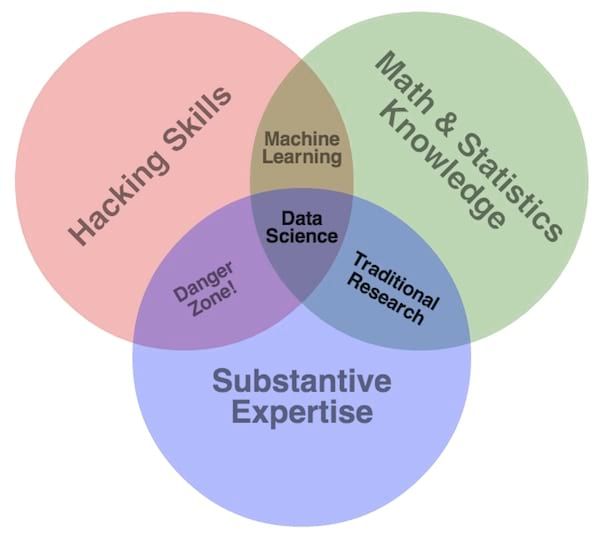
C’est déjà mieux. Mais la partie la plus intéressante réside dans la conjonction entre l'analytique et le florilège de données dont nous disposons. Big Data ne doit pas être un sujet IT, mais adresser des use-cases et des enjeux business. Trop d’entreprises portent comme initiative Big Data l’installation d’un cluster Hadoop. Par ailleurs, trois compétences sont généralement nécessaires pour mener à bien un projet de datascience, et elles ne se limitent pas à l’IT :
Big data = unstructured data
On parle beaucoup de la donnée non structurée et de la capacité des technologies Big Data. Pour être sincère, accordons nous d’abord sur le fait qu'en dehors des entreprises spécialisées dans le média, la majorité de la donnée qui nous incombe est structurée (des tables, des champs, des colonnes, des lignes, des dates). Dans le reste, on peut imputer une bonne part au texte libre. Pour finir? Une minorité de vidéos, d'images, de fichiers sons. Ces données sont moins structurées mais possèdent toujours des formats, plus ou moins unifiés. Il vaudrait en réalité mieux parler de multi-structure. Big data n’a pas de manière intelligente de traiter avec cette hétérogénéité sinon de dire : “load first, model second”. Donc modéliser la donnée après chargement, si c'est nécessaire.
D’ailleurs, les gens du marketing adressent depuis des années cette problématique de l’hétérogénéité des formats. En revanche, les outils liés au search permettent de grandement simplifier l’utilisation de données faiblement structurées, et les méthodes pour traiter ces différents formats se sont unifiées (Apache Tika en est un exemple).
Enfin, il y a un plancher à dépasser en dessous duquel il est très complexe d’analyser à moindres coûts des données vidéo, son, image ou texte libre.
Big data = analyser les réseaux sociaux et faire de l’analyse de sentiments
“Nous allons analyser Twitter et prédire la bourse”.
Vous êtes sûrs? Je conseillerais plutôt d’essayer l’inverse, cela marchera sûrement mieux.
Analyser des données des réseaux sociaux peut être très intéressant mais reste complexe, et souvent inapplicable/inintéressant pour un grand nombre de business. L’usage principal restant étant l’analyse de l’e-réputation.
Les données internes à l’entreprise sont déjà bien souvent une mine d’or inexploitée qui se contente de Business Intelligence traditionnelle. Un premier pas serait de transcender le reporting multidimensionnel et parvenir à de l’analyse prédictive ou non supervisée afin de détecter des signaux faibles.
Oui, ce papier d’humeur est truffé de partis pris. Pour autant Big data est un sujet en pleine Hype et pour lequel il faut redoubler de méfiance envers les prédicateurs de bonne paroles, les gourous et les vendeurs de tapis. Certains mythes affectent en mal la vie des projets, conduisant à une vision négative et erronée. Le potentiel avantage économique lié au Big Data doit être étudié avec discernement, et dirigé par la vision business. Les investissement doivent être pilotés et pensés plus globalement au travers du développement digital de l’entreprise en répondant à des besoins métiers précis.