Analyse prédictive en temps réel : machine learning avec Storm et Scikit-Learn
Vous avez beaucoup de données, des technos de calcul distribué à la mode et vous ne savez pas quoi en faire? Bienvenue dans l’écosystème Big Data.
Les technologies Big Data fleurissent et avec elles de nombreux enjeux architecturaux. L'un d'entre eux est notamment la difficulté à profiter des capacités de calcul pour réaliser des traitements statistiques sophistiqués. En effet le développement d’algorithmes de machine learning dans un contexte distribué voir incrémental est très complexe. De plus les analystes de données sont historiquement liés à des technologies telles que R, Matlab ou Python. Ces technos ne sont pas aisément parallélisables et ne font pas partie de l'univers Java, contrairement aux Hadoops, Storms, Sparks et consorts.
Dans cet article, nous allons étudier une piste pour réconcilier ces braves gens et nous intéresser à Storm et Scikit-Learn. Mais avant, quelques rappels.
Scikit-Learn
Une librairie Python open-source pour réaliser toutes les taches liées au machine learning : feature pre-processing, feature selection, model fitting, model evaluation...Elle se base sur Numpy et Scipy pour pallier les lenteurs du serpent. La syntaxe de la librairie est simple et on profite de l’aspect script de Python pour manipuler aisément de la donnée.
Storm
Un CEP open source en Clojure permettant de faire du traitement distribué. Pour plus d’informations sur Storm, lisez Quest-ce que storm?
Le use case
On va prioriser des actions marketing qui arrivent dans un backlog. Dans notre cas, appeler des clients pour leur proposer une offre, par exemple, un prêt, ou un nouveau contrat d’assurance. Comme on a beaucoup de clients, et que la plupart des appels sont des échecs on va essayer de se concentrer sur les appels qui ont le plus de chance de donner lieu à une souscription. On a pour données des informations clients (age, travail, durée du dernier contrat souscris, salaire annuel…) et l’issue des appels qu’on leur a déjà passé : positif ou négatif.
Un premier travail d’exploration de la donnée avec Scikit a abouti à la création du modèle de prédiction :
- Les features ont été catégorisées puis passées à un modèle de type Random Forest.
- On a également supprimé les features qui manquaient de pertinence grâce à un test de corrélation avec la classe de décision (chi2 par exemple).
- 35000 cas ont servi comme set d’entrainement pour la phase d'apprentissage.
- La précision du modèle a été évaluée à 92% sur un jeu de test de l’ordre de 10000 cas.
Nous allons nous servir de ce modèle au sein de Storm pour scorer les appels clients potentiels qui arrivent au fur et à mesure dans le système.
L'implémentation
Commençons par un survol de l'architecture:
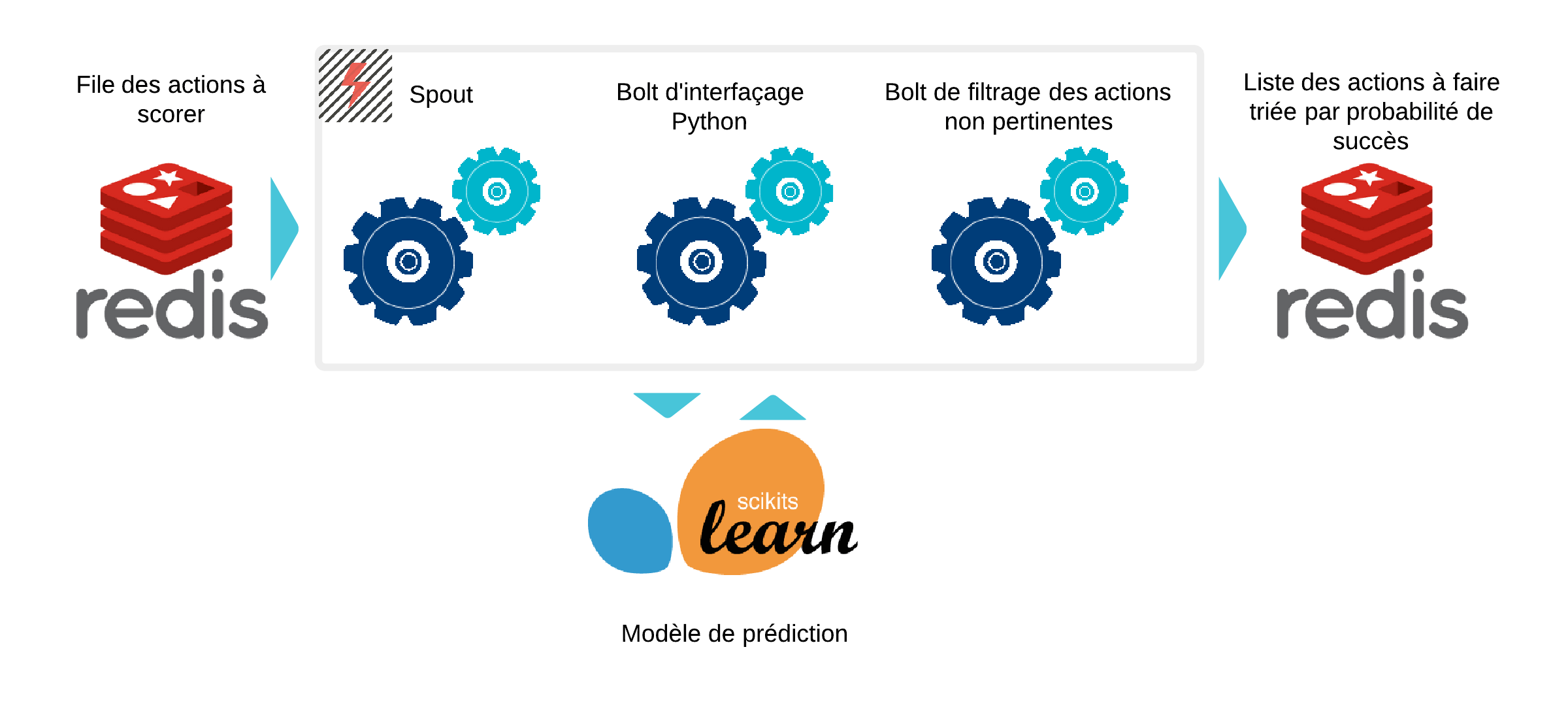
On utilise Redis comme cache pour le flux d'entrée (on peut imaginer qu'un CRM dépose des logs dessus par exemple). Il est ici réutilisé par simplicité comme base d'historisation des résultats. Storm va ensuite se charger des traitements, dont l’interaction avec l'interpréteur Python censé fournir les prédictions.
Les actions à scorer sont déposées dans une liste Redis sous la forme suivante :
redis 127.0.0.1:6379>lrange logs 0 1
1) "{\"phone\": \"0655569192\", \"features\": [\"3.400000000000000000e+01\", \"4.000000000000000000e+00\", \"2.000000000000000000e+00\", \"3.000000000000000000e+00\", \"0.000000000000000000e+00\", \"6.013000000000000000e+03\", \"1.000000000000000000e+00\", \"0.000000000000000000e+00\", \"0.000000000000000000e+00\", \"9.000000000000000000e+00\", \"8.000000000000000000e+00\", \"6.120000000000000000e+02\", \"1.000000000000000000e+00\", \"-1.000000000000000000e+00\", \"0.000000000000000000e+00\", \"3.000000000000000000e+00\"]}"
2) "{\"phone\": \"0683752420\", \"features\": [\"3.100000000000000000e+01\", \"4.000000000000000000e+00\", \"2.000000000000000000e+00\", \"2.000000000000000000e+00\", \"0.000000000000000000e+00\", \"2.915000000000000000e+03\", \"0.000000000000000000e+00\", \"0.000000000000000000e+00\", \"0.000000000000000000e+00\", \"2.300000000000000000e+01\", \"0.000000000000000000e+00\", \"2.280000000000000000e+02\", \"1.000000000000000000e+00\", \"8.600000000000000000e+01\", \"1.000000000000000000e+00\", \"0.000000000000000000e+00\"]}"
Le Spout va consommer autant que possible les éléments de cette file et les distribuer à travers le reste de notre Topologie Storm en direction des Bolts, responsables eux des traitements.
public class LogsSpout extends BaseRichSpout {
private transient Jedis client;
SpoutOutputCollector _collector;
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
_collector = collector;
client = new Jedis("");
client.connect();
}
public void nextTuple() {
_collector.emit(new Values(client.lpop("logs")));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
}
Nous avons ensuite besoin d'un Bolt capable de réaliser un appel à python afin d'évaluer le score de l'élément dépilé. L'api de Storm propose une classe abstraite ShellBolt permettant cela. Nous allons spécifier la commande à utiliser ainsi que le fichier Python contenant le code réalisant la prédiction. La commande passée correspond à un environnement virtuel Python personnalisé contenant les librairies de machine learning dont on a besoin : Numpy, Scipy, Scikit-learn, etc. Cet environnement a été construit avec Anaconda, un outil qui facilite grandement les installations de packages pour la Datascience.
public class PythonPredict extends ShellBolt implements IRichBolt {
public PythonPredict(){
super("/home/mab/anaconda/envs/env1/bin/python2.7","predict.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("phone","shouldcall"));
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
Il faut alors implémenter le traitement nécessaire de prédiction dans ce fameux predict.py. Ce fichier est placé dans le path de notre projet storm, au sein d'un package multilang que l'on peut trouver sur le dépôt d'exemple développé par Nathan Marz : Storm-starter.
import storm
from numpy import array
import json
import cPickle as pkl
class PythonPredict(storm.BasicBolt):
def initialize(self, stormconf, context):
self.model = pkl.load(open('/home/mab/pythons/bank/clf.pkl', 'r'))
def process(self, tup):
data = json.loads(tup.values[0])
result = self.model.predict_proba(data['features'])
storm.emit([data['phone'],str(result[:,1].tolist()[0])])
PythonPredict().run()
La méthode initialize permet d'instancier certains objets à conserver dans la mémoire du Bolt entre le traitement de tuples successifs. Ici on ne charge le modèle qu'une fois, que l'on a sérialisé au préalable. La méthode process s'exécute à la réception d'un tuple : on récupère les features de l'appel et on score la probabilité que l'issue soit positive. Le numéro de téléphone est réémis avec le score associé.
Pour vous montrer ce qu'est un Bolt classique, j'ai implémenté un filtre après émission des résultats. Si le score est inférieur à un certain niveau défini, le tuple n'est pas réémis. Cette logique est implémentée dans la méthode essentielle de tout bon Bolt : la méthode execute, appelée à chaque réception d'un nouveau tuple.
public class ProbabilityFilter extends BaseBasicBolt {
private Double treshold;
public ProbabilityFilter(Double treshold) {
this.treshold = treshold;
}
public void execute(Tuple input, BasicOutputCollector collector) {
if (Double.parseDouble((String) input.getValue(1))>treshold){
collector.emit(input.getValues());
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("phone","shouldcall"));
}
}
La dernière étape correspond simplement à un dump du tuple dans Redis au sein d'un ensemble ordonné. On obtient donc une liste triée par score afin de pouvoir dépiler les appels à plus fort taux de réussite probable.
public class DumpToRedis extends BaseRichBolt {
private transient Jedis client;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
client = new Jedis("");
client.connect();
}
public void execute(Tuple input) {
if (input.getValues().size()!=0){
client.zadd("calls", Double.parseDouble((String) input.getValue(1)), (String) input.getValue(0));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
Toutes nos unités de traitement sont codées, il ne reste maintenant plus qu'à les lier pour former une Topologie! La classe TopologyBuilder nous permet de déclarer la suite logique des traitements, le parallélisme associé à chaque unité et les stratégies de circulation des tuples (aléatoire, groupements par attributs...).
public class Topology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("logs", new LogsSpout(), 1);
builder.setBolt("predictions", new PythonPredict(), 8).shuffleGrouping("logs");
builder.setBolt("filter", new ProbabilityFilter(0.3), 4).shuffleGrouping("predictions");
builder.setBolt("dump", new DumpToRedis(), 4).shuffleGrouping("filter");
Config conf = new Config();
conf.setDebug(true);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
}
else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(100000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
Nous allons lancer cette topologie en local sur notre machine. On package notre projet avec Maven, et on l'exécute grâce au client Storm avec la commande suivante :
storm jar workspace/stormsklearn/target/stormsklearn-0.0.1-SNAPSHOT.jar stormsklearn.Topology
La file des appels scorés se remplie au fur et à mesure dans Redis sous la forme suivante (je ne vous garanti pas un contrat si vous appelez le premier numéro) :
redis 127.0.0.1:6379> zrevrange calls 0 4 withscores
1) "0682919154"
2) "0.96999999999999997"
3) "0665451989"
4) "0.93999999999999995"
5) "0620015547"
6) "0.93999999999999995"
7) "0697056964"
8) "0.93000000000000005"
9) "0683392563"
10) "0.93000000000000005"
Bilan
Nous avons réussi à obtenir des prédictions à la volée au sein de Storm. Cependant l'entrainement du modèle a été réalisé au préalable, ce qui est dommage car c'est l'étape la plus coûteuse en temps de calcul. Il semble que de meilleures solutions que Storm pour l'entrainement distribué sont en train d'émerger. On peut notamment penser à Spark avec le module MLBase, à H20, ScaleR ou encore au plus classique Mahout.
Hormis Spark, les autres noms cités ne proposent pas de traitement en temps réel et incrémental, ce qui place Storm dans une catégorie différente. De plus, la facilité déploiement et d'utilisation de l'API font de Storm un outil extrêmement intéressant. Des projets tels que Trident-ML visent à faire profiter Storm d'outils de Machine Learning, et en particulier ceux qui concernent l'Online Learning.
On peut également imaginer profiter des capacités de Storm pour l'aspect flux, et compléter les aspects d'entrainement avec une batch layer à base d'Hadoop et ainsi former une architecture lambda. Dans ce contexte, le modèle serait ré-entraîné régulièrement par la partie batch, et la partie flux se chargerait d'obtenir les prédictions.
Pour ce qui concerne Scikit-Learn, des options pour l'entrainement de modèles en mode distribué peut également s'orienter autour de IPython.parralel.
Des technos et des hommes
L'objectif de cet article est aussi de constater du frein que peuvent poser ces frameworks au cycle de vie d'un projet incluant des traitements statistiques. En effet, les compétences des statisticiens ou datascientists s'orientent souvent vers des outils faciles pour l'exploration et l'expérimentation mais difficiles pour l'intégration dans une architecture logicielle. Découpler la phase de conception des modèles et l'obtention de prédictions au sein d'un dataflow permet de réutiliser des compétences existantes et d'avoir une approche davantage itérative quant à la formalisation de modèles d'analyses. Scikit-learn est une librairie très efficace et largement utilisée par les utilisateurs de la plateforme de challenges de Datascience Kaggle : être capable de mettre à jour sans effort et à tout moment son modèle suite à une amélioration est un réel Atout. On peut également repenser l'implémentation proposée avec R, notamment grâce à rJava ou Storm-r.
"Tu trouves que ma donnée a grossi?"
Il faut également prendre en compte deux axes des problèmes d'analyses de données qui peuvent faire pencher la balance entre de l'entrainement distribué ou non. Le premier est lié à la réduction de la taille des données. Selon la formulation du problème auquel il faut répondre, les modèles vont être entraînés sur des agrégats. Par exemple si je souhaite prédire la moyenne des dépenses de chaque individu dans une chaîne de magasins, ou bien la moyenne des recettes de la chaîne, je peux dans un cas être en présence de ce que l'on pourrait appeler de la "big data", et dans l'autre, pas du tout. Toute la capacité de calcul serait donc nécessaire au calcul des agrégats, mais la partie Machine Learning ne s'opère que sur une faible quantité de données. Deuxièmement, je peux être en présence d'un grand nombre de données mais d'une dimension faible. Ainsi, l'ensemble des possibles est représentable avec une sous-partition du jeu de taille modérée, sur laquelle je peux entraîner mon modèle aisément. Que l'on parle de réduction de dimension sur les colonnes ou sur les lignes, ou bien de sampling sur les lignes, il faut bien garder en tête que toute la donnée n'est pas destinée à un algorithme de machine learning : il y a un équilibre à identifier entre des opérations simples de type ETL, facilement distribuables, et un réel apprentissage, plus complexe et plus demandeur en temps de calcul.
Enfin, certains projets tels que WiseRF promettent des performances hors normes sur un seul nœud, ce qui remet en cause le fait de s'impliquer dans la complexité de développement liée aux contextes distribués.
En conclusion
Pour profiter au mieux des différentes solutions technologiques ou architecturales, il faut encore et toujours formaliser au mieux son besoin, avoir une compréhension précise de son dataflow et savoir estimer avec honnêteté la dimension réelle de la donnée dont on dispose. Un élément clé à prendre en compte réside aussi dans l'héritage technologique de vos équipes : avez-vous les compétences pour votre projet? Quels sont les profils les plus à même de progresser sur ces technologies?
Heureusement, la grande majorité des outils cités dans cet article sont open-source, et les infrastructures nécessaires pour les abriter peuvent se constituer à l'aide de commodity-hardware. Alors pour répondre à toutes ces interrogations, gagnez du temps, passez par la case test!