A quoi sert Azul Zing ?
La compagnie Californienne Azul Systems a gagné sa notoriété au travers de son produit phare : la JVM Zing. Cette JVM promet d'excellentes performances pour applications Java de manière déterministe : Zing aura toujours une faible latence pendant toute la durée de vie d'une application en production. La clef de cette machine virtuelle vient de son algorithme sans pause : C4 (Continuously Concurrent Compacting Collector). Les promesses de cette JVM sont-elles réalistes ? A qui cette JVM peut bénéficier et pour quel coût ?
NB : cet article présuppose que vous connaissez les principes du Garbage Collector. Les algorithmes sont détaillés de manière très pédagogue (en anglais) par Martin Thompson dans l'article cité ci-dessous.
Les limites de la JVM HotSpot
Martin Thompson, dans son dernier article (Java Garbage Collection Distilled), décrit les algorithmes utilisés dans la JVM HotSpot et leurs limites en terme de performance.
Pourquoi des Garbage Collector avec générations ?
L'adage de tout algorithme de Garbage Collector (GC) est : "most objects die young". Cet adage sert de base au concept de générations dans les différents GC Java ou .NET. En effet, la plupart des objets créés (alloués en mémoire) par une application a une durée de vie courte; typiquement le cas d'objets alloués en tant que variable locale où la référence est sur la stack mais l'objet est sur la heap.
S'il n'y avait pas de génération, les threads du GC devraient parcourir tous les objets en continu pour vérifier ceux qu'il faut supprimer. Comme il existe un grand nombre d'objets ayant une durée de vie courte, parcourir plusieurs gigas de mémoire pour les supprimer n'est pas optimal. Ainsi, réserver une zone dédiée à ces objets (la Young : Eden + Survivor 0 + Survivor 1) réduit l'ensemble à parcourir et donc le temps de collection (temps converti en ressource CPU par les threads du GC).
Stop-The-World : latence et indéterminisme de la JVM HotSpot
Cette optimisation de ressource se fait au détriment de pauses pouvant être visibles dans les applications.
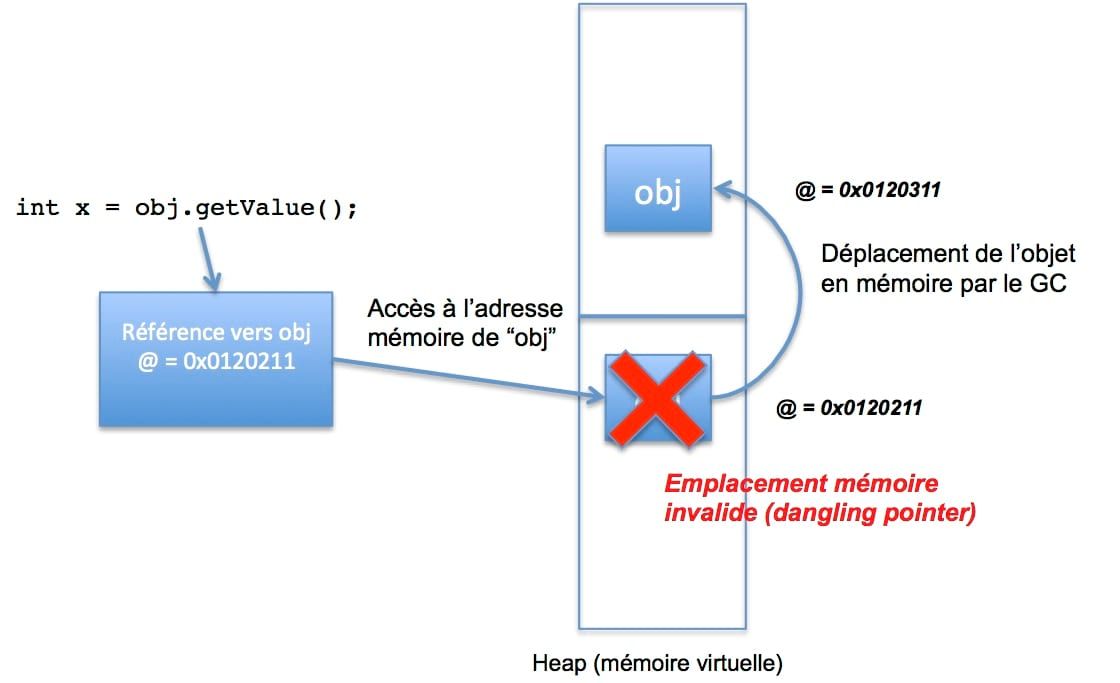
Les objets survivant à une collection changent de génération (Eden -> Survivors -> Tenured). Le changement de génération équivaut à un changement de pointeur dans la mémoire virtuelle (page). Chaque génération équivaut à une zone particulière dans la heap.
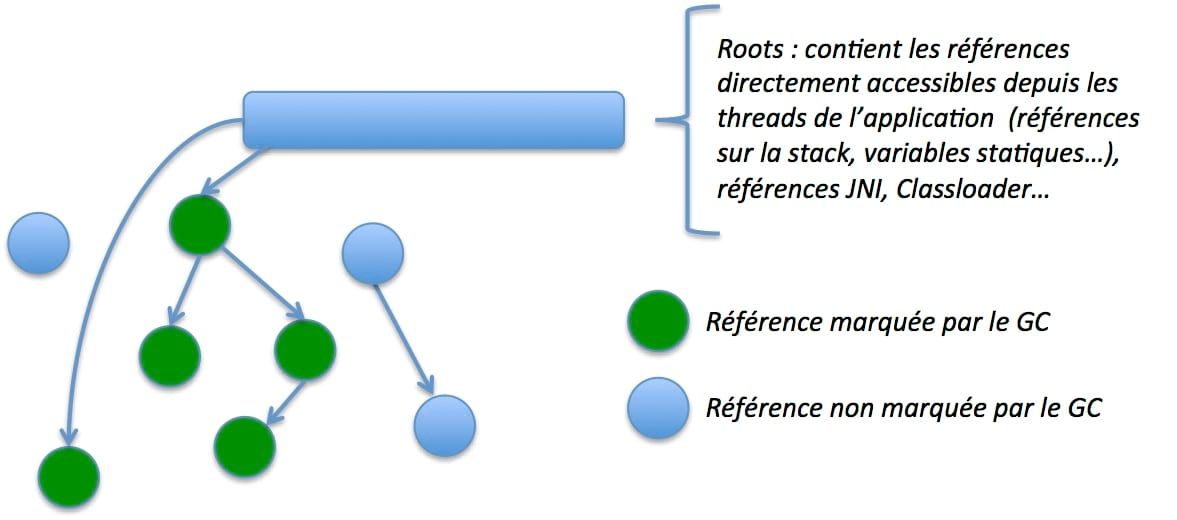
Les threads de l'application pointent vers ces objets survivants au travers des "roots". Les roots sont des structures de données (qui sont dans la stack locale du thread : références à des variables locales, membres statiques d'autres classes...) directement accessible depuis les threads JVM de l'application.
Les threads accèdent à l'objet survivant au travers de son adresse contenue dans sa référence. Lors du changement de génération (ou lors de tout déplacement de page comme lors d'une compaction), les threads qui accèdent à l'adresse avant la modification de référence peuvent subir des dangling pointers (pointeurs sur un espace mémoire invalide).
Pour éviter ces accès invalides, l'accès à la référence doit être verouillée lors du déplacement mémoire de l'objet (que l'on peut apparenté à un verrou en base de données).
lock (objet.verrou) {
deplacerObjetEnMemoireVirtuelle(objet, adresse_cible);
mettreAJourLaReferenceDeLObjet(reference, adresse_cible);
}
Les threads sont donc stoppés pendant le changement de page mémoire. On appelle cela une pause. Un stop-the-world est une pause de tous les threads de l'application par une sorte de verrou global. Cela arrive lors d'opérations de déplacement massif d'objets (lorsque les Survivors ou le Tenured sont pleins).
Il existe d'autres points où les threads sont stoppés par la JVM (safepoints), mais cet article n'aborde uniquement que la problématique du GC.
Pour plus de détails je vous conseille l'article de Martin Thompson qui explique de manière claire ces pauses et les algorithmes CMS (Concurrent Mark-Sweep) et G1 (Garbage First).
Est-ce grave ?
Les applications ayant de fortes contraintes de faible latence subissent ces pauses. Prenons le cas d'applications de trading électronique dont les ordres passent par un moteur de risque. Lorsque le risque encouru sur une contrepartie dépasse une limite fixée, les ordres ne sont plus exécutés. Les ordres liés à une contrepartie peuvent provenir de plusieurs systèmes différents. Ainsi pour un ordre donné, la limite doit être calculée par rapport aux données provenant d'autres systèmes. Si un blocage intervient lors de la récupération des données client, il est possible de rater des données plus fraîches et donc de mettre en péril le business.
Les pauses du Garbage Collector peuvent donc avoir un impact fort sur le métier dans des environnements à faible latence.
C'est également le cas pour des applications type cache de données où le GC introduit des limitations de taille de heap. Ces limitations de taille, même sur système d'exploitation 64 bits, viennent de ces pauses.
Les temps de Stop-The-World sont proportionnels au nombre d'objets du Tenured (Old Generation) et au nombre d'objets en faible durée de vie (Eden et Survivors). Ainsi plus la heap est large, plus les temps de Stop-The-World sont importants. Sur des applications n'ayant pas besoin de faible latence les impacts peuvent tout de même se ressentir avec des temps de pause atteignant l'ordre de la minute sur des heap de plusieurs dizaines de GB.
C'est pour cela qu'il n'est pas commun d'observer des heaps dépassant les 64GB voire même 32GB de RAM.
Zing, une JVM sans pauses
Zing est une JVM développée par la société Californienne Azul. Livrée avec une appliance à l'origine (processeur Vega), cette JVM est désormais compatible x86 pour les systèmes d'exploitation Linux et Solaris.
La caractéristique de cette JVM est qu'elle n'engendre aucune pause. Les threads du GC de Zing sont entièrement concurrents à l'application hébergée sur la JVM et aucun safepoint lié au GC (point d'arrêt de threads pour modifier les adresses mémoires virtuelles des références) n'est nécessaire.
La heap est toujours organisée en générations mais les déplacements d'objets des Survivors au Tenured sont fait en concurrence avec l'application. La compaction, en Young et Old Generation, est également concurrente avec l'application.
De plus, C4 permet également le compactage de la heap pour éviter toute fragmentation engendrée par d'autres algorithmes comme CMS. Dans CMS la Old Generation est collectée de manière concurrente. Pour qu'il n'y ait aucune pause dans la collecte de la Old Generation (qui, en général, est plus large que la Young donc plus longue à traiter par le GC) les références ne sont pas compactées, c'est-à-dire que les objets référencés ne sont pas dans un espace contigu de la mémoire.
Pour être concurrent, CMS doit être exécuté en même temps que les threads de l'application. Cependant pour compacter la mémoire, les objets doivent être regroupés (défragmentation de la mémoire) en continu, c'est-à-dire pendant l'exécution de l'application.
Or, le déplacement des objets entraîne la modification de son adresse dans la mémoire virtuelle qui est stockée par la référence détenue par l'application. Il faut donc mettre à jour l'adresse de la référence pour que l'application récupère l'objet ayant été déplacé. Si l'objet est déplacé et que la référence n'est pas mise à jour, une page fault intervient. Pour mettre à jour la référence et empêcher les "page fault" il faut donc stopper les threads de l'application, mettre à jour les références et relancer l'application. CMS est donc concurrent sans phase de compaction.
La mémoire devient donc fragmentée au fur et à mesure et lorsqu'il n'y a plus d'espace contigu suffisant pour accueillir les objets provenant de la Young Generation (car les objets de la Young Generation sont déplacés vers la Old Generation par blocs contigus) un full-GC est lancé provoquant une pause des threads de l'application.
Nous allons voir dans la suite de cet article que, contrairement à CMS et G1, Zing permet d'être sans pauses grâce à son GC concurrent.
LVB : Loaded Value Barrier & Self Healing
La concurrence entre l'application et le GC est assurée au travers d'une barrière mémoire. Cette barrière est une barrière en lecture, correspondant à du code injecté par le compilateur JIT lorsqu'une référence est chargée par l'application.
Lorsqu'un accès à une référence est exécuté depuis le code (exemple : int a = intObject.getValue()) la barrière est exécutée et teste les invariants suivants :
- Les références (pointeurs) doivent être marqués comme étant visités par le GC : ainsi toute référence remplissant cet invariant signifie qu'elle devrait être dans un état stable, le GC ayant traité l'objet pointé par la référence.
- La référence ne pointe pas vers un objet déplacé : l'objet a été déplacé et la référence n'est plus à jour.
Si aucun de ces deux invariants n'est vérifié, la barrière déclenche une opération de "self-healing", réparation des références, exécutée de manière atomique.
Le pseudo-code JAVA ci-dessous décrit le mécanisme de la LVB :
public class Reference {
boolean BitNMT;
int NumeroPage;
int IdGeneration;
}
public void executeLVB(long adresse, Reference val) {
int trigger = 0;
if (val.BitNMT != VAL_ATTENDUE[val.IdGeneration])
trigger |= NMT_TRIGGER;
if (estProtegee(val.NumeroPage))
trigger |= RELOC_TRIGGER;
if (trigger != 0)
reparationReference(adresse, val, trigger);
}
public void reparationReference(long adresse, Reference val, int trigger) {
Reference oldRef = val.clone();
if (trigger | NMT_TRIGGER) {
val.BitNMT = !val.BitNMT;
MettreReferenceEnQueueDuMarker(val);
}
if (trigger | RELOC_TRIGGER) {
relocaliserObjet(val);
val = RecupererNouvelleReferenceObjet(val);
}
AtomicCompareAndSwap(adresse, oldVal, val);
return val;
}
Nous pouvons voir le test des deux invariants grâce à ce pseudo-code. La LVB est exécutée à chaque lecture de référence. Le bit NMT (définition dans la description de l'algorithme) permet de définir l'ID du cycle GC courant. Si l'ID du cycle stocké en référence est différent de l'ID du cycle courant, le GC n'a pas encore traité la référence : le premier invariant est cassé et la référence est mise en queue de traitement du GC.
Si la page mémoire contenant l'objet pointé est protégée, l'objet (ou un autre stocké dans la page) est en train d'être déplacé en mémoire : le deuxième invariant est cassé et l'adresse de la référence est mise à jour.
Contrairement aux mécanismes de barrière en write, la LVB (read-barrier) a accès non seulement à la valeur de la référence mais également à l'adresse mémoire contenant cette valeur. Ainsi si la référence doit être corrigée, donc la valeur déplacée en mémoire, l'emplacement mémoire d'origine contenant l'adresse initiale pointe vers le nouvel emplacement. De ce fait, tous les autres objets ayant cette référence pointent automatiquement vers la nouvelle adresse (indirection).
La LVB évite ainsi que la barrière soit lancée à chaque chargement de la référence, cette correction n'est faite qu'une fois ce qui impacte positivement les performances de la JVM.
L'algorithme du GC
L'algorithme de Zing dispose des avantages proposés par les deux algorithmes concurrents actuels d'HotSpot. Il est fortement concurrent avec quasiment aucune pause, tout comme CMS en mode nominal, quelque soit le nombre d'objets référencés. Tout comme G1, il permet d'éviter la fragmentation mémoire (l'un des problèmes majeurs de CMS) grâce aux phases de compactage.
L'algorithme de Zing est divisé en 3 phases :
Mark : rien de bien spécifique à Azul sur le marking, l'algorithme est repris depuis HotSpot.
La modification de cet algorithme sur Zing réside dans l'intégration d'un bit appelé NMT (Not Marked Through). Ce bit, compris dans la structure de chaque référence, a une valeur dépendant du cycle GC. Au début d'un cycle GC, toutes les références ont ce bit à la valeur attendue par le précédent cycle GC. Ainsi, la LVB s'appuie sur ce bit pour savoir si la référence courante a été modifiée par le GC (premier invariant). De la même manière que tous les algorithmes de HotSpot, le GC Zing commence par les références racines pour marquer tous les objets vivants.

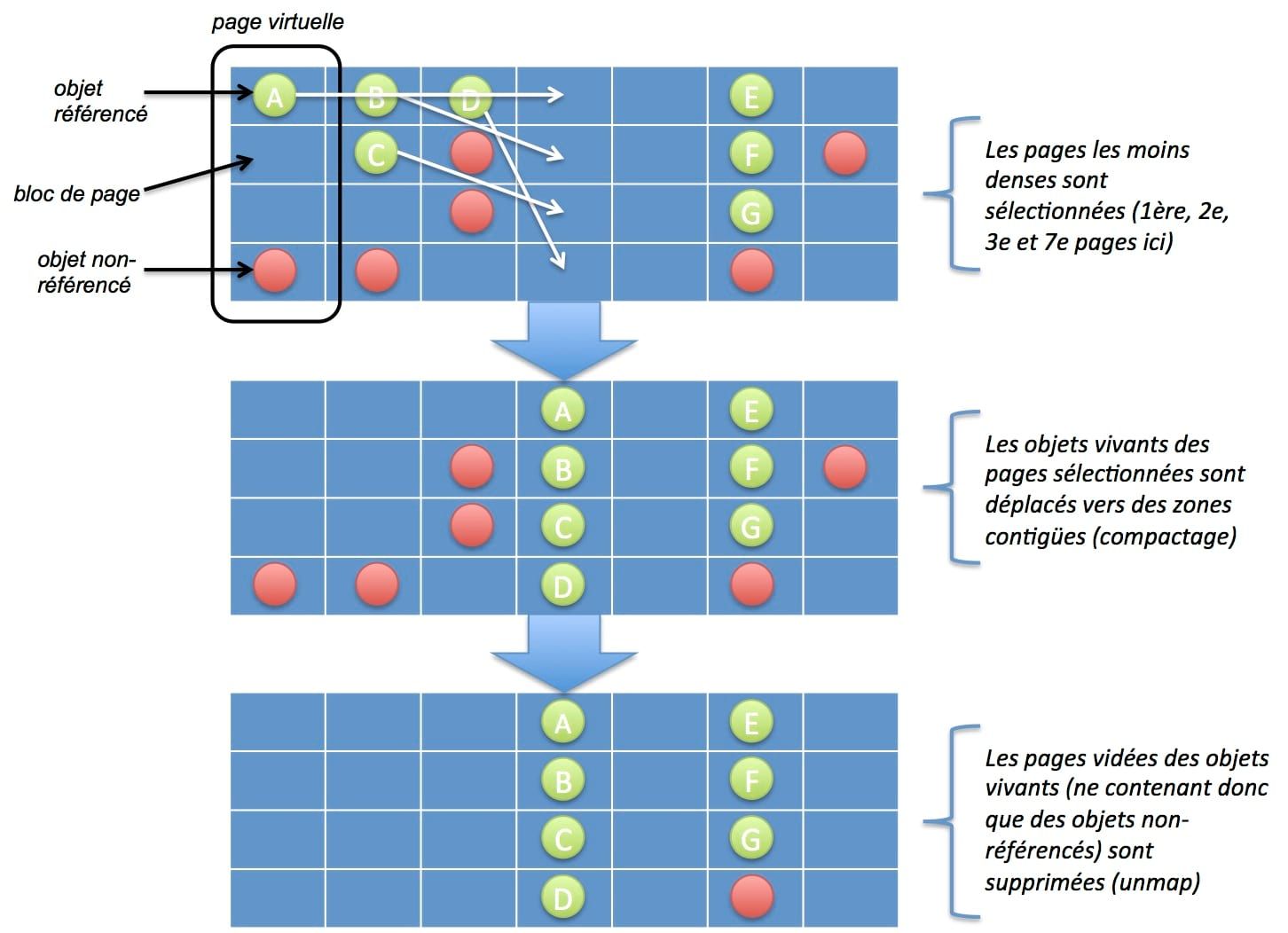
Relocate : lors de cette phase, les objets vivants sont déplacés dans des pages mémoires contiguës afin d'éviter toute fragmentation mémoire :
- Un ensemble de pages les plus fragmentées est sélectionné : comme le GC ne doit pas monopoliser les coeurs du CPU, seul un sous-ensemble est à traiter.
- Les objets vivants contenus dans ces pages sélectionnées sont copiés dans un emplacement mémoire contigu.
- La référence est "forwardée" vers ce nouvel emplacement.
- L'ancien emplacement contenant les objets morts est libéré.
Remap : à ce stade les références n'ont pas été mises à jour. Les références pointant vers des objets ayant été déplacés lors de la phase précédente sont donc caduques. Bien que le lazy remapping soit géré par la LVB, il existe néanmoins un remap effectué lors d'un cycle GC. Le remapping consiste à modifier les références de l'application dont les objets ont été déplacés pour pointer vers le nouvel emplacement mémoire.
Tuning de l'OS
Tout d'abord précisions un point important : Zing n'est disponible que sur des systèmes Linux. Il n'y a pas de version disponible pour l'OS Windows, même pour la version HPC. Le directeur technique d'Azul, Gil Tene, m'a précisé qu'il n'y avait pas de plan à court terme pour le support de Zing sur ce système d'exploitation. Les raisons viennent des améliorations apportées ci-dessous qui n'ont pas été portées. Il n'a pas été testé également sur OSX.
Dans des cas de haut débit d'allocation, le remapping a un impact sur le système d'exploitation. Zing utilise la commande mremap Linux permettant de modifier le mapping entre page virtuelle et mémoire physique. Lors de l'allocation d'un objet un mapping est effectué (mmap) afin de stocker cet objet dans la mémoire virtuelle servant pour la heap de la JVM. Ensuite, le GC "remappe" (déplace) et "unmappe" (libère) ces pages dans l'algorithme défini dans la partie précédente. Ainsi, plus le taux d'allocation est élevé, plus l'opération mremap est sollicitée.
Linux pose des limitations de performance sur le remapping principalement lié à l'utilisation de plusieurs threads concurrents :
- Le remapping impose une invalidation des caches mémoire (TLB) provoquant des interruptions CPU.
- Seules des pages de 4KB peuvent être remappées, augmentant le nombre d'opérations.
- Les opérations de remap au sein d'un process s'exécutent sur un seul thread, ce qui impose d'acquérir un write-lock au niveau kernel.
Pour contrer ces limitations, Azul a développé son propre système de mémoire virtuelle. Ces modifications de l'OS sont nécessaires puisque Zing est principalement utile pour des contextes d'allocations élevées. Ces contextes sont les plus propices aux lenteurs de GC.
Est-ce vraiment utile ?
Les cas d'utilisation de Zing sont très restreints. Cette JVM s'adresse aux applications ayant de fortes problématiques de latence : cette latence doit être déterministe, c'est-à-dire qu'aucun traitement ne doit subir de latence donc de pause.
Pour de la faible latence ?
Etant dans la cible d'utilisation de Zing, la première question à se poser est : peut-on faire sans ? Pour des besoins de performance il peut être judicieux de s'affranchir des contraintes liées à l'utilisation d'une machine virtuelle (langages C/C++). Ces besoins étant très ciblés, le crédo de portabilité "write once run everywhere" ne pèse pas lourd dans la balance. De plus, les optimisations du JIT trouvent leurs équivalents sur les différents compilateurs C/C++. Il existe néanmoins trois arguments pouvant favoriser l'utilisation de Java : les compétences disponibles sur le marché, la reprise de code existant et la complexité d'écriture de code sans GC en gérant manuellement les allocations mémoire.
Ce dernier point est abordé par Cliff Click d'Azul en prenant l'exemple d'algorithmes concurrents :
Many concurrent algorithms are very easy to write with a GC and totally hard (to down right impossible) using explicit free.
Est-il possible de faire sans Zing en Java ? Il existe plusieurs techniques pour ne pas subir les contraintes de latence du Garbage Collector : utiliser des structures de données off-heap (comme les DirectByteBuffer) ou rendre son code "GC-friendly" en réutilisant des objets ou structures de données afin quelles ne soient pas compactées ainsi qu'en dimensionnant les espaces de la Young Generation suffisamment large pour que les objets puissent y mourir sans être déversés dans la Old Generation, donc sans qu'il n'y ait de stop-the-world (qui arrive lorsque les objets passent de la Young à la Old Generation). Ces techniques impliquent une connaissance pointue du fonctionnement interne de la JVM et du GC à acquérir pour les développeurs, ce que Martin Thompson appelle "mechanical sympathy". Cette connaissance n'est que peu répandue car peu souvent nécessaire au quotidien.
Pour un large cache mono-instance ?
Zing permet d'utiliser des tailles de heap supérieures à 100GB sans interruption de service, pouvant atteindre quelques minutes sur HotSpot à cause de potentiels Full GC. Cette perspective est intéressante seulement si elle n'induit pas d'autres goulets d'étranglements comme la surcharge CPU liée à une forte contention des threads. Zing utilise fortement les ressources CPU en continu pour le travail du GC.
En supposant une utilisation d'une heap à plus de 100GB cela signifierait que ces 100GB de données (ou moins selon l'overhead applicatif) sont régulièrement utilisés, en read ou en write, donc que plusieurs threads puissent accéder en simultané à la heap induisant une forte charge CPU. Il faut donc prévoir les ressources nécessaires pouvant supporter à la fois le travail de l'application mais également celui de Zing. Si la latence n'est pas un enjeu critique, une approche multi-noeud avec des machines commodity, possible via l'utilisation de caches distribués comme Couchbase ou de grilles de données comme GemFire, serait plus optimale d'un point de vue scalabilité (scalabilité verticale du CPU versus scalabilité horizontale).
Dans le cas contraire, ces 100GB contiendraient des données rarement exploités et une utilisation "lazy" - chargement à la demande - se révèlerait plus optimisée en terme de ressources matérielles et d'exploitation.
Cependant, pour des besoins de faible latence avec un fort volume de donnée Zing se révèle intéressant. Mike McCandless donne un exemple avec une indexation de Wikipedia par Lucene (index de 78GB) : Lucene index in RAM with Azul's Zing JVM
Pour des applications web marchandes hautement disponibles
Le modèle économique de ces sites web est basé sur le nombre d'utilisateurs. Dans un environnement fortement concurrentiel, tout utilisateur mécontent du service rendu par un site change pour son concurrent. Ainsi, le SLA (latence, disponibilité) devient un enjeu économique. Les pauses de GC peuvent ainsi entraîner une perte de clients : un site indisponible à de nombreuses reprises donne une mauvaise image. De plus, les pauses de GC étant indéterministes, il est pratiquement impossible d'imaginer un système de contournement lors de pauses GC (par exemple une redirection de session vers une autre JVM disponible).
Pour analyser les temps de latence sur la JVM en production, Azul propose un outil : jHiccup.
Conclusion
Cette JVM se révèle donc très utile pour des contextes d'optimisation d'existant pour des besoins de faible latence ou de haute disponibilité sans surcoût de développement tout en gardant à l'esprit les contraintes liées au paramétrage du système d'information (d'autant plus que Zing n'est pas disponible pour Windows) : bus de prix haute fréquence, référentiel de données en mémoire utilisé pour des activités de trading, calcul de risque "temps réel"...
Pour un test il est possible d'avoir une version d'essai sur le site d'Azul.