Services et tests d'intégration : ce qu'il faut savoir pour que ça se passe bien
Des points d'attention et des suggestions pour améliorer les choses
De quoi parle-t-on ?
Si votre système d’information comprend des échanges entre applications, que cela soit sous forme de services, de messages ou de fichiers, il est probable que vous testiez ces dépendances à l’aide de tests d’intégration. Ils permettent de valider les interactions entres composants en conditions réelles.
Ces tests sont souvent source de tensions entre projets : aux difficultés inhérentes aux bugs d’intégration (de quel côté se situe le problème ?) s’ajoutent les contraintes de calendrier et d’indisponibilité. Ce n’est pas une fatalité, si les tests d’intégrations sont toujours un point d’attention, les opérations peuvent bien se passer.
Dans certaines entreprises, le cycle de vie des projets comprend parfois un environnement d’intégration pour tester la tuyauterie technique et un environnement de recette pour tester les comportements métier. Dans ce cas, ce qui est décrit dans l’article s’applique à ces deux environnements.
L’objectif de cet article est de vous aider à ce que ces situations complexes se passent le mieux possible en vous indiquant les points d’attention à surveiller et les antipatterns à éviter. Nous parlerons gouvernance, puis données, pour terminer sur le déploiement des applications.
Gouvernance
Les tests d’intégration constituent l’étape où l’on commence à assembler les briques applicatives unitaires pour construire un SI. On passe donc du chacun pour soi à un système commun.
Chaque application a tendance à se concentrer sur ses propres besoins tout en négligeant ceux des autres : elle se voit seule au monde à faire ses tests et les autres applications sont à son service, sans prendre en compte que, pour les autres, la situation est exactement la même. Il est donc normal que des problèmes de gouvernance se posent, et que des arbitrages soient nécessaires pour l’intérêt commun.
Les services doivent être testés unitairement
Si, dans le cycle projet, les tests d’intégrations sont le premier moment où on teste les services en mode connecté, cela ne doit être le premier moment où les projets testent leurs services.
Comme le reste du code, les services doivent être couverts par des tests unitaires, par exemple en utilisant des mocks.
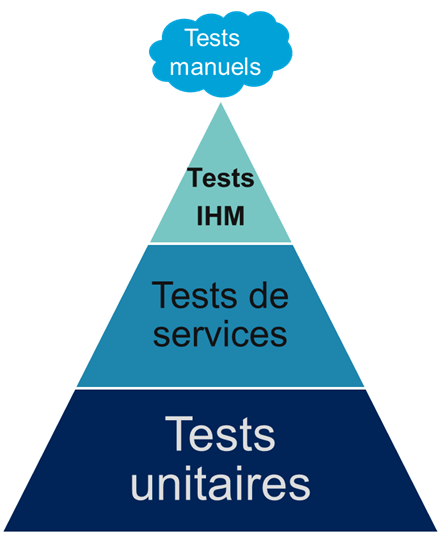
Les tests d’intégrations sont en plus des tests unitaires.
Si une équipe ne fait pas ces tests unitaires, elle va se retrouver avec un tas de bugs pendant la phase d’intégration. Cela représente un gaspillage, car faire des corrections pendant l’intégration prend plus de temps que pendant le développement. Gaspillage de temps également pour les équipent qui dépendent de ce code et qui seront donc ralenties dans leurs propres tests d’intégration.
De plus, si elle dépense son temps de tests sur les cas qui auraient du être vérifiés plus tôt, elle risque de passer à côté des erreurs moins évidentes, qui seront donc découvertes après la mise en production.
Le rôle de la gouvernance est donc de rendre les tests unitaires obligatoires sur les services, et de faire en sorte que cette règle soit appliquée.
Garantir une qualité de service
Pour que les équipes ne soient pas bloquées pendant les tests d’intégration, il faut que les applications soient accessibles en permanence.
Pour cela il est possible de mettre en place une garantie de service (SLA), un peu comme en production. Il ne s’agit pas de dire que les environnements d’intégration sont aussi critiques que la production, mais d’acter que les interruptions de service en intégration sont suffisamment dommageables pour qu’elles soient traitées avec l’urgence nécessaire, sans qu’il y ait besoin pour cela d’avoir à argumenter ou escalader.
Astuce : On peut ainsi, sous réserve des questions de license, utiliser les mêmes outils de monitoring et d’alerting qu’en production, ce qui permet de les tester en même temps que le reste des applications.
Toute interruption de service pour maintenance doit alors être communiquée et validée, donc plus question de décider qu’une application sera indisponible pendant une semaine le temps de tester une mise à jour ou un nouvel outil.
La garantie s’étend bien entendu aux différents middleware (sécurité, intégration … ) : on arrête de faire des tests "unitaires" en environnement d’intégration, ou de ne faire que des tests d’intégration au risque de bloquer tous les autres. Chaque brique, même non applicative, doit avoir son propre environnement de test "unitaire" et ses jeux de tests validant le maximum de choses de manière indépendante.
La manière de mettre en œuvre ce SLA dépend de la manière dont vos applications sont déployées, comme on va le voir plus bas.
Aider aux investigations
Pendant les tests d’intégration, on rencontre régulièrement des problèmes à la frontière entre les applications, qui peuvent être difficiles à diagnostiquer.
Pendant la phase d’investigation, on ne sait pas forcément quelle est la source du bug et on peut ainsi avoir besoin de l’aide de n’importe quelle équipe, sans être certain que le problème vienne de son côté.
Quand une bonne entente règne entre les équipes, chacune fournit son aide sans trop se faire tirer l’oreille. À l’inverse, quand la situation est plus tendue, par exemple quand chaque équipe est n’objectivée que sur l’avancement de son propre code plutôt que sa contribution globale, les équipes aideront moins volontiers les autres.
Cela se matérialise par le fait de faire traîner les choses en espérant que ça se tasse, et/ou de demander des preuves que le problème vient de leur côté. Cette attitude ralentit tout le système tout en créant de la frustration, et à long terme, elle peut entraîner la création d’un cercle vicieux.
Une bonne gouvernance fera donc en sorte que les projets soient bien disposés à participer aux efforts d’investigation communs. Il faut accepter que ces tâches prennent du temps, temps qui donc être correctement budgété.
Astuce : Si une équipe se plaint de passer trop de temps à aider aux investigations, c’est souvent le signe qu’elle est sous-effectif ou qu’elle n’investit pas assez dans les outils (monitoring et log) qui la rendraient plus efficace ou de permettraient aux autres d’êtres autonomes. Ces mêmes outils serviront ensuite pour aider à diagnostiquer des problèmes en production, cet investissement est donc rentable.
Prioriser les corrections d’erreur
Une fois une investigation terminée et une erreur identifiée, reste à la corriger.
Parfois pendant les tests d’intégration, une équipe détecte un problème dans un service qu’elle appelle et qui est déjà déployé, et ce bug l’empêche de passer son code en production. Toutes les équipes ont une procédure, officielle ou officieuse, pour corriger rapidement les bugs bloquant lorsqu’ils apparaissent lors des tests d’intégration. Malheureusement, cette action est souvent plus beaucoup difficile à activer lorsqu’un bug dans une application bloque quelqu’un d’autre.
Cela ne signifie pas qu’il faut utiliser systématiquement cette procédure d’urgence, mais que "est ce que ça nous gène nous ou quelqu’un d’autre ?" ne devrait pas faire partie des critères qui sont pris en compte quand il faut décider si on l’applique ou pas.
Si le problème se pose régulièrement, la moins mauvaise solution reste de donner à quelqu’un·e (une personne ou une entité) le mandat pour arbitrer ces situation pour défendre l’intérêt global. Elle devra avoir la légitimité nécessaire pour que ses décisions soient appliquées, et être disponible rapidement pour pouvoir agir dès que nécessaire.
Ne plus avoir d’équipe d’intégration
Dans le passé, lorsque l’administration système et les déploiements n’étaient pas totalement automatisés, il existait souvent des équipes d’intégration.
Ces équipes étaient chargées de s’occuper des serveurs, de faire les déploiements, et souvent d’aider aux investigations. Comme son objectif était de faire fonctionner la plateforme, elle était forcée de s’occuper des bugs dont personne ne voulait. Sans avoir de connaissance métier, et sans l’aide des développeurs concernés, son rôle était d’identifier les causes des problèmes avec une certitude suffisante pour que les projets soient obligés de s’y intéresser. Cela s’est traduit par des durées de corrections allongés et des efforts gâchés.
Ce mode de fonctionnement est très confortable pour les équipes projets car ils savent que, s’ils négligent cette partie de leur travail, quelqu’un le fera à leur place. Elle a tendance à entretenir un cercle vicieux de non implication.
Nous déconseillons ce type d’équipe. Commencez par investir dans l’automatisation des déploiements. Une fois les déploiement industrialisés, les membres de cette équipe peuvent essaimer ailleurs, notamment directement dans les projets pour aller vers du devops. Privés de filet de sécurité, les projets sont alors obligés de s’intéresser à leurs bugs.
Quelles données pour les tests d’intégration ?
Un système distribué présente des incohérences de données
Quelle que soit la manière dont vous vous y prenez, vous aurez des incohérences de données entre vos systèmes. Dès qu’un système est distribué, ce problème surgit.
Les environnements d’intégration, avec des applications en cours de test (donc avec plus de bugs) et où on bidouille beaucoup les données pour tester certains cas bizarres, sont un terreau fertile pour qu’ils apparaissent. Si on s’y prend mal, cela se traduit en cheveux arrachés et en heures perdues en investigation.
Face à cela, la meilleure stratégie consiste à accepter la complexité de la situation et à s’y confronter.
Vos systèmes doivent être robustes, ce qui ne veut pas dire bidouiller les données ou ignorer les erreurs, mais avoir un monitoring et un reporting qui les identifient rapidement, pour pouvoir les corriger.
Bonne nouvelle, cet investissement vous servira également en production, et lorsqu’un problème de données bloquera vos systèmes, vous serez bien content d’avoir pris auparavant le temps de vous outiller pour vos tests.
Quels besoins vis-à-vis des données ?
Pour faire des tests d’intégration, les données doivent répondre à trois besoins :
- des données couvrant les différents cas à tester, pour éviter d’avoir à les modifier manuellement ;
- que les données nécessaires aux tests de chaque applications soient cohérentes entre elles, car sinon il n’est pas possible de jouer les tests ;
- que les données de tests chaque applications soient indépendantes (les données fournies par l’application A et nécessaires aux tests de l’applications B sont indépendantes des données nécessaires à l’application C).
Les trois nécessitent une bonne coordination entre les applications. C’est évident pour les deuxième et troisième besoin, mais c’est aussi le cas pour le premier : par exemple si une application A gère des clients et une application B les comptes de ces clients, pouvoir tester certains cas de B peut nécessiter d’avoir des clients avec des statuts particuliers dans A.
Pour obtenir ces données, deux stratégies se distinguent :
Utiliser des données de référence
Dans cette approche, chaque application vient avec des données prédéfinies qui sont utilisées pour les tests. Elles sont appelées "données de références" car elles représentent les différents cas possibles pour jouer les tests. Elles se préparent avec les personnes du métier qui connaissent les cas à tester.
Elles peuvent prendre plusieurs formes, et pas seulement celles de données statiques :
- bases de données qu’on va recopier (solution basique mais qui rend plus difficile de versionner les données avec le code) ;
- scripts SQL ;
- données dans des fichiers de configuration (XML par exemple) ;
- code permettant d’insérer les données de manière paramétrable, éventuellement avec une API : il s’agit généralement d’une API minimaliste et distincte de l’API applicative "normale" car elle devra permettre de facilement créer des données de différents types sans avoir à manipuler d’action métier.
Pour des métiers très complexes, il peut être pertinent de développer des outils permettant d’extraire des données de la production et de les anonymiser afin d’en faire des données de référence.
Quel que soit la solution choisie, maintenir ces données présente un coût : lorsqu’on ajoute un nouveau cas, ou lorsque le format de données change, une mise à jour s’impose. Par contre, ces mêmes données peuvent servir pour les tests métiers voire pour les tests unitaires, ce qui amortit l’investissement.
Ce coût sera d’autant plus élevé que les dépendances entre application sont importantes, et que la solution choisie est basique. Ainsi, si on reprend le cas de l’application de clients A et l’application B de compte, si B a besoin d’un nouveau client dans A et que A gère ses données de référence dans une base, il faudra qu’un développeur de A insère les données dans la base. Mais si A met à disposition de B une API permettant de créer des données, B pourra le faire de manière autonome.
Cette solution est idéalement à démarrer en début de développement, quand la structure des données est assez simple et qu’on peut les faire évoluer au fur et à mesure. Si vous manquez de tests d’intégration et que vous voulez mettre en place cette solution alors que vos données sont déjà complexes, il s’agira d’un vrai chantier à préparer et à planifier.
Avec cette solution, vous êtes certain·e d’avoir les données nécessaires : elle peut sembler coûteuse mais elle est fiable.
Utiliser des données de production
L’autre approche consiste à recopier les données issues de la production.
Cette approche a l’avantage de demander peu d’investissement quand on peut s’appuyer sur les outils de sauvegarde et de rechargement déjà en place.
Elle a cependant plusieurs inconvénients :
D’abord celui, assez théorique, de la confidentialité. Assez théorique car, même si on en parle beaucoup, en pratique cette question est souvent peu prise en compte en dehors des banques et des systèmes de paiement. Les accès aux serveurs de production sont souvent limités et audités, et les accès aux serveurs d’intégration sont en général très ouverts pour pouvoir facilement et rapidement investiguer les problèmes. Copier les données de la production à l’intégration, c’est donc permettre à beaucoup de monde de le lire. Une solution possible est d’anonymiser les données, mais cela rend les choses plus complexes tout en rendant les données plus difficiles à utiliser et c’est donc rarement fait.
Ensuite il faut trouver les différentes données nécessaires aux tests. Pour des cas simples, on peut s’appuyer sur des données "connues", comme un client avec un identifiant facile à retenir, mais en prenant le risque qu’elle change. Mais pour les cas plus compliqués, cela passe souvent par un ensemble de scripts permettant de chercher un enregistrement qui a telle ou telle caractéristique. Scripts qu’il faut maintenir, et transmettre d’une équipe à l’autre.
Enfin se pose le problème des données qui n’existent pas en production, soit qu’il n’y ait aucune entrée qui corresponde, soit qu’il s’agisse d’un nouveau cas d’usage. Il faut donc prévoir de pouvoir les créer.
Au fur et à mesure que la couverture de tests s’étend, cette solution tend à demander autant de travail que d’avoir des données de référence, tout en étant plus fragile.
La réinitialisation des données
La réinialisation des données constitue le dernier point important. Quelle que soit la manière dont les données d’intégrations sont obtenues, il est nécessaire de pouvoir régulièrement remettre les données à zéro. Cela évite d’avoir des données qui se dégradent petit à petit au fur et à mesure que des tests sont joués et des erreurs détectées.
Du point de vue technique, la seule approche viable est une réinialisation automatisée. Elle évite d’avoir à passer du temps à s’assurer que tous les systèmes sont bien remis à jour en même temps, évitant ainsi les incohérences.
Du point de vue organisationnel, il faut que cette réinialisation puisse se faire régulièrement avec le minimum de tractations. Le mieux est d’avoir un processus programmé à intervalle régulier, tout en pouvant le désactiver en cas de besoin. Cela évite d’avoir à se mettre d’accord à chaque fois.
Déploiement applicatif
Une fois réglé le sujet des données, reste celui du déploiement applicatif.
Quel besoin vis-à-vis des applications ?
L’objectif est de pouvoir tester les nouvelles versions de chaque application, tout en permettant à l’ensemble des autres applications de faire de même.
Déploiement "un pour un"
Cette manière de faire standard réplique la topologie de production, avec une instance de chaque application souvent avec moins d’instances de serveurs.
Quand on veut tester une nouvelle version, on l’installe à la place de la précédente, en utilisant le même process qu’en production.
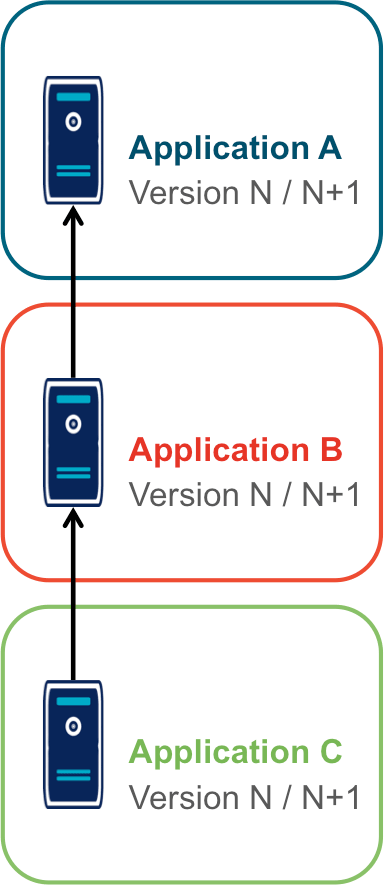
Cela permet de n’avoir aucun développement spécifique, à part un peu de configuration, mais elle a deux limites.
Tout d’abord, en cas de bug bloquant sur une application, il peut être nécessaire de revenir à la version précédente pour ne pas bloquer les autres, ce qui peut empêcher d’investiguer le problème. Ensuite, le calendrier de déploiement sur l’environnement d’intégration doit correspondre au calendrier de mise en production. Par exemple prenons deux applications A et B, B utilisant des services de A. Si la prochaine version N+1 de B doit être déployée avant la prochaine version N+1 de A, il faut attendre que les tests de la version N+1 de B soient terminés avant de déployer la version N+1 de A en recette, car sinon on risque de rater des bugs liés au fait de connecter la version N+1 de B à la version N de A.
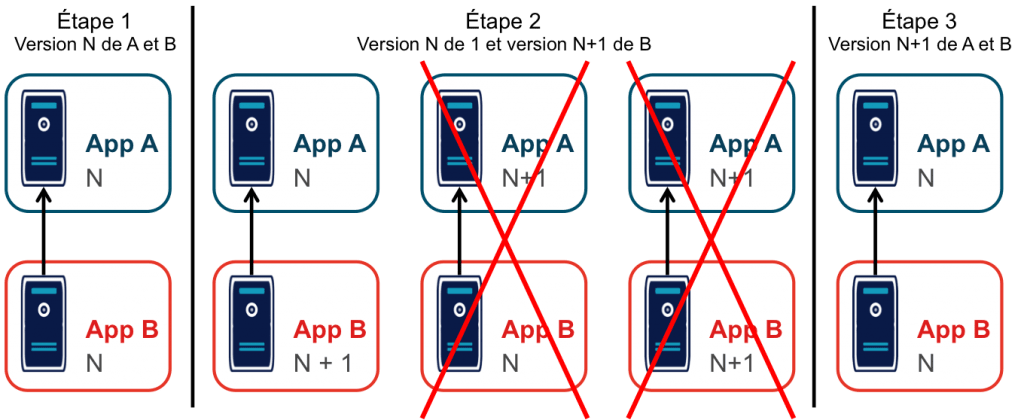
Ainsi, si le test de B prend du retard, A ne peut pas commencer ses tests, et si A veut commencer ses tests plus tôt car sa version est plus risquée, elle doit s’organiser avec B. Ce problème devenant de plus en plus complexe quand le nombre d’applications augmente.
Quand la situation devient douloureuse, la solution la plus tentante est souvent d’essayer d’augmenter le niveau de planification. Or plus on planifie, plus les situations deviennent inextricables en cas de retard. Ce cercle vicieux aboutit souvent à devoir ne pas jouer certains tests pour gagner du temps, et ainsi commencer à sacrifier la qualité.
Instances en parallèle
Il s’agit d’une manière de faire où une complexité plus grande permet d’avoir plus de liberté. Dans cette approche, chaque application dispose de deux installations : une installation en version courante, et une installation dans la version à tester.
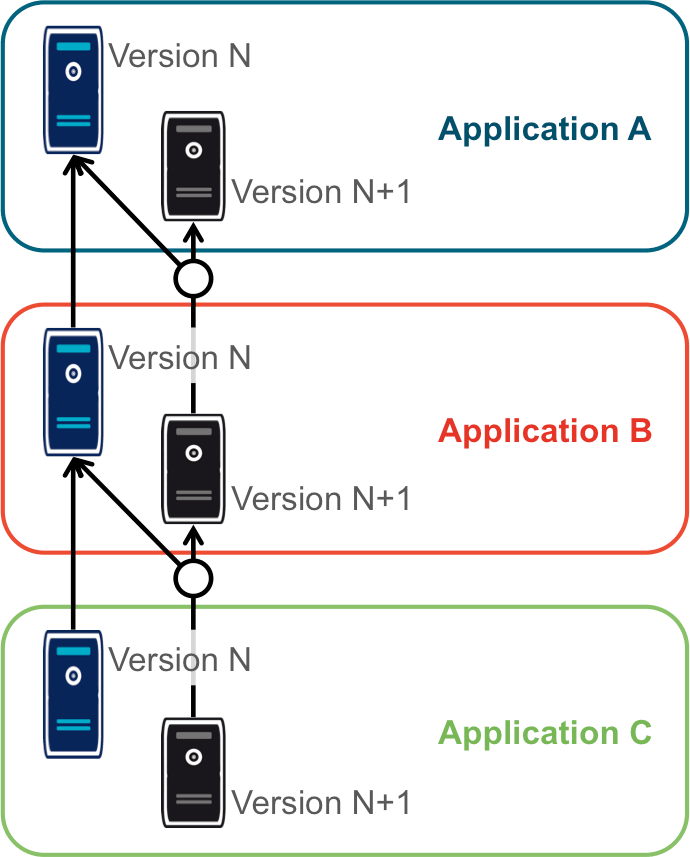
Chaque application choisit sur quelle version de service se brancher, ce qui supprime le problème de dépendance. Par exemple, la version N+1 de l’application B peut choisir d’utiliser la version N ou la version N+1 de A.
Bien entendu, cette solution nécessite d’ajouter de la configuration spécifique pour gérer les instances supplémentaires, ainsi que la configuration du routage.
Un SI d’intégration pour chaque application
L’idée ici est de fournir à chaque application un environnement d’intégration dédié avec l’ensemble des applications dont il a besoin. Ainsi, chacun est maître chez soi et peut choisir quelle version de chaque application il veut déployer. À cela ajoute l’avantage d’avoir la maitrise complète des données : chacun peut à sa guise remettre à zéro toutes les données sur son environnement sans toucher les autres.
Trois prérequis sont absolument essentiels :
- un haut niveau d’industrialisation permettant de déployer un environnement rapidement et sans intervention manuelle ;
- des ressources matérielles et logicielles (licences) disponibles ;
- un bon niveau d’observabilité et une bonne qualité de diagnostic : cela évite que les développeurs d’une application passent leur temps à investiguer les problèmes dans les environnements des autres, car en multipliant les instances, on multiplies les risques de problème.
Dans un environnement industrialisé, la mise en place de cette approche devrait être assez simple, et peut se faire un projet à la fois.
Cela revient presque à transformer chaque équipe en éditeur car ses applications sont déployées et utilisées par d’autres personnes hors de son contrôle immédiat.
Cette approche directement issue du devops semble aller dans le sens de l’histoire et va peut-être peu à peu se généraliser. Nous vous conseillons donc de vous y intéresser.
À retenir
- Chaque équipe a tendance à s’intéresser à ses besoins et à négliger ceux des autres, une bonne gouvernance permet d’en limiter les conséquences néfastes en mettant l’accent sur les objectifs communs.
- Pour obtenir des résultats il faut vous en donner les moyens.
- Une bonne stratégie de tests permet l’autonomie et l’indépendance des différentes équipes.
- Vous aurez des problèmes d’incohérence de données, mais si vous vous outillez pour bien les résoudre, vous pourrez utiliser les mêmes outils en production.
- Pour gérer les données de vos tests, vous pouvez utiliser des données de référence, ou vous appuyer sur des données de production.
- Différentes topologies de déploiement sont possibles en fonction de vos besoins, de vos moyens, et de votre capacité de coordination.