Bases de données graphes : un tour d'horizon
Dans un précédent article, nous avons introduit quelques concepts à propos des graphes, et les avons illustrés par deux exemples en utilisant la base de données graphe Neo4j. Au cours de ces dernières années, de nombreuses compagnies ont développé leur solution de base de données graphe, en tant qu’éditeur comme Neo Technology avec Neo4j, Objectivity avec InfiniteGraph ou encore Sparsity avec dex*, ou en développant leur propre solution pour l’intégrer à leur application, comme LinkedIn ou Twitter. Il est donc assez difficile de s’y retrouver dans ce paysage riche, qui continue à évoluer très vite. Dans ce nouvel article qui se focalise sur les bases de données graphes, nous donnerons les éléments nécessaires à la compréhension de leur positionnement dans leur écosystème, par rapport aux autres types de base de données et aux autres types d’outils dédiés au traitement de graphes. Plus précisément, nous essaierons de répondre à une question importante, à savoir quand utiliser une base de données graphes et quand ne pas en utiliser, ce qui n’est pas forcément évident.
Qu’est-ce qu’une base graphe?
Une base de données graphe est une base de données spécifiquement dédiée au stockage de structures de données de type graphe. Il s’agit donc de stocker exclusivement les données dans des noeuds et des arcs. Par définition, une base graphe correspond à tout système de stockage fournissant une adjacence entre éléments voisins sans indexation : tout voisin d’une entité est accessible directement par un pointeur physique. Les types de graphes pouvant être stockés peuvent varier, du graphe non orienté “single-type” à l’hyper-graphe, en passant bien sûr par les property-graphs.
Une telle base de données répond donc généralement aux critères suivants :
- Stockage optimisé pour des données représentées dans un graphe, avec possibilité de stocker des noeuds et des arcs.
- Stockage optimisé pour la lecture et le parcours de données dans le graphe (ou Traversal), sans recourir à un index pour parcourir les relations. Une base graphe est optimisée pour des recherches exploitant la localité des données, à partir d'un ou plusieurs noeuds racines, plutôt que des recherches globales.
- Modèle de données flexible pour certains produits : pas besoin de créer explicitement une entité pour les noeuds ou les arêtes, à la différence du modèle rigide par tables d’une base de données relationnelle.
- API intégrée permettant d’utiliser certains algorithmes classiques de la théorie des graphes (plus court chemin, Dijsktra, A*, calcul de centralité...)
Positionnement
Le mouvement NoSQL connaît son heure de gloire depuis quelques années, notamment car il cherche à adresser plusieurs problématiques auxquelles les bases relationnelles ne répondent pas suffisamment :
- disponibilité pour traiter de très gros volumes et partitionnement (trop axées sur la consistance, le C du théorème de CAP),
- flexibilité du schéma,
- difficulté de représenter et traiter des structures complexes comme des arbres, des graphes, ou des relations en très grand nombre.
Dans l’écosystème des bases de données, on positionne les bases graphes principalement sur les deux derniers points :
- traiter des données fortement connectées
- gérer facilement un modèle complexe et flexible
- offrir des performances exceptionnelles pour les lectures locales, par parcours de graphe.
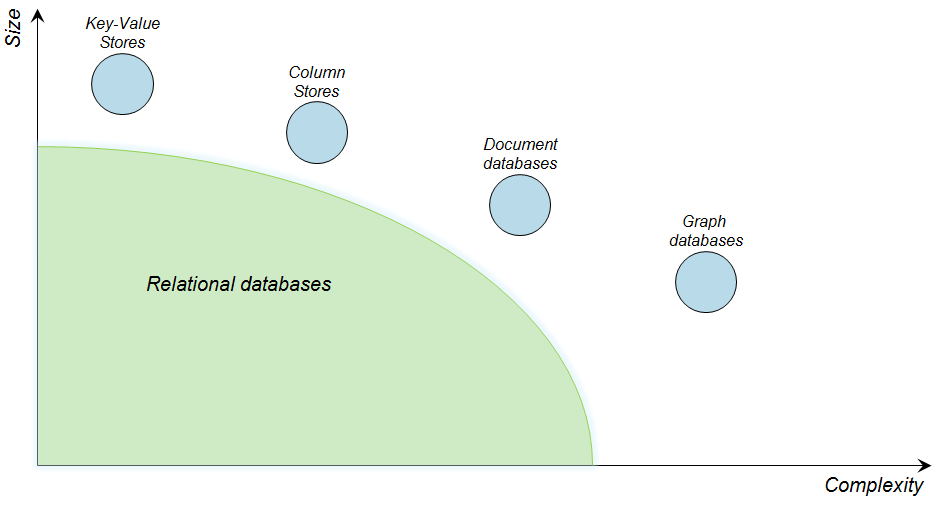
Positionnement des bases de données NoSQL (source : Neo4j)
Bases graphes et bases relationnelles
Une base graphe est adaptée à l’exploitation des structures de données de type graphe ou dérivée comme des arbres, particulièrement s’il s’agit d’exploiter les relations entre les données. Le cas d’usage idéal d'une recherche est donc de partir d’un ou plusieurs noeuds et de parcourir le graphe. Il est toujours possible d’effectuer des lectures de type myEntity.findAll (“trouver toutes les entités d’un type”), mais il faut dans ce cas utiliser un système d’indexation, qui pourra selon les cas être interne au graphe (super-noeuds servant à l'indexation) ou au dessus du graphe (via Apache Lucene par exemple).
A l’inverse, les bases relationnelles sont tout à fait adaptées à des requêtes findAll grâce aux structures internes des tables, d'autant plus s'il s'agit de réaliser des opérations d'aggrégations sur toutes les lignes d'une table.
Malgré leur nom, elles seront cependant moins efficaces sur l’exploitation des relations, qui doit être optimisée par la mise en place d’index, notamment les clés étrangères. Comme dit précédemment, une base graphe offre la possibilité de parcourir les relations par pointeurs physiques, là où les clés étrangères n'offrent qu'un pointeur logique.
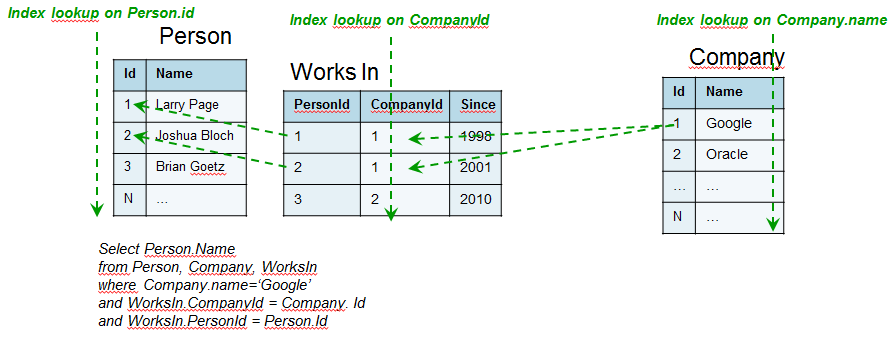
Pour mieux comprendre, prenons un exemple naïf, dans lequel on modélise des sociétés, les personnes qui y travaillent et depuis combien de temps. On cherche par exemple à trouver les personnes qui travaillent chez Google.
Dans le cas d'une modélisation relationnelle, on pourrait obtenir l'exécution décrite ci-dessous, qui nécessite a priori 3 lookups d'index, optimisés en fonction des indexes et des clés étrangères déclarés.
Dans le cas d'une modélisation dans un graphe, la requête nécessitera un lookup d'index, puis un parcours par pointeurs physiques des relations dans le graphe.
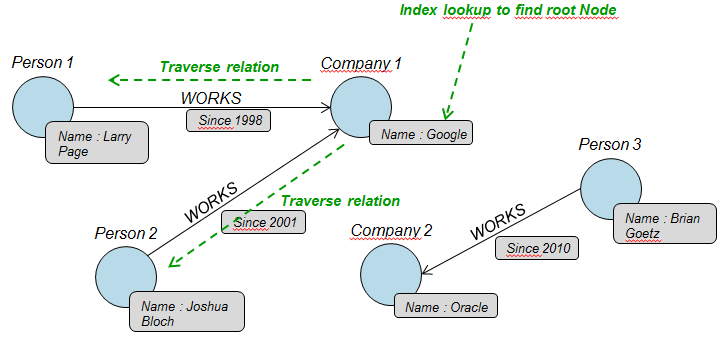
Cet exemple reste extrêmement simple, mais met en évidence un cas d'usage sur lequel une base graphe s'avérera logiquement plus performante qu'une base relationnelle.
La différence de performances sera d'autant plus importante lorsque la quantité de données stockées augmente, car hormis le lookup d'index pour trouver le(s) noeud(s) de départ du parcours de graphe, la requête se fera en temps à peu près constant dans un graphe, au contraire de la base de données relationnelle dans laquelle chaque parcours d'index pour récupérer une clé étrangère coûtera o(log2 N) si l'index est stocké dans un B-Tree (avec N le nombre d'enregistrements dans la table parcourue).
Comparer les performances entre une base de données graphe et une base de données d’un autre type est un exercice difficile de par leurs natures et leurs objectifs différents. Une base graphe surpassera naturellement les performances en lecture d’une base relationnelle sur son domaine de prédilection, les traversals, et d’autant plus si la profondeur de ceux-ci est importante ou n’est pas déterminée à l’avance (il serait dans ce cas impossible d’optimiser le plan de la requête SQL à l’avance), ce que tendent à montrer les quelques comparatifs existants sur le Web.
Graph storage et graph processing
Une autre comparaison qu’on est amené à faire est celle des bases de données graphes par rapport aux outils de “large-scale graph processing” comme Google’s Pregel ou BSP, récemment présentés ici. Une première différence importante est qu’on a affaire à des outils aux objectifs assez différents, bien qu’ils partagent les mêmes modèles de données. Jim Webber de Neo Technology donne ici un point de vue intéressant bien qu’assez partisan :
- Les outils de graph processing, comme leur nom l’indique, addressent uniquement des problématiques de calcul et d’analyse (OLAP), tandis que les bases graphes adressent essentiellement des problématiques de stockage et de calculs transactionnels (OLTP).
- Les outils de graph processing impliquent, de la même manière que des outils comme Hadoop, une certaine latence dans les calculs (plusieurs secondes), tandis que Neo4j vise des lectures plutôt temps réel (de l’ordre de la ms).
- Les deux n’adressent pas la même échelle de calculs, et n’ont pas non plus les mêmes exigences matérielles : une base graphe come Neo4j adresse essentiellement la problématique du volume par scale-in sur un seul serveur là où un outil comme Pregel l'adresse par scale-out en distribuant les traitements sur plusieurs machines de type commodity hardware.
- Les outils de graph processing sont entièrement distribués, possibilité que n’offrent pas la plupart des bases graphes.
On a donc affaire à deux familles d’outils qui adressent des types et des échelles de problèmes différents : en terme d'usages, on utilisera plus facilement une base graphe pour la navigation dans le graphe ou une recherche de plus court chemin, tandis qu'un outil de graph processing adressera plutôt du clustering de graphe, de la recherche de centralité ou encore une recherche globale de tous les chemins.
Les bases graphe connaissent toutefois une limite liée à leur structure, celle de la taille : il est complexe de partitionner un graphe, particulièrement en tenant compte de la latence réseau, des patterns récurrents de parcours du graphe (quelles relations sont les plus parcourues) et surtout de l’évolution en temps réel du graphe. Certaines bases graphes, OrientDB et InfiniteGraph, s’affichent comme facilement partitionnables, tandis que les gars de Neo4j travaillent sur le sujet.
Il faut néanmoins garder à l’esprit qu'une base graphe sera adaptée à l’échelle de la plupart des entreprises et qu'il est possible de stocker plusieurs milliards de noeuds sur un seul serveur : tout comme il ne s’agit pas de jeter les bases de données relationnelles parce qu’elles n’adressent pas bien des problématiques de données en gros volume aussi bien que des outils de Business Intelligence ou une stack SMAQ (Storage, MapReduce and Query) comme Hadoop, on ne va pas systématiquement mettre de côté une base graphe comme Neo4j au profit d’un Pregel.
La présentation du nouveau challenger Titan par Marko Rodriguez permet d’aller plus loin dans la compréhension du riche écosystème des graphes.
Il résume par ailleurs très bien le positionnement des différents outils de traitements de graphes dans ce graphique, en fonction de la taille des données à utiliser par rapport à l'objectif de vitesse des parcours du graphe : plus la taille du graphe à exploiter est grande (et surtout la portion du graphe à parcourir), moins les outils adaptés permettent un traitement en temps réel.
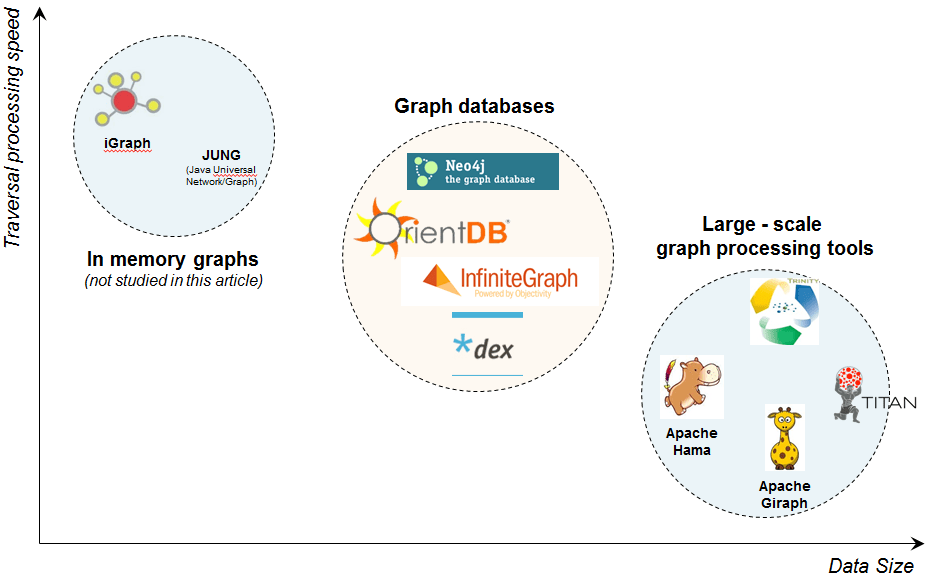
Classification des outils de traitement de graphes (source: Marko Rodriguez)
Modélisation
Un dernier point particulièrement important en faveur d’une base graphe réside dans la facilité de modélisation des données. Bien souvent, lorsque nous modélisons un problème métier puis les données correspondantes, cela peut ressembler à ça :
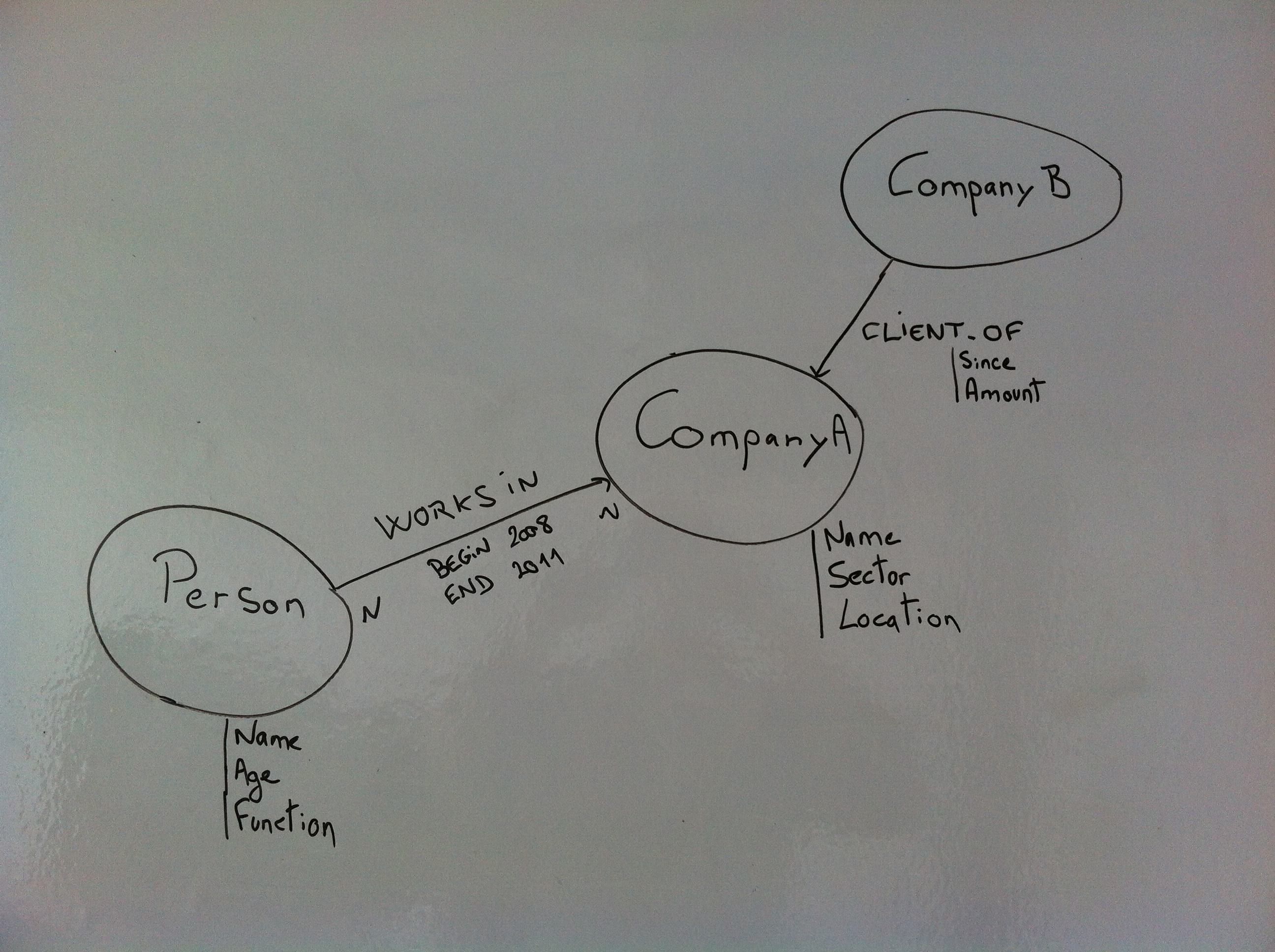
Modèle métier
Ensuite, une fois qu’on a choisi un système de stockage, il est temps de faire rentrer notre modèle de données dedans. Si nous choisissons une base relationnelle, on commence généralement par normaliser notre modèle afin de bien se conformer à la 3e forme normale, et ça pourrait donner quelque chose comme ça :
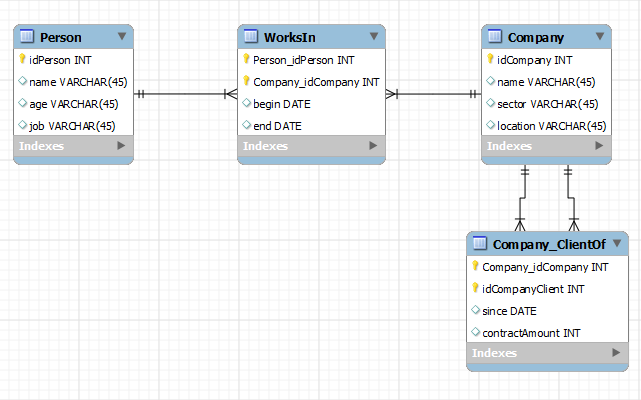
Modèle relationnel
Alors que si on choisit de modéliser nos données dans une base graphes, ça pourrait naïvement donner ceci :
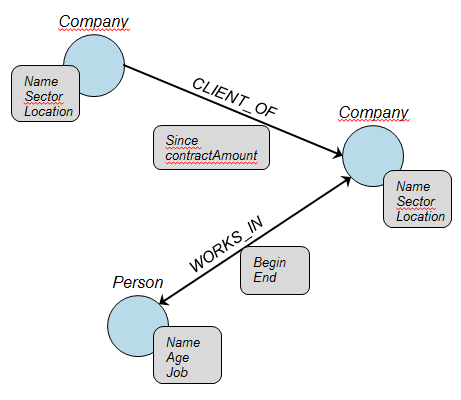
Modèle graphe
La modélisation de données sous forme de graphes est naturelle, et comporte donc l’avantage non négligeable d’être lisible, même sans background technique. Cet exemple reste néanmoins très simpliste, et de même qu'un modèle relationnel normalisé est parfois dénormalisé pour des raisons de performances, certaines optimisations moins lisibles à “l’oeil nu” de la modélisation du graphe peuvent être nécessaires.
Alors, que choisir?
Il n’y a pas de réponse univoque à cette question, et ce qui ressort de cet article est que tout dépend de l’usage qui sera fait de la donnée.
Si votre système nécessite d'exploiter des données sous forme de graphe, d'arbre, de structure hiérarchique, en résumé avec un modèle complexe et fortement connecté, alors il est probable qu'une solution de gestion de graphes réponde à votre besoin.
Ensuite, tout dépend de la manière dont vous souhaitez exploiter ces données : si vous souhaitez essentiellement du temps réel et que vos données restent d'une taille raisonnable, alors une base graphe ou une solution de graphe en mémoire devrait convenir.
Si en plus il apparaît préférable de stocker la donnée sous forme de graphe, alors une base graphe devrait faire l'affaire. Faire le choix d’une base graphe permettra d’exploiter facilement les relations, mais demandera des compromis comme des définitions d'index supplémentaires pour faire du reporting ou de l’affichage CRUD classique, et vice-versa si on choisit une base relationnelle, etc.
Enfin, si la taille des données à exploiter est gigantesque, une solution de graph-processing est à envisager, mais au prix d'un temps de traitement plus important s'orientant vers une approche en batch.
Le choix de la base de donnée est un choix d’architecture crucial qui est souvent pris dès le début du projet, mais il ne doit pas être gravé dans le marbre. En gardant un code et une architecture propres, respectant la séparation des responsabilités, ainsi qu’une vision claire du modèle de données, le choix peut évoluer, vers un changement d’architecture, ou même l’adoption d’une seconde solution de persistance adaptée aux nouveaux cas d’usages : on parle alors de persistance polyglotte.
Dans le prochain article, nous vous proposerons d'approfondir les caractéristiques des différentes bases de données graphe et des outils de développement associés qui se détachent aujourd'hui.